一、数据仓库
1、数据仓库定义?
关于数据仓库(Data Warehouse, DW)的定义比较常见的一种是数据仓库之父比尔·恩门在1991年出版的《建立数据仓库》一书中所提出的定义:
数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。
还有一种常见的描述是:
数据仓库是将源系统数据抽取、转化、清洗,存储到维度模型中的系统,为分析决策提供查询、分析的支持。
所以数据仓库到底是什么?看完定义描述依旧不知道 =_=||。
《数据仓库入门,看这这一篇就够了》一文中对数据仓库的解释是这样的:
数据仓库是面向分析的存储系统
也就是说数仓是存数据的,企业的各种数据往里面塞,主要目的是为了有效分析数据,后续会基于它产出供分析挖掘的数据,或者数据应用需要的数据
回过头来理解 面向主题的、集成的、相对稳定的、反映历史变化。
面向主题的——数据仓库通过一个个主题域将多个业务系统的数据加载到一起
集成的——数据仓库会将不同源数据库中的数据汇总到一起
相对稳定的——数据仓库中的数据一般仅执行查询操作,很少会有删除和更新。但是需定期加载和刷新数据。
反映历史变化——数据被加载后一般情况下将被长期保留,因此数据仓库包含来自其时间范围不同时间段的数据
这四个描述就是反应数据仓库存储数据的特点,各种来源的数据按主题长期的存储,用于分析决策。
2、数据仓库和数据库的差别是什么?
主要差别是在以下两方面:
- 实时性差异——关系数据库都是为实时查询的业务进行设计的,而数据仓库则是为海量数据做分析挖掘设计的,实时性要求不高;
- 存储能力和计算能力扩展——数据仓库在存储能力和计算能力上更好,而关系数据库在这个方面要差很多。
3、数据仓库和hive的关系?
提到数据仓库经常听到hive。hive是什么?hive和数据仓库的关系是什么?
(1)hive是什么?
Hadoop是一个能够对大量数据进行分布式处理的软件框架,Hive 是 Hadoop 中的一个重要子项目,是基于Hadoop的一个数据仓库工具(存数据的工具)
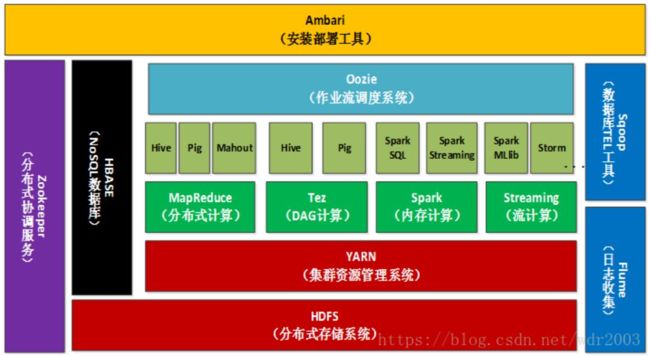
(2)Hive内部结构
CLI, WebUI为hive的用户接口;
元数据存储在mysql,主要数据存储在HDFS;
Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务,利用MapReduce 进行计算[2]
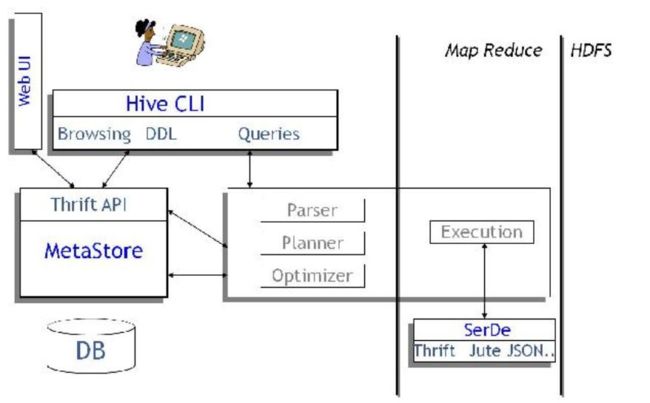
(3)数据仓库与hive关系
数据仓库比较流行的工具有:AWS Redshift, Greenplum, Hive等。
之前提到数据仓库将各种来源的数据按主题长期的存储,至于存数据用纸盒子、塑料盒子、铁盒子都是可选的,hive就是存数据的一种盒子。
二、hive的操作
在实际生产环境中已经形成了离线以Hive为主,Spark为辅, 实时处理用Flink的大数据架构体系及Impala, Es,Kylin等应用查询引擎。
以下采用Spark on Hive模式(即使用Hive作为Spark的数据源,用Spark来读取HIVE的表数据,数据仍存储在HDFS上)汇总基础sql操作。
1、创建/删除数据
(1)无中生有
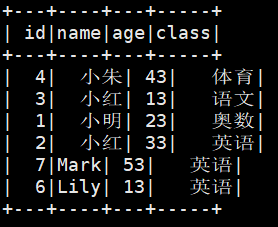
创建一个包含id,name,age,class信息的表,要求id、age为数值型,name、class为字符型。
# 表格框架
spark.sql("create table IF NOT EXISTS student(id int, name string,age int,class string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'")
# 插入行数据
spark.sql("insert into student values(1,'小明',23,'奥数')")
spark.sql("insert into student values(2,'小红',33,'英语')")
spark.sql("insert into student values(3,'小红',13,'语文')")
spark.sql("insert into student values(4,'小朱',43,'体育')")
spark.sql("insert into student values(6,'Lily',13,'英语')")
spark.sql("insert into student values(7,'Mark',53,'英语')")
# 效果查看
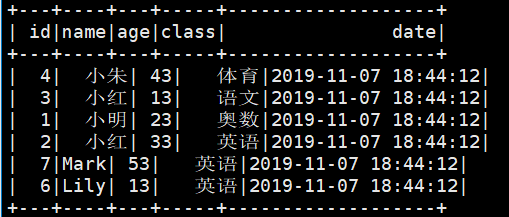
spark.sql("select * from student").show()
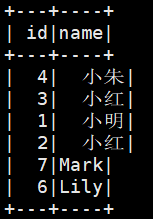
(2)查询建表
原创建表挺麻烦的,查询建表更方便一些。
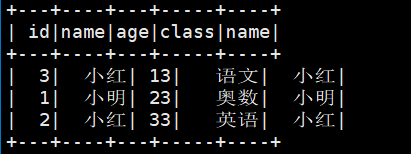
spark.sql("create table if not exists student2 select id, name from student")
spark.sql("select * from student2").show()
(2)drop 删除表格
如果不想要student2这张表,使用drop table删除。
spark.sql("drop table student2")
2、函数操作
(1)日期相关函数
想要在表格上新增一列日期信息。
unix_timestamp()为获取当前时间戳的函数(格式为:1572853933),from_unixtime函数转换时间戳为日期格式。
spark.sql("create table if not exists student2 as select *,from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss') as date from student")
spark.sql("select * from student2").show()
# 取时间范围的数据(取昨天的数据)
# Hive SQL中的[datediff(endDate, startDate)函数返回的是2个日期的天数差值
# CURRENT_DATE为当前时间
spark.sql("select CURRENT_DATE").show() # 查看当前日期
spark.sql("select * from student2 where datediff(CURRENT_DATE,date)=1").show()
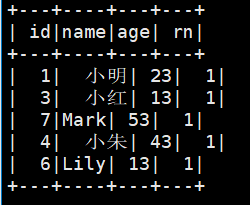
(2)row_number 数据表去重
表格有两个小红存在,想根据name对数据去重。
hive中使用row_number()对表格去重。“row_number() over (partition by name order by id desc) ” 根据name去重,根据id排序
spark.sql("select * from (select id,name,age,row_number() over (partition by name order by id desc) as rn from student) t where t.rn = 1").show()
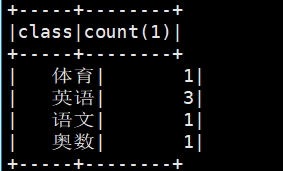
(3)group by 统计各类及数量
想要知道有多少类学科,每类学科有多少人?
spark.sql("select class,count(1) from student group by class").show()
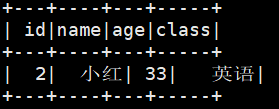
(4)and/or 多条件检索
检索name为小红,age大于30的数据信息。
spark.sql("select * from student where name='小红' and age>30").show()
(5)Concat组装新信息
Concat()将多个字符串连接成一个字符串
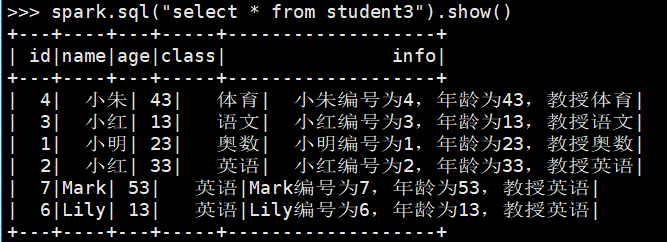
spark.sql("create table if not exists student3 as select *, concat(name,'编号为',id,',年龄为',age,',教授',class) as info from student")
spark.sql("select * from student3").show()
(6)join 黑名单匹配/过滤
已知学校存在一个黑名单库,想要只查看匹配黑名单的信息
# 先创建黑名单
spark.sql("create table IF NOT EXISTS blackStudent(name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'")
spark.sql("select * from blackStudent").show()
spark.sql("insert into blackStudent values('小明')")
spark.sql("insert into blackStudent values('小红')")
spark.sql("insert into blackStudent values('王菲')")
spark.sql("insert into blackStudent values('江山')")
spark.sql("insert into blackStudent values('肖战')")
spark.sql("insert into blackStudent values('王一博')")
# 匹配黑名单,inner join取两张表的合并部分
spark.sql("select * from student inner join blackStudent on student.name=blackStudent.name").show()
想要过滤黑名单的成员信息然后存储成一张新表
# left outer join 以左表 student为核心做匹配,去未匹配成功(null)的信息
spark.sql("create table student4 select id, student.name,age,class from student left outer join blackStudent on student.name=blackStudent.name where blackStudent.name is null")
spark.sql("select * from student4").show()

4、udf
UDF(user-defined function),当hive自带的函数无法满足数据预处理,支持自建函数。
def mymodel(age):
if age>20:
result=0
else:
result=1
return result
from pyspark.sql.types import IntegerType
spark.udf.register('mymodel',mymodel,IntegerType()) # 函数返回值类型为integer
spark.sql("select * from student3 where mymodel(age)>0").show()

三、大规模数据处理
Spark 是专为大规模数据处理而设计的快速通用的计算引擎,传统基于本地python计算的模式在面对大规模数据量时性能和时间都无法保障,基于spark的机器学习很重要哦。
参考资料
[1] 数据仓库入门,看这这一篇就够了:https://zhuanlan.zhihu.com/p/39611221
[2] hive简介:https://www.shiyanlou.com/courses/reports/1385266/
[3] Spark是否能替代Hive:https://blog.csdn.net/ys_230014/article/details/83210800