前言
作为一个Java开发者,对技术的追求而不仅仅停留在会用API,会写基本功能上,要想在技术上有更高的造诣,就需要深入到原理层面去认识代码运行的机制。因此,本文从class字节码文件的结构入手,一步步来解剖二进制字节码的内部工作原理,这对深入理解JVM的运行机制大有裨益,同时,对于想要使用BCEL来动态改变Class字节码指令的工作也很有帮助(示例:JVM Class字节码之三-使用BCEL改变类属性)。
什么是Class文件
Java字节码类文件(.class)是Java编译器编译Java源文件(.java)产生的“目标文件”。它是一种8位字节的二进制流文件, 各个数据项按顺序紧密的从前向后排列, 相邻的项之间没有间隙, 这样可以使得class文件非常紧凑, 体积轻巧, 可以被JVM快速的加载至内存, 并且占据较少的内存空间(方便于网络的传输)。
Java源文件在被Java编译器编译之后, 每个类(或者接口)都单独占据一个class文件, 并且类中的所有信息都会在class文件中有相应的描述, 由于class文件很灵活, 它甚至比Java源文件有着更强的描述能力。
class文件中的信息是一项一项排列的, 每项数据都有它的固定长度, 有的占一个字节, 有的占两个字节, 还有的占四个字节或8个字节, 数据项的不同长度分别用u1, u2, u4, u8表示, 分别表示一种数据项在class文件中占据一个字节, 两个字节, 4个字节和8个字节。 可以把u1, u2, u3, u4看做class文件数据项的“类型” 。
Class文件的结构
一个典型的class文件分为:MagicNumber,Version,Constant_pool,Access_flag,This_class,Super_class,Interfaces,Fields,Methods 和Attributes这十个部分,用一个数据结构可以表示如下:
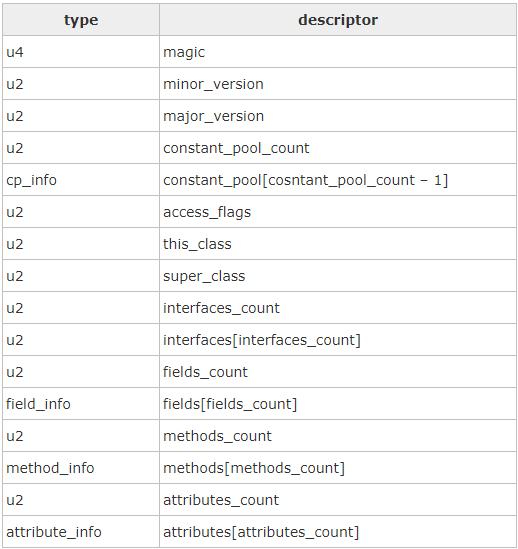
下面对class文件中的每一项进行详细的解释:
1、magic
在class文件开头的四个字节, 存放着class文件的魔数, 这个魔数是class文件的标志,他是一个固定的值: 0XCAFEBABE 。 也就是说他是判断一个文件是不是class格式的文件的标准, 如果开头四个字节不是0XCAFEBABE, 那么就说明它不是class文件, 不能被JVM识别。
2、minor_version 和 major_version
紧接着魔数的四个字节是class文件的此版本号和主版本号。
随着Java的发展, class文件的格式也会做相应的变动。 版本号标志着class文件在什么时候, 加入或改变了哪些特性。 举例来说, 不同版本的javac编译器编译的class文件, 版本号可能不同, 而不同版本的JVM能识别的class文件的版本号也可能不同, 一般情况下, 高版本的JVM能识别低版本的javac编译器编译的class文件, 而低版本的JVM不能识别高版本的javac编译器编译的class文件。 如果使用低版本的JVM执行高版本的class文件, JVM会抛出java.lang.UnsupportedClassVersionError 。具体的版本号变迁这里不再讨论, 需要的读者自行查阅资料。
3、constant_pool
在class文件中, 位于版本号后面的就是常量池相关的数据项。 常量池是class文件中的一项非常重要的数据。 常量池中存放了文字字符串, 常量值, 当前类的类名, 字段名, 方法名, 各个字段和方法的描述符, 对当前类的字段和方法的引用信息, 当前类中对其他类的引用信息等等。 常量池中几乎包含类中的所有信息的描述, class文件中的很多其他部分都是对常量池中的数据项的引用,比如后面要讲到的this_class, super_class, field_info, attribute_info等, 另外字节码指令中也存在对常量池的引用, 这个对常量池的引用当做字节码指令的一个操作数。此外,常量池中各个项也会相互引用。
常量池是一个类的结构索引,其它地方对“对象”的引用可以通过索引位置来代替,我们知道在程序中一个变量可以不断地被调用,要快速获取这个变量常用的方法就是通过索引变量。这种索引我们可以直观理解为“内存地址的虚拟”。我们把它叫静态池的意思就是说这里维护着经过编译“梳理”之后的相对固定的数据索引,它是站在整个JVM(进程)层面的共享池。
class文件中的项constant_pool_count的值为1, 说明每个类都只有一个常量池。 常量池中的数据也是一项一项的, 没有间隙的依次排放。常量池中各个数据项通过索引来访问, 有点类似与数组, 只不过常量池中的第一项的索引为1, 而不为0, 如果class文件中的其他地方引用了索引为0的常量池项, 就说明它不引用任何常量池项。class文件中的每一种数据项都有自己的类型, 相同的道理,常量池中的每一种数据项也有自己的类型。 常量池中的数据项的类型如下表:
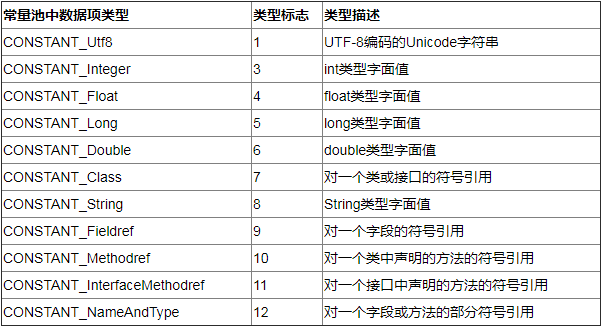
每个数据项叫做一个XXX_info项,比如,一个常量池中一个CONSTANT_Utf8类型的项,就是一个CONSTANT_Utf8_info 。除此之外, 每个info项中都有一个标志值(tag),这个标志值表明了这个常量池中的info项的类型是什么, 从上面的表格中可以看出,一个CONSTANT_Utf8_info中的tag值为1,而一个CONSTANT_Fieldref_info中的tag值为9 。
Java程序是动态链接的, 在动态链接的实现中, 常量池扮演者举足轻重的角色。 除了存放一些字面量之外, 常量池中还存放着以下几种符号引用:
(1) 类和接口的全限定名
(2) 字段的名称和描述符
(3) 方法的名称和描述符
我们有必要先了解一下class文件中的特殊字符串, 因为在常量池中, 特殊字符串大量的出现,这些特殊字符串就是上面说的全限定名和描述符。对于常量池中的特殊字符串的了解,可以参考此文档:Java class文件格式之特殊字符串_动力节点Java学院整理
4、access_flag 保存了当前类的访问权限
5、this_cass 保存了当前类的全局限定名在常量池里的索引
6、super class 保存了当前类的父类的全局限定名在常量池里的索引
7、interfaces 保存了当前类实现的接口列表,包含两部分内容:interfaces_count 和interfaces[interfaces_count]
interfaces_count 指的是当前类实现的接口数目
interfaces[] 是包含interfaces_count个接口的全局限定名的索引的数组
8、fields 保存了当前类的成员列表,包含两部分的内容:fields_count 和 fields[fields_count]
fields_count是类变量和实例变量的字段的数量总和。
fileds[]是包含字段详细信息的列表。
9、methods 保存了当前类的方法列表,包含两部分的内容:methods_count和methods[methods_count]
methods_count是该类或者接口显示定义的方法的数量。
method[]是包含方法信息的一个详细列表。
10、attributes 包含了当前类的attributes列表,包含两部分内容:attributes_count 和 attributes[attributes_count]
class文件的最后一部分是属性,它描述了该类或者接口所定义的一些属性信息。attributes_count指的是attributes列表中包含的attribute_info的数量。
属性可以出现在class文件的很多地方,而不只是出现在attributes列表里。如果是attributes表里的属性,那么它就是对整个class文件所对应的类或者接口的描述;如果出现在fileds的某一项里,那么它就是对该字段额外信息的描述;如果出现在methods的某一项里,那么它就是对该方法额外信息的描述。
通过示例代码来手动分析class文件
上面大致讲解了一下class文件的结构,这里,我们拿一个class文件做一个简单的分析,来验证上面的文件结构是否确实是如此。
我们在这里新建一个java文件,Hello.java,具体内容如下:
public class Hello{
private int test;
public int test(){
return test;
}
}
然后再通过javac命令将此java文件编译成class文件:
javac /d/class_file_test/Hello.java
编译之后的class文件十六进制结果如下所示,可以用UltraEdit等十六进制编辑器打开,得到:
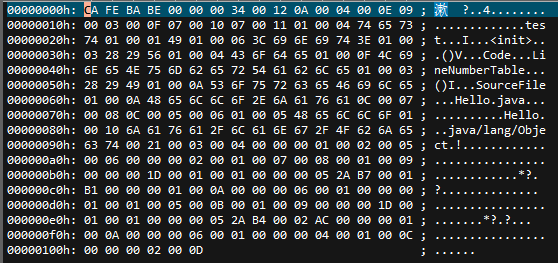
接下来我们就按照class文件的格式来分析上面的一串数字,还是按照之前的顺序来:
magic:
CA FE BA BE,代表该文件是一个字节码文件,我们平时区分文件类型都是通过后缀名来区分的,不过后缀名是可以随便修改的,所以仅靠后缀名不能真正区分一个文件的类型。区分文件类型的另个办法就是magic数字,JVM 就是通过 CA FE BA BE 来判断该文件是不是class文件-
version字段:
00 00 00 34,前两个字节00是minor_version,后两个字节0034是major_version字段,对应的十进制值为52,也就是说当前class文件的主版本号为52,次版本号为0。下表是jdk 1.6 以后对应支持的 Class 文件版本号: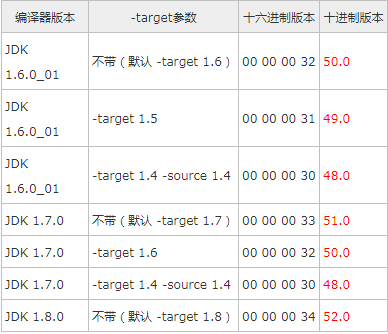 image_1c2th3nii1otd13vg1vhg1hl6itg4i.png-23.7kB
image_1c2th3nii1otd13vg1vhg1hl6itg4i.png-23.7kB -
常量池,constant_pool:
3.1.constant_pool_count
紧接着version字段下来的两个字节是:00 12代表常量池里包含的常量数目,因为字节码的常量池是从1开始计数的,这个常量池包含17个(0x0012-1)常量。3.2.constant_pool
接下来就是分析这17个常量:
3.2.1. 第一个变量 0a 00 04 00 0e
首先,紧接着constant_pool_count的第一个字节0a(tag=10)根据上面的表格(文中第二张图片)
![image_1c2tj6ib6pslkbb1876ot81rjj4v.png-4kB][7]
可知,这表示的是一个CONSTANT_Methodref。CONSTANT_Methodref的结构如下:
CONSTANT_Methodref_info {
u1 tag; //u1表示占一个字节
u2 class_index; //u2表示占两个字节
u2 name_and_type_index; //u2表示占两个字节
}
其中class_index表示该方法所属的类在常量池里的索引,name_and_type_index表示该方法的名称和类型的索引。常量池里的变量的索引从1开始。
那么这个methodref结构的数据如下:
0a //tag 10表示这是一个CONSTANT_Methodref_info结构
00 04 //class_index 指向常量池中第4个常量所表示的类
00 0e //name_and_type_index 指向常量池中第14个常量所表示的方法
3.2.2. 第二个变量09 00 03 00 0F
接着是第二个常量,它的tag是09,根据上面的表格可知,这表示的是一个CONSTANT_Fieldref的结构,它的结构如下:
CONSTANT_Fieldref_info {
u1 tag;
u2 class_index;
u2 name_and_type_index;
}
和上面的变量基本一致。
09 //tag
00 03 //指向常量池中第3个常量所表示的类
00 0f //指向常量池中第15个常量所表示的变量
3.2.3. 第三个变量 07 00 10
tag为07表示是一个CONSTANT_Class变量,这个变量的结构如下:
CONSTANT_Class_info {
u1 tag;
u2 name_index;
}
除了tag字段以外,还有一个name_index的值为00 10,即是指向常量池中第16个常量所表示的Class名称。
3.2.4. 第四个变量07 00 11
同上,也是一个CONSTANT_Class变量,不过,指向的是第17个常量所表示的Class名称。
3.2.5. 第五个变量 01 00 04 74 65 73 74
tag为1,表示这是一个CONSTANT_Utf8结构,这种结构用UTF-8的一种变体来表示字符串,结构如下所示:
CONSTANT_Utf8_info {
u1 tag;
u2 length;
u1 bytes[length];
}
其中length表示该字符串的字节数,bytes字段包含该字符串的二进制表示。
01 //tag 1表示这是一个CONSTANT_Utf8结构
00 04 //表示这个字符串的长度是4字节,也就是后面的四个字节74 65 73 74
74 65 73 74 //通过ASCII码表转换后,表示的是字符串“test”
接下来的8个变量都是字符串,这里就不具体分析了。
3.2.6. 第十四个常量 0c 00 07 00 08
tag为0c,表示这是一个CONSTANT_NameAndType结构,这个结构用来描述一个方法或者成员变量。具体结构如下:
CONSTANT_NameAndType_info {
u1 tag;
u2 name_index;
u2 descriptor_index;
}
name_index表示的是该变量或者方法的名称,这里的值是0007,表示指向第7个常量,即是
descriptor_index指向该方法的描述符的引用,这里的值是0008,表示指向第8个常量,即是()V,由前面描述符的语法可知,这个方法是一个无参的,返回值为void的方法。
综合两个字段,可以推出这个方法是void 。也即是指向这个NameAndType结构的Methodref的方法名为void ,也就是说第一个常量表示的是void 方法,这个方法其实就是此类的默认构造方法。
3.2.7. 第十五个常量也是一个CONSTANT_NameAndType,表示的方法名为“int test()”,第2个常量引用了这个NameAndType,所以第二个常量表示的是“int test()”方法。
3.2.8. 第16和17个常量也是字符串,可以按照前面的方法分析。
3.3. 完整的常量池
最后,通过以上分析,完整的常量池如下:
00 12 常量池的数目 18-1=17
0a 00 04 00 0e 方法:java.lang.Ojbect void ()
09 00 03 00 0f 方法 :Hello int test()
07 00 10 字符串:Hello
07 00 11 字符串:java.lang.Ojbect
01 00 04 74 65 73 74 字符串:test
01 00 01 49 字符串:I
01 00 06 3c 69 6e 69 74 3e 字符串:
01 00 03 28 29 56 字符串:()V
01 00 04 43 6f 64 65 字符串:Code
01 00 0f 4c 69 6e 65 4e 75 6d 62 65 72 54 61 62 6c 65 字符串:LineNumberTable
01 00 03 28 29 49 字符串:()I
01 00 0a 53 6f 75 72 63 65 46 69 6c 65 字符串:SourceFile
01 00 0a 48 65 6c 6c 6f 2e 6a 61 76 61 字符串:Hello.java
0c 00 07 00 08 NameAndType: ()V
0c 00 05 00 06 NameAndType:test I
01 00 05 48 65 6c 6c 6f 字符串:Hello
01 00 10 6a 61 76 61 2f 6c 61 6e 67 2f 4f 62 6a 65 63 74 字符串: java/lang/Object
通过这样分析其实非常的累,我们只是为了了解class文件的原理才来一步一步分析每一个二进制字节码。JDK提供了现成的工具可以直接解析此二进制文件,即javap工具(在JDK的bin目录下),我们通过javap命令来解析此class文件:
javap -v -p -s -sysinfo -constants /d/class_file_test/Hello.class
解析得到的结果为:
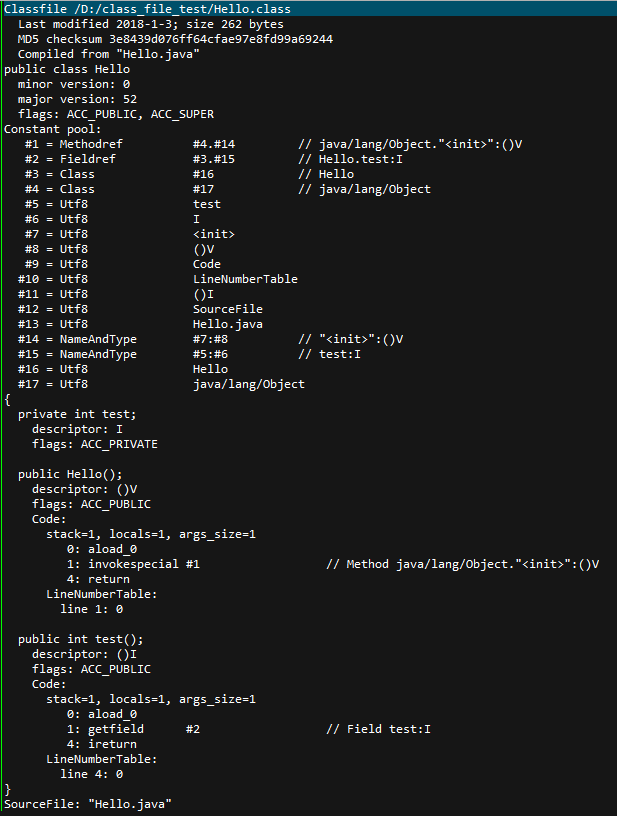
关于此表每一项的详细分析,可以参考国外的这一篇文档:JVM Internals
关于此表中Method操作指令aload_1,getfield,ireturn的作用,可以参考云溪社区的这篇文章:
JVM Class详解之二 Method字节码指令
发现了没有,上面生成代码中的Constant pool跟我们上面分析出来的完整常量池一模一样,有木有!有木有?
这说明我们上面的分析的完成正确!
由此,我们终于弄懂了Constant pool的内幕。
接下来继续看其他的字段。
- access_flag(u2)
00 21这两个字节的数据表示这个变量的访问标志位,JVM对访问标示符的规范如下:
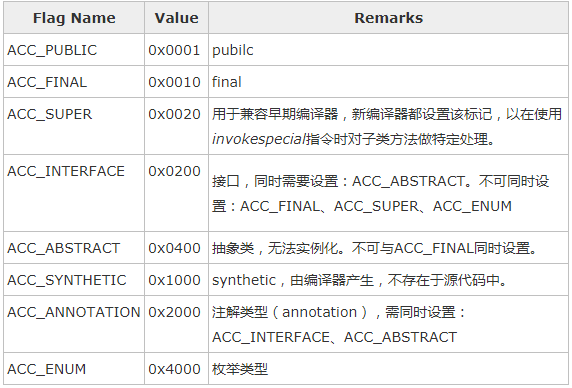
这个表里面无法直接查询到0021这个值,原因是0021=0020+0001,也就是表示当前class的access_flag是ACC_PUBLIC|ACC_SUPER。ACC_PUBLIC和代码里的public 关键字相对应。ACC_SUPER表示当用invokespecial指令来调用父类的方法时需要特殊处理。
this_class(u2)
00 03
this_class指向constant pool的索引值,该值必须是CONSTANT_Class_info类型,这里是3,即指向常量池中的第三项,即是“Hello”。super_class
00 04
super_class存的是父类的名称在常量池里的索引,这里指向第四个常量,即是“java/lang/Object”。interfaces
interfaces包含interfaces_count和interfaces[]两个字段。因为这里没有实现接口,所以就不存在interfces选项,所以这里的interfaces_count为0(0000),所以后面的内容也对应为空。fields
00 01 fields count //表示成员变量的个数,此处为1个
00 02 00 05 00 06 00 00 //成员变量的结构
每个成员变量对应一个field_info结构:
field_info {
u2 access_flags; 0002
u2 name_index; 0005
u2 descriptor_index; 0006
u2 attributes_count; 0000
attribute_info attributes[attributes_count];
}
access_flags为0002,即是ACC_PRIVATE
name_index指向常量池的第五个常量,为“test”
descriptor_index指向常量池的第6个常量为“I”
三个字段结合起来,说明这个变量是"private int test"。
接下来的是attribute字段,用来描述该变量的属性,因为这个变量没有附加属性,所以attributes_count为0,attribute_info为空。
- methods
00 02 00 01 00 07 00 08 00 01 00 09 ...
最前面的2个字节是method_count
method_count:00 02,为什么会有两个方法呢?我们明明只写了一个方法,这是因为JVM 会自动生成一个
接下来的内容是两个method_info结构:
method_info {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}
前三个字段和field_info一样,可以分析出第一个方法是“public void
00 01 ACC_PUBLIC
00 07
00 08 V()
接下来是attribute字段,也即是这个方法的附加属性,这里的attributes_count =1,也即是有一个属性。
每个属性的都是一个attribute_info结构,如下所示:
attribute_info {
u2 attribute_name_index;
u4 attribute_length;
u1 info[attribute_length];
}
JVM预定义了部分attribute,但是编译器自己也可以实现自己的attribute写入class文件里,供运行时使用。不同的attribute通过attribute_name_index来区分。JVM规范里对以下attribute进行了预定义:
这里的attribute_name_index值为0009,表示指向第9个常量,即是Code。Code Attribute的作用是保存该方法的结构如所对应的字节码,具体的结构如下所示:
Code_attribute {
u2 attribute_name_index;
u4 attribute_length;
u2 max_stack;
u2 max_locals;
u4 code_length;
u1 code[code_length];
u2 exception_table_length;
{
u2 start_pc;
u2 end_pc;
u2 handler_pc;
u2 catch_type;
} exception_table[exception_table_length];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
attribute_length表示attribute所包含的字节数,这里为0000001d,即是39个字节,不包含attribute_name_index和attribute_length字段。
max_stack表示这个方法运行的任何时刻所能达到的操作数栈的最大深度,这里是0001
max_locals表示方法执行期间创建的局部变量的数目,包含用来表示传入的参数的局部变量,这里是0001.
接下来的code_length表示该方法的所包含的字节码的字节数以及具体的指令码。
这里的字节码长度为00000005,即是后面的5个字节 2a b7 00 01 b1为对应的字节码指令的指令码。
参照下表可以将上面的指令码翻译成对应的助记符:
2a aload_0
b7 invokespecial
00 nop
01 aconst_null
b1 return
这即是该方法被调用时,虚拟机所执行的字节码
接下来是exception_table,这里存放的是处理异常的信息。
每个exception_table表项由start_pc,end_pc,handler_pc,catch_type组成。start_pc和end_pc表示在code数组中的从start_pc到end_pc处(包含start_pc,不包含end_pc)的指令抛出的异常会由这个表项来处理;handler_pc表示处理异常的代码的开始处。catch_type表示会被处理的异常类型,它指向常量池里的一个异常类。当catch_type为0时,表示处理所有的异常,这个可以用来实现finally的功能。
不过,这段代码里没有异常处理,所以exception_table_length为0000,所以我们不做分析。
接下来是该方法的附加属性,attributes_count为0001,表示有一个附加属性。
attribute_name_index为000a,指向第十个常量,为LineNumberTable。这个属性用来表示code数组中的字节码和java代码行数之间的关系。这个属性可以用来在调试的时候定位代码执行的行数。LineNumberTable的结构如下:
LineNumberTable_attribute {
u2 attribute_name_index;
u4 attribute_length;
u2 line_number_table_length;
{ u2 start_pc;
u2 line_number;
} line_number_table[line_number_table_length];
}
前面两个字段分别表示这个attribute的名称是LineNumberTable以及长度为00000006。接下来的0001表示line_number_table_length,表示line_number_table有一个表项,其中start_pc为 00 00,line_number为 00 00,表示第0行代码从code的第0个指令码开始。
后面的内容是第二个方法,具体就不再分析了。
- attributes
最后剩下的内容是attributes,这里的attributes表示整个class文件的附加属性,不过结构还是和前面的attribute保持一致。00 01表示有一个attribute。
Attribute结构如下:
SourceFile_attribute {
u2 attribute_name_index;
u4 attribute_length;
u2 sourcefile_index;
}
attribute_name_index为000c,指向第12个常量,为SourceFile,说明这个属性是Source
attribute_length为00000002
sourcefile_index为000d,表示指向常量池里的第13个常量,为Hello.java。
这个属性表明当前的class文件是从Hello.java文件编译而来。
字节码修改技术
对Java Class字节码分析,我们应该能够比较清楚的认识到整个字节码的结构。
那通过了解字节码,我们可以做些什么呢?
其实通过字节码能做很多平时我们无法完成的工作。比如,在类加载之前添加某些操作或者直接动态的生成字节。
ASM 是一个 Java 字节码操控框架。它能够以二进制形式修改已有类或者动态生成类。ASM 可以直接产生二进制 class 文件,也可以在类被加载入 Java 虚拟机之前动态改变类行为。ASM 从类文件中读入信息后,能够改变类行为,分析类信息,甚至能够根据用户要求生成新类。不过ASM在创建class字节码的过程中,操纵的级别是底层JVM的汇编指令级别,这要求ASM使用者要对class组织结构和JVM汇编指令有一定的了解。
目前字节码修改技术有ASM,javassist,cglib,BCEL等。cglib就是基于封装的Asm. Spring 就是使用cglib代理库。关于cglib的使用介绍,可以参考:CGLIB介绍与原理
Javassist是一个开源的分析、编辑和创建Java字节码的类库。是由东京工业大学的数学和计算机科学系的 Shigeru Chiba (千叶 滋)所创建的。它已加入了开放源代码JBoss 应用服务器项目,通过使用Javassist对字节码操作为JBoss实现动态AOP框架。javassist是jboss的一个子项目,其主要的优点,在于简单,而且快速。直接使用java编码的形式,而不需要了解虚拟机指令,就能动态改变类的结构,或者动态生成类。
参考文档
- Java Code to Byte Code
- JVM Internals
- 从字节码层面看“HelloWorld”
- ASM官网
- CGLIB介绍与原理
- CGLIB(Code Generation Library)详解
- JVM之字节码——Class文件格式
- 云溪社区--JVM Class详解之一
- 云溪社区--JVM Class字节码之三-使用BCEL改变类属性
- 国外翻译文章:Java 编程的动态性,用 BCEL 设计字节码