本文原文地址http://dbtemp.blogspot.com/2011/08/structural-equation-modeling-in-openmx.html
模型的自由度
结构模型的一个重要特征就是可以用简单的方式对数据进行解释。我们可以很容易的用优化步骤估计数据的协方差矩阵和均值,而不用对他们之间的关系进行建模。下面我们将会看到,我们可以通过对模型进行估计,提供一个baseline(一个饱和模型,'saturated model'),将结构模型与这个模型相比较,可以得到结构模型的似然度。在模型构建时,一个重要的法则便是:简单就是正义!因此,我们认为好的结构模型应该可以通过对数目较少的参数进行建模来解释观测到的数据。需要估计的参数和观测的统计量之间的数量差,与模型的自由度有关。
在Part1中提到的模型中,

假设我们将潜变量(V和N)的方差设为1,即不用去估计这两个值,我们还有8个需要估计的变量(笔者:8个也是好多啊)。这8个变量是:a,b,c,d,e,f,g,h。我们放入模型里的 观测到的协方差矩阵一共包含10个不同的值(因为矩阵是对称的,即我跟你的协方差=你跟我的协方差,所以我们只用考虑矩阵一半的值)即,这里我们只考虑下三角的值。
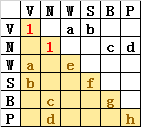
共有10个值,其中两个是不用估计的1。因此 10-2=8即为模型自由度。
实际上,在OpenMx中,均值和协方差都要估计,在如上图所示的模型里,这意味着一共有14个观测值以及12个要估计的值,自由度仍然是2。
一般来说,自由度大于零是很重要的,这样的模型被称作 overidentified模型(过度识别?)。相反的,如果我们设计的模型中要估计的参数比观测的参数还要多的时候,这个模型就是underidentified(识别不足的)并且不能得到很好地结果。下面我们会讨论到,针对一些模型,给其中的一些参数固定值是有必要的(这样他们就不算在要估计的参数中了),或是,设定好两条路径之间的关系(这样相当于两条路径变成了一条,另外一条随之变化),这样就可以保证模型是过度识别的。
现在,我们就可以开始应用我们的模拟数据,对模型进行拟合了。
首先,设定所有变量的均值都是0,方差为1,W和S的协方差为0.6,B和P的协方差是0.5,其他变量之间协方差是0。
这里我们需要用到mvrnorm函数来生成数据,在R中查阅函数用法有两种方式:
help(mvrnorm)
example(mvrnorm)
但是有时候,你得到的信息是:
这是因为mvrnorm函数所在的package没有被R自动加载,我们需要手动加载一下。
require(OpenMx)
加载完毕后就可以使用help和example了。
下面生成4个变量
使用下面程序可以生成相关变量,可以设定相关系数的大小
#-------------------------------------------------------------------------------------------------------
# Simcorr
# (based on p 11 of OpenMx manual )
# Modified version by: DVM Bishop, 3rd March 2010
# Simulates data on X and Y from 50 cases, with correlation of .5 between them
# (NB using smaller N than in original example, so user can see mismatch between
# obtained correlation and that specified by user).
#-------------------------------------------------------------------------------------------------------
require(MASS) # MASS is R package used for generating multivariate normal data
set.seed(2) # A seed is a value used in creating random numbers;
# You don't need to understand how it works and you can use any number.
# Keep the seed the same if you want the same random numbers every time you run
# Change the seed to any other number to run the script and get different random numbers
rs=.5 # User-specified correlation between variables
# The next command has been broken up with comments to explain each part
# But normally would just be written in one line as:
# mydata=mvrnorm(50,c(0,0),matrix(c(1,rs,rs,1),2,2))
mydata=mvrnorm(50, # Create matrix of multivariate random normal deviates, mydata,
# and specify number of XY pairs to generate
c(0,0), # User-specified mean values for X and Y; NB c denotes concatenation in R
matrix(c(1,rs,
rs,1),
2,2)) # Covariance matrix to be simulated, 2 rows, 2 columns
# this will give a matrix as follows: [1 .5
# .5 1]
mylabels=c('X','Y') # Put labels (X and Y) for the two variables in a vector
dimnames(mydata)=list(NULL,mylabels) # Allocate labels to mydata (our created dataset)
# A list contains a vector of row labels and a vector of column labels;
# We just want the second vector, and so NULL is the first entry
summary(mydata) # Print means for mydata
print('Covariances')
cov(mydata) # Print covariance for mydata
print('Correlations')
cor(mydata) # Print correlation for mydata
print('Note that actual values may differ from specified value of .5, especially with small sample size')
print('SDs')
sd(mydata) # Print SD for mydata
print('Note that the correlation = covariance/(SD_X * SD_Y)')
plot(mydata) # Plot a scatterplot of X vs Y
write.table(mydata,"myfile") # Save a copy of mydata in your R directory under name "myfile"
# If you want to re-read your data another time, you can use a command such as
# newdata=read.table("myfile");
# This will create a matrix called newdata containing the data
#------------------------------------------------------------------------------------------------------------------------
或者读者可以用以下命令生成,以W和S为例,协方差0.6,均值0,方差1,80个观测值
WandS=mvrnorm(80, # 指定变量中样本个数
c(0,0), #指定每个变量的均值
matrix(c(1,0.6,0.6,1),2,2)) #指定变量间的协方差矩阵,并指定为2*2大小,
#该矩阵这里为(变量自己和自己的协方差为变量方差)
# |1 0.6|
# |0.6 1|
以上生成的变量都是随机的,即每次运行的结果都不同。
CovMat = matrix(c(0),nrow=4,ncol=4)
CovMat[1,2] = 0.6
CovMat[3,4] = 0.5
CovMat = t(CovMat)+diag(1,4)+CovMat
myscore=mvrnorm(80,c(0,0,0,0),
matrix(CovMat,4,4))
myW = FourVar[,1]
myS = FourVar[,2]
myB = FourVar[,3]
myP = FourVar[,4]
write.table(x = myscore,file = 'my4var')
基于模拟的数据可以用cor(myscore)来检验,得到的结果会和一开始设定好的有所不同,这是由于样本量小的缘故。最后的结果保存在my4Var内
下面就开始真正的OpenMx的使用了
OpenMx为我们提供了一个选项可以用来设定我们的模型的类型为RAM,这对初学者来说是非常有用的,因为我们可以很清楚的用这个模型构架出图上的模型。对于一个RAM模型来说,我们在模型中会指定哪些是显变量,哪些是潜变量,以及这些变量之间哪些路径是单方向箭头、哪些是双方向箭头。代码如下:
# -----------------------------------------------------------------------
# Program: PathCov_2factor, based on TwoFactorModel_PathCov.R
# Author: DVM Bishop
# Date: 4th March 2010
#
# Two Factor model to estimate factor loadings and residual variances
# Path style model input - Covariance matrix data input
# -----------------------------------------------------------------------
require(OpenMx)
#准备数据
myscore=read.table("my4var") #把我们之前保存的数据读入
mylabels=c('W', 'S', 'B', 'P')
colnames(myscore)=mylabels # 指定矩阵中的每一列都叫什么名字
myFADataCov=cov(myscore) # 把这些变量之间真实的协方差列出
# -----------------------------------------------------------------------
#生成一个 MxModel 对象; 然后通过 mxRun 进行模型拟合
# 因为我们选取的是RAM类型的模型,这里需要对每一条路径进行建模
# -----------------------------------------------------------------------
db_twoFactorModel <- mxModel("DB_Two Factor Model_Path", type="RAM",
mxData( #指定输入数据集
observed=myFADataCov, # 观测变量为原始
type="cov",
numObs=nrow(myscore),
),
manifestVars=c("W", "S", "B", "P"), #指定显变量名字
latentVars=c("V","N"), #指定潜变量名字
# 剩余方差
mxPath(
from=c("W", "S", "B", "P"), #设置路径起点
arrows=2, #箭头是双向的
free=TRUE, #设置所有的值是不固定的,需要估计
values=1, #初始值为1
labels=c("e1","e2","e3","e4") #设定路径名
),
# latent variances ; NB no covariance between factors in this model
mxPath(
from=c("V","N"), #设置路径
arrows=2, # 箭头是双向的
free=FALSE, # 设置所有的值是固定的,不需要估计
values=1, #初始值为 1
labels=c("varV","varN") #设定路径名
),
# factor loadings for verbal variables
mxPath(
from="V",#设置路径从V出发
to=c("W","S"),#设置路径指向W和S
arrows=1, # 箭头是单向的
free=TRUE, #设置所有的值是不固定的,需要估计
values=c(1,1), # 两个变量的初始值都为1
labels=c("a","b")
),
# 非语言变量的因素载荷 (这里已经忘记了的就去看part1吧)
mxPath(
from="N",
to=c("B", "P"),
arrows=1,
free=c(TRUE,TRUE), # 只是为了展示另外一种赋值的方法
values=c(1,1),
labels=c("c","d")
)
)
#模型设置完毕
db_twoFactorFit <- mxRun(db_twoFactorModel) #运行模型
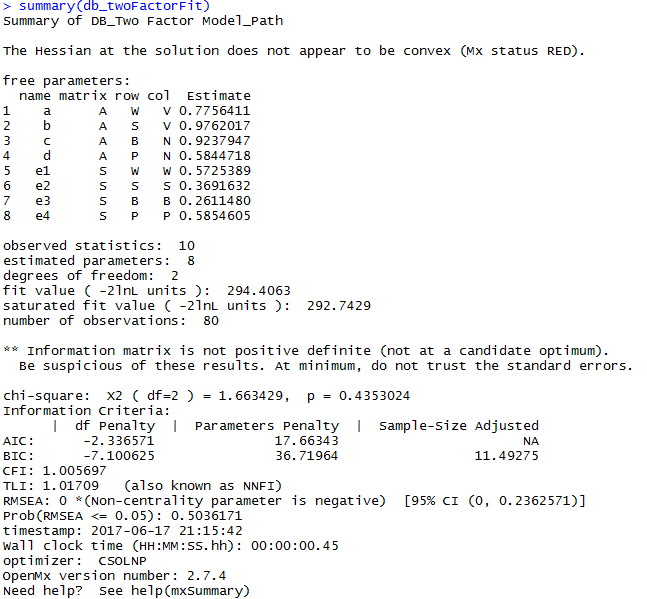
summary(db_twoFactorFit)
db_twoFactorFit@output$estimate
omxGraphviz(db_twoFactorModel, dotFilename = "twofact.dot")
# 生成一个可以通过Graphviz读入的脚本
#----------------------------------------------------------------

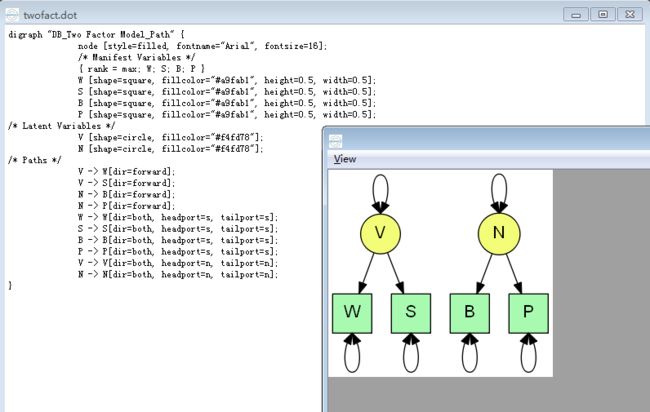
如上的一个RAM模型中
- 必须设定那些是显变量,用
manifestVars=指定,并且指定那些是潜变量,用latentVars=指定。在本例中,显变量是W,S,B,P,潜变量是V和N。 - 使用
mxPath函数串讲路径,一次调用可以同时创建多条路径。参数里的'from'指的是路径的起点,'to'则指明路径的终点(也被称作水池‘sink’)。如果终点没有给定,则认为终点和起点是同一个。默认的,起点中第i个元素和终点中第i个元素相匹配,按顺序创建路径。 -
arrows参数用来指定路径的方向(单方向箭头、双方向箭头) -
free变量是一个布尔向量,其值只能为True或是False,用来指定路径的值是固定的还是非固定的 -
values是一个数值变量,指定每条路径的初始值 -
labels是一个字符变量,对每个参数给予一个字符标记 - 通过
summary函数,可以很方便的显示模型拟合之后的结果。一般需要检查这个表来保证结果是合适的。就我们的模型来说,summary的结果首先给我数据集的分布统计信息。(我们通过observed选项给予模型的数据集)。如果我们使用raw来给定输入数据集,这输出的统计信息将包含所有变量的均值等。这里,我们给定的是观测变量之间的协方差矩阵,summary的信息会给我们协方差的均值,这个其实没啥用。不过,我们后面有可以看到原始变量均值的方法。
- 后面的表格里,输出的是矩阵A(单向箭头矩阵)、S(双向箭头矩阵)以及M(均值矩阵)中的参数。标准误可以通过
db_twoFactorFit@output$standardErrors给出,传统方法中可以用均值和标准误来给出置信区间。即95% CI 为估计均值-1.96标准误~估计均值+1.96标准误。若得到的区间不包括0,则路径是显著的,因而不能从模型中去掉。现在有了不是这么估计CI的方法,但是类似软件,如Mplus中还是这么估计,so,笔者认为都可以吧。毕竟还是那句话,不显著的,不管你怎么折腾,也不是那么显著的。ps. 结果差别还挺大的。 - 自由度也在summary中给出了,与我们预期的一样是2。
- 负2倍的log似然度(-2LL),其代表了在拟合模型的优化过程中,最小的似然度。然而,这个模型的-2LL本身并没有什么意义,需要与其他模型的似然度作比较,才能给出模型拟合数据的好坏,并用差值去评价模型之间的差异(去掉的变量)。
一下介绍两种很有用的比较。
1. OpenMx中自动提供的,与“饱和模型”的比较。
虽然“饱和模型”被称为模型,但是其与结构方程模型通常意义下的模型并不一样。区别在于:饱和模型中不包含潜变量。这个模型仅仅代表了对观测变量最优的拟合过程。和我们之前估计似然度的脚本类似,一开始对一对变量进行估计,然后对三个变量进行估计。(这个部分还没翻译)饱和模型的-2LL的值总是要小于包含潜变量的模型,这是因为包含潜变量的模型在寻优过程中是不受到限制的。饱和模型并不是我们感兴趣的,它具有与观测变量数量相同的待估计变量,因此没有自由度(df=0)。
那我们引入饱和模型的目的是什么呢?饱和模型可以为我们设置的上文中提到的过度识别模型提供-2LL值的基线标准。我们设置的模型的-2LL减去饱和模型的-2LL后得到的值是一个服从卡方分布的统计量,该统计量对应的自由度就是这个模型的自由度减去饱和模型的自由度(0)。
因此,上述例子中,chi2 = 204.3614 – 201.7717 = 2.5897; df = 2 – 0 = 2
如脚本的输出所示,相对应的 p=0.273,通常意义上的不显著。这里不要担心或者是灰心丧气,当拟合结构模型的时候,不显著的卡方值意味着模型拟合的很好,这是因为这个结果表示:虽然我们设置的模型的拟合程度更差一些,但是它的的-2LL值与饱和模型的-2LL值是没有显著差异的。
2. AIC、BIC以及RMSEA也是可以衡量拟合程度好坏的指标。
就我们的模型来说,Akaike's Information Criterion (AIC) 赤池信息量准则的值小于0,这也说明模型拟合的很好。Bayesian information criterion (BIC) 贝叶斯信息量准则的值也是越小越好。对于RMSEA来说,一般的,其值小于0.05时说明拟合质量非常好,介于0.05和0.10之间时,说明拟合的不错。
代码的最后一行可以输出路径图。可以使用免费软件打开保存的结果。Graphviz from:
http://www.graphviz.org/
现在我们尝试把模型中某一条路径去掉。一般的,我们会将设置的模型和饱和模型相比较得到拟合优度牡丹石不同的设置模型之间也可以直接进行比较(如果他们是嵌套模型nested)。
嵌套模型
嵌套模型指的是一系列模型的集合,这些模型具有相同路径结构,只是不同的模型中某些特定的路径的值是固定的。如果我们将路径的值设为:0,然后将其类型设置为:free=FALSE,这就意味着OpenMx将不会对该路径进行估计,而是会保证其值固定位初始值不变。这样做的结果就是,这条路径被拿掉了。
下面我们将演示把模型中的路径d去掉。
mxPath(
from="N",
to=c("B", "P"),
arrows=1,
free=c(TRUE,FALSE),#固定值
values=c(1,0), #d的初始值为0
labels=c("c","d")
现在,模型的自由度增加了1(待估计变量少了一个),去掉路径d之后的效果如下:

chi2为22.28,自由度为1,相对应的p<0.001。结果告诉我们去掉路径d之后会显著的降低模型拟合的质量。
note: 使用R计算chi2的p值的脚本
1-pchisq(chi,df)
从以上结果不难发现,由于不显著对应于模型拟合更好,因此,-2LL越大则意味着拟合的更差。这与传统的统计完全相反,即显著的chi2表示拟合效果很差。传统统计中,常常将chi2与随机情况相对比,从而得到结果中有多少不能被随机因素解释。而在SEM中,拟合程度是与饱和模型的拟合程度相比较,或是将过度识别模型与自由度较少的模型相互比较(如上所述)。对比模型之间相差的需要估计的参数越多,则能得到的chi2就越大,因此也就越“显著”。这里,显著性指的是估计值远离观测值的程度。读者可以尝试改变样本数量,会发现样本数量越大则模型需要拟合的点也就越多,因此统计值也就越准确(标准误更小),但是相应的模型也会相对于饱和模型有更显著的差异。