如何使用Spark连接与操作Mysql数据库
JDBC介绍
Spark SQL可以通过JDBC从关系型数据库中读取数据的方式创建DataFrame,通过对DataFrame一系列的计算后,还可以将数据再写回关系型数据库中。
从MySQL中加载数据(Spark Shell方式)
1.启动Spark Shell,必须指定mysql连接驱动jar包
/home/hadoop/apps/spark/bin/spark-shell \
--master spark://hdp08:7077 \
--jars /home/hadoop/mysql-connector-java-5.1.45.jar \
--driver-class-path /home/hadoop/mysql-connector-java-5.1.45.jar
--executor-memory 1g
--total-executor-cores 2
2.从mysql中加载数据
scala> case class Emp(empno: Int, ename: String, job:String,mgr:Int,hiredate:java.util.Date,sal:Float,comm:Float,deptno:Int)
scala>var sqlContext = new org.apache.spark.sql.SQLContext(sc);
scala> val jdbcDF = sqlContext.read.format("jdbc").options(Map("url" -> "jdbc:mysql://hdp08:3306/sqoopdb", "driver" -> "com.mysql.jdbc.Driver", "dbtable" -> "emp", "user" -> "root", "password" -> "root")).load()
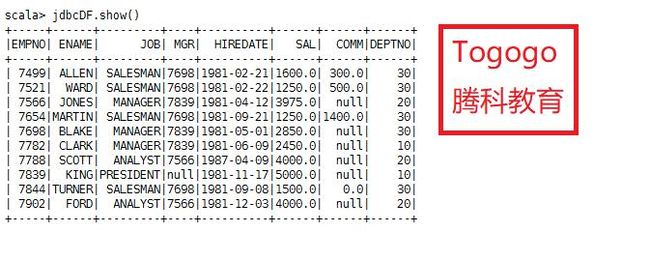
3.执行查询
jdbcDF.show()
将数据写入到MySQL中(打jar包方式)
本文介绍使用Idea 开发spark连接mysql操作,并建立maven 工程进行相关开发
Maven中的pom.xml文件依赖
编写Spark SQL程序
package net.togogo.sql
import java.util.Properties
importorg.apache.spark.sql.{SQLContext, Row}
importorg.apache.spark.sql.types.{StringType, IntegerType, StructField, StructType}
import org.apache.spark.{SparkConf, SparkContext}
object JdbcRDD {
def main(args: Array[String]) {
val conf= new SparkConf().setAppName("MySQL-Demo")
val sc= new SparkContext(conf)
val sqlContext= new SQLContext(sc)
//通过并行化创建RDD
val personRDD= sc.parallelize(Array("1 tom 5", "2 jerry 3", "3 kitty 6")).map(_.split(" "))
//通过StructType直接指定每个字段的schema
val schema= StructType(
List(
StructField("id", IntegerType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)
)
)
//将RDD映射到rowRDD
val rowRDD= personRDD.map(p=> Row(p(0).toInt, p(1).trim, p(2).toInt))
//将schema信息应用到rowRDD上
val personDataFrame= sqlContext.createDataFrame(rowRDD, schema)
//创建Properties存储数据库相关属性
val prop= new Properties()
prop.put("user", "root")
prop.put("password", "root")
//将数据追加到数据库
personDataFrame.write.mode("append").jdbc("jdbc:mysql://hdp08:3306/sqoopdb", "sqoopdb.person", prop)
//停止SparkContext
sc.stop()
}
}
打包与运行
1.用maven将程序打包
2.将Jar包提交到spark集群
/home/hadoop/apps/spark/bin/spark-submit \
--class net.togogo.sql.JdbcRDD \
--master spark://hdp08:7077 \
--jars /home/hadoop/mysql-connector-java-5.1.45.jar \
--driver-class-path /home/hadoop/mysql-connector-java-5.1.45.jar \
/home/hadoop/schema.jar