【Hadoop大数据基础】##
【第一课】会跳舞的大象(什么是Hadoop大数据)
1.1 什么是大数据
1.2 Hadoop的由来
1.3 为什么要使用Hadoop
1.4 Hadoop的生态圈
1.5 Hadoop的应用
1.6 课后作业
1.1 什么是大数据
最近小张网校<分布式架构初探>实战班的童鞋问我可不可以学习Hadoop大数据。
答案是当然可以。
大数据的架构正好是一种分布式架构的体现。
我们就以Hadoop作为入口,学习正在流行的大数据生态圈。
什么是大数据?
前段时间我去广州野生动物园玩耍,看到了大象,好多大象,就是这样

走起路来,慢悠悠的,那真的是稳重,应该说是笨重 ,就像
《我的滑板鞋》里面唱的样:一步两步 一步两步 一步一步 似爪牙似魔鬼的步伐 摩擦 摩擦
想想我们自己,长的胖的人好像走起路来是很“笨重”,这个就跟我们开发过的系统一样,刚开始数据量级比较小的时候很轻盈,数据量大了以后,就像大象一样,笨重、反应迟钝。
动物园里见到的大家都是那种笨重的,那么有没有理想中轻盈的大象呢,有,就是下面这一只了,世上也只有这一只会跳舞的大象。

让大象变的轻盈那是Hadoop要解决的事情,从上面可以看出,何为大数据,数据量大就是大数据?
不仅仅如此
Volume(大量)、Velocity(高速)、Variety(多样)、Value(价值)
大量:数据量大 至少是GB/TB/PB 级别的
高速:数据变化快,快速分析、及时响应变化
多样:数据的多样性,文本、图像、视频等
价值:我们需要从大量的数据中提取有价值的部分
1.2 Hadoop的由来
Hadoop 最开始是来自于搜索引擎的技术,因为搜索引擎爬虫爬取的数据非常大,
而爬取到的文本信息又需要处理,进行数据整理、排序等操作。
2008年4月,Hadoop打破世界纪录,成为最快排序1TB数据的系统。运行一个910节点的集群,Hadoop在209秒内排序了1TB的数据(还不到三分钟),击败了前一年的297秒冠军。
2009年5月,Yahoo的团队使用Hadoop对1TB的数据进行排序只花了62秒时间。
1.3 为什么要使用Hadoop
想想以(现)前(在)你们是怎么分析数据的呢?
写一个JAVA程序分析还是Python脚本分析?
举个例子:去年深圳一家互联网公司请我们给他们做顾问,他们公司生产环境的数据日志是每天从生产数据库导出到数据服务器,再通过一个Python脚本分析这些日志并存入MySQL当中,这种方式在数据量小的情况下还没什么事数据量一大,所需时间是几何增长。有段时间他们服务器每天光log解压之后就有几十个G,虽然通过很多手段比如减少查询,减少单条数据插入,使用LOAD将数据导入数据库,但所需时间还是要很久。为了减少每天log分析的时间以及数据的稳定性,决定搭建一个Hadoop系统,使用hadoop map/reduce来并行的处理log。
1.4 Hadoop的生态圈
Hadoop 现在已经逐渐发展成为了一个生态圈,我们来看一张图:
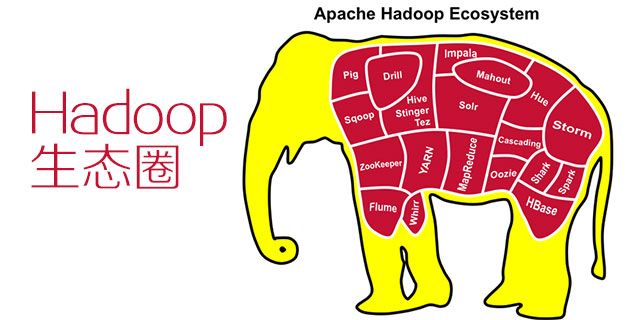
看到这个图是不是有点懵逼了,不要紧,我们紧抓Hadoop这条线,然后跟着课程慢慢扩展,整个生态圈的学习就会轻松自如的,接下来简单的介绍一下整个生态圈每个部分的作用。
Pig:Pig是一种编程语言,它简化了Hadoop常见的工作任务。Pig可加载数据、表达转换数据以及存储最终结果。
Sqoop:主要用于将传统的关系型数据库mysql等数据转换到Hadoop中
Zookeeper:是一个分布式协调服务
Flume:是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统
Hive:hive是基于Hadoop的一个数据仓库工具
YARN:Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器
MapReduce:Hadoop的计算框架
Oozie:Oozie是一个工作流引擎服务器,用于运行Hadoop Map/Reduce和Pig 任务工作流
Cascading:是一个架构在Hadoop上的API,用来创建复杂和容错数据处理工作流。
Mahout:Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序
Impala:Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。
Hue:Hue 是运营和开发Hadoop应用的图形化用户界面
Storm: Storm是一个免费开源、分布式、高容错的实时计算系统。
HBase:HBase是基于Google BigTable模型开发的,典型的key/value系统;
Hadoop生态圈的东西太多了,看的是不是眼花缭乱的,其实这些还不是全部,但是我们只要了解他们每个在整个大数据系统中的作用,就很容易理解了,这里大家只要了解一下就可以。
1.5 Hadoop的应用
** 中国移动智慧交通项目 **
接下来我们会以这个项目来做实战:
在中国移动智慧交通项目中,用基站的数据来对人群的行动轨迹进行分析,分析出高铁、CBD商圈等地段人群的轨迹以及分布,来预测未来的交通情况以及规律,给出合理的交通疏导的方案,让交通更智能,合理分配资源,也让我们出行更方便,这就是大数据的威力。
Hadoop在购物商城的应用
一家购物网站上每日产生的数据约50G,需要从以往购物的数据中分析出用户的喜好。
如:1.展示用户近期购物的类型,是男装还是女装或者是家电也有可能是零食。将所关注的放在一眼就能让用户看到的地方。
2.用户的行为分析,通过用户最近三个月的登陆时间/浏览过的店铺/购买过或咨询过的商品/购买过以往商品的价格平均值/停留时长来分析用户搜索某商品的展示顺序(其中也包含了卖家的信用综合信息)。
3.展示用户近期的消费记录走势等等
1.6 课后作业
- 大数据的四个特征?
- Hadoop中有个很经典的入门,类似HelloWorld , 他是WordCount

功能很简单,有一个文本数据格式如下:
小张网校 麒麟 小张 网校
JAVA 开发 小张 分布式
Hadoop HDFS MapReduce 小张网校
我们先用JAVA语言写出这个文本中每个词出现的次数,结果以下面格式输出
(下一节我们用Hadoop的方式来重写这个功能,来体验区别)
小张网校 2
麒麟 1
小张 2
