一.前提条件
在kaldi目录下的子目录kaldi/egs/目录下保存着资源管理示例脚本。查看该目录中的README.txt文件,尤其是查看资源管理部分,它提到 与语料库相对应的LDC目录号。这可以从LDC获取数据。
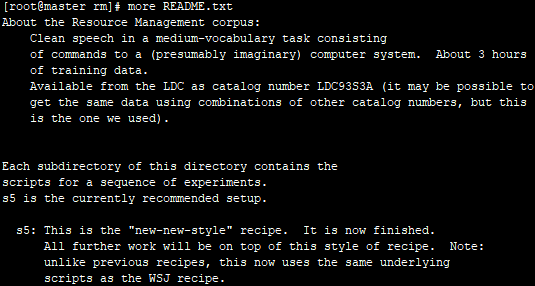
进入rm目录,浏览README.txt文件查看整体结构,进入s5子目录,在s5目录中,列出并浏览RESULTS文件,以便对其中的内容有所了解。其中最重要的文件是run.sh。注意,run.sh不能直接执行,必须手动执行文件中的一系列命令。
![]()
二.资料准备
首先,需要配置作业,如果没有安装GridEngine【分布式资源管理工具】,或者是使用较小的数据集进行实验,可以在shell上执行以下命令:
![]()
如果安装了GridEngine,则应将queue.pl文件与指定GridEngine驻留位置的参数一起使用。在这种情况下,执行以下命令【参数-q是示例,在实际应用中替换为GridEngine详细信息】:
train_cmd=" queue.pl -q all.q@a*.clsp.jhu.edu"
encode_cmd="queue.pl -q all.q@[ah]*.clsp.jhu.edu"
下一步是从rm语料库中创建测试和训练集。为此,执行以下命令【假设要测试的数据在./export/LDC/LDC2019S20/rm_comp/下,此数据可以去KALDI下载,需要付费】
![]()
命令:./local/rm_data_prep.sh /export/LDC/LDC2019S20/rm_comp/
执行成功后,会在当前目录下创建data的新目录。这个新目录包含三种主要的文件夹类型:
·local:包含当前数据的字典。
·train:从语料库中分割出来的用于训练的数据。
·test_*:从语料库中分割出来的数据,用于测试。
![]()
在数据目录下执行下面的命令:
cd local/dict
head lexicon.txt
head nonsilence_phones.txt
head silence_phones.txt
使用这些命令可以大致了解通用数据准备过程的输出。应该意识到,并非所有的这些文件都是本地Kaldi格式,即,并非所有文件都可以被Kaldi的C++程序读取,部分还需要使用Kaldi之前使用OpenFST工具进行处理。
lexicon.txt:词典
*silence*.txt:这些文件包含有关电话静音已经保持静音的信息。
在train目录下,执行以下命令:
head text
head spk2gender
head spk2utt
head utt2spk
head wav.scp
·text:该文件包含发声和发声ID之间的映射,这些映射将由Kaldi使用。该文件将转换为整数格式,但仍然是文本文件,单词将被替换为整数。
·spk2gender:该文件包含说话人及其性别之间的映射。这将充当参与培训的唯一用户列表。
.spk2utt:这是说话者标识符与说话者相关的所有话语标识符之间的映射。
.utt2spk:这是发话ID与相应说话者标识符之间的一对一映射。
·wav.scp-Kaldi程序在进行特征提取时实际上直接读取该文件。再次查看该文件,它被解析成一组键值对,其中键是每一行的第一个字符串。该值是一种“扩展文件名”。请注意,尽管我们使用扩展名.scp,但从HTK的角度来看,它不是脚本文件。
train文件夹和test_*文件夹的结构相同。但是,train数据的大小明显大于test_*数据。可以通过返回数据目录并执行以下命令来验证这一点,该命令将给出训练集和测试集的字数:wc train/text test_feb89/text
下一步是创建Kaldi使用的原始语言文件。在大多数情况下,这些文件将是整数格式的文本文件。确保返回到s5目录,并执行以下命令:
utils/prepare_lang.sh data/local/dict '!SIL' data/local/lang data/lang
这将在本地文件夹中创建一个名为lang的新文件夹,其中将包含描述所用语言的FST。看一下脚本。它将以data/创建的某些文件转化为Kaldi读取的规范形式。该脚本在data/lang/目录中创建其输出。该脚本创建的前两个文件称为words.txt和phones.txt【都在data/lang/下】。这些是OpenFst格式的符号表,表示从字符串到整数再到整数的映射。查看这些文件,它们很重要并且会经常使用。
查看后缀为.csl的文件【在data/lang/phones中】,这些分别是冒号分隔的非静音和静音电话的整数ID列表。有时需要它们作为程序命令行上的选项,以及其它目的。
查看phone.txt【在data/lang/中】,该文件是电话符号表,还处理标准FST中使用的"消歧符号"。这些符号通常称为#1,#2等。其中符号#0用来替换语言模型中的epsilon转换。
文件L.fst是FST格式的编译词典。要查看其中包含哪种信息,可以执行以下操作:
fstprint --isymbols=data/lang/phones.txt --osymbols=data/lang/words.txt data/lang/L.fst | head
如果bash找不到命令fstprint,则需要将OpenFST的安装路径添加到PATH环境变量中。只需要运行脚本path.sh即可:
../path.sh
下一步是使用在上一步中创建的文件来创建描述该语言语法的FST。为此,返回目录s5并执行以下命令:
./local/rm_prepare_gtammar.sh
如果成功,则应该返回消息"成功为RM准备语法"。将在/data/lang中创建一个名为G.fst的新文件。
三.特征提取
1.提取训练功能
export featdir=/my/disk/rm_mfccdir # make sure featdir exists and is somewhere you can write. # can be local if you want. mkdir $featdir for x in test_mar87 test_oct87 test_feb89 test_oct89 test_feb91 test_sep92 train; do \ steps/make_mfcc.sh --nj 8 --cmd "run.pl" data/$x exp/make_mfcc/$x $featdir; \ steps/compute_cmvn_stats.sh data/$x exp/make_mfcc/$x $featdir; \ done
运行这些作业,它们并行使用多个CPU,可以根据计算机的CPU数量更改-nj选项【指定要运行的作业数量】。查看文件exp /make_mfcc/train/make_mfcc.1.log以查看创建MFCC程序的日志输出。
2.核心概念
表的概念是基础脚本和归档文件。表格基本上是一组有序的项目,由唯一的字符串索引。Table并不是真正的C++对象,因为有单独的C++对象来访问数据,具体取决于我们是编写、迭代还是进行随机访问。类型的示例数据如下:
BaseFloatMatrixWriter
RandomAccessBaseFloatMatrixReader
SequentialBaseFloatMatrixReader
这些类型都是实际为模板类的typedef。脚本【.scp】文件或存档【.ark】文件都被视为数据表。格式如下:
·脚本格式是纯文本格式,其中包含带有键的行,然后是扩展文件名,该文件名告诉Kaldi在哪里可以找到数据。
·存档格式可以是文本或二进制。格式为键+空格+对象数据。
有关脚本和档案的一些一般要点:
·指定如何读取表的字符串称为rspecifier。例如:ark:gunzip -c my/dir/foo.ark.gz|
·指定如何编写表的字符串称为wspecifier。例如:ark,t:foo.ark
·归档可以串联在一起,仍然是有效的归档。
·该代码可以顺序或通过随机访问读取脚本和存档。用户级代码仅知道它是在迭代还是在进行查找。它不知道它是在访问脚本还是存档。
·Kaldi不会尝试在归档文件中表示对象类型。必须提前知道对象类型。
·归档文件和脚本文件不能包含类型的混合。
·由于代码可能必须将对象缓存在内存中,因此通过随机访问读取档案可能会导致内存效率低下。
·为了有效地随机访问档案,可以使用ark,scp写入机制来写入相应的脚步文件。然后通过scp文件访问它。
·避免对文档进行随机访问时内存中缓存了大量数据。
·对代码文档进行排序并且按照顺序进行调用。
·读写档案的类型以Holder类型为模板,该类型知道如何读取和写入相关对象。