一 为什么读这篇
这篇早在玩Doodle的时候就列进TODO了,因为一直在看各种网络架构,所以看的时候有点晚。在不改变数据的前提下,要想效果好其实就两块工作,要么试各种牛逼的网络架构,要么就靠各种tricks,本篇算是各种tricks的合集。
二 截止阅读时这篇论文的引用次数
2019.2.2 10次。有点可怜。
三 相关背景介绍
18年3月挂到arXiv上,作者Leslie N. Smith还是非常猛的,经常独自一人灌长文,也是CLR的作者,一直在美国海军研究实验室工作。此外,fastai创始人Jeremy Howard也发推肯定了本文的工作。
基于Caffe的官方实现:https://github.com/lnsmith54/hyperParam1
四 关键词
tricks
CLR
convergence
LR range test
五 论文的主要贡献
1 提出几种找最优超参的方法论
2 test的loss也很重要,不能只看test的准确率
3 增加学习率有助于减少欠拟合,学习率太小可能会表现出一些过拟合的行为。大的学习率有正则化效果,但过大的LR又会导致训练不能收敛
4 大学习率有两个好处,一有正则化效应可以避免过拟合,二是可以更快的训练
5 在增加学习率的同时减小动量
6 因为更大的学习率有正则化效应,所以用更小的权重衰减更合适
六 详细解读
1 介绍
虽然deep learning在各领域都取得了很大的成功,不过如何设置超参仍是需要多年经验的黑科技。本文提出了几种设置超参的方法,可以在有效减少训练时间的同时提升效果。具体来说,本文展示了如何检查训练时验证/测试损失以判断是欠拟合还是过拟合,并指导如何找到最佳平衡点。之后讨论了如何增加(减少)学习率(动量)来加速训练。本文实验表明,对于每个数据集和架构,平衡各种正则化方法至关重要。权重衰减作为一种正则化方法,其最优值与学习率和动量也有紧密关系。
当前并没有简单容易的方式来设置超参,格网搜索和随机搜索计算开销和时间开销都太高了。实际上,从业者经常拿开源模型的默认参数直接用,而这对于自己的数据来说显然是欠优化的。
Part 1(本文)试验了学习率,batch size,动量,权重衰减,Part 2(尚未出版)试验了架构,正则化,数据集和任务。所有目的就是给从业者提供行之有效的建议。
本文的基本方法就是基于众所周知的如何平衡过拟合和欠拟合。实验表明学习率,动量和正则化紧密耦合,所以必须一起才能确定最佳值。
下面是本文最贴心的部分(看图和标题以及带有Remakr的段落就够了)

2 相关工作
本文的很多工作都是基于作者本人之前的工作。特别是15年提出来的CLR(17年更新一版)。4.1节更新了17年提出的super-convergence的实验。并讨论了以前提出的『Don’t decay the learning rate, increase the batch size』。
diss了一些人的工作,提出了不同的观点。比如"使用大学习率,小batch size","不要用权重衰减和dropout作为正则化"。
3 验证/测试损失难以置信的有效性
在训练初期通过监控验证损失,就会有足够的信息用于调节架构和超参,从而避免了没必要的格网或随机搜索。
图1展示了Cifar数据集上残差网络的学习率范围测试的训练损失(下面的橙线),验证准确率(上面的黄线)以及验证损失(上面的蓝线),目的是找到合理的用于训练的学习率。图1a左上角的黑框暗示了学习率在0.01到0.04之间有可能过拟合,而这条信息不会出现在测试准确率或训练损失的曲线中(划重点,说明test的loss也很重要,不能只看test的准确率)。
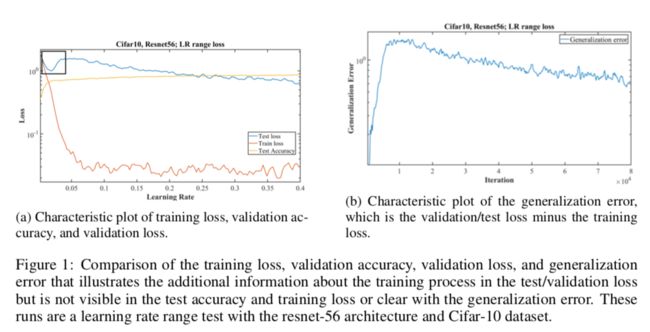
Remark1 测试/验证损失是网络是否收敛的良好指标
本文中测试/验证损失用来在训练时提供insight,最终的性能比较是测试准确率。
3.1 回顾欠拟合和过拟合的平衡
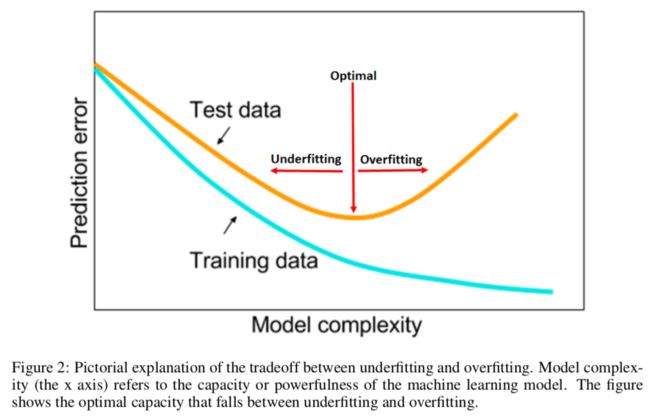
Remark2 需要注意的是,调节超参的目的就是达到测试损失的水平部分(图2中optimal指向处)
然而深度学习很难达到这个平衡点,因为需要搞的东西实在太多了,blablabla。
通过本节得到的一个insight是,在训练早期,测试/验证损失是处于欠拟合还是过拟合的迹象对于调节超参是有帮助的。训练过程中的测试损失可用于查找最佳网络架构和超参,而无需执行全部的训练。
3.2 欠拟合
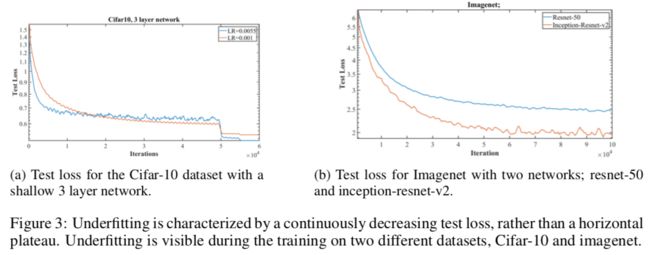
标志就是测试损失持续下降(图3a红线)。增加学习率使训练从欠拟合走向过拟合(图3a蓝线),注意测试损失在刚开始迭代时迅速下降,之后处于水平状态。这是早期的积极线索之一,表明最终该曲线的设置将产生比其他设置更好的准确率(感觉是废话。。如果换一个模型,发现刚开始loss就很低,那自然是很兴奋的)
第二个例子就是图3b的两个网络对比。Inception-ResNet-v2比ResNet-50更不容易欠拟合。
增加学习率有助于减少欠拟合(有意思!),找到好的学习率的一个简单办法就是LR范围测试(LR range test)(始于CLR这篇文章)。
3.3 过拟合
图1a的测试损失在小的学习率时(0.01-0.04)出现过拟合的迹象,然而随后在更高的学习率时测试损失持续下降,就好像欠拟合一样。这表明学习率太小可能会表现出一些过拟合的行为。
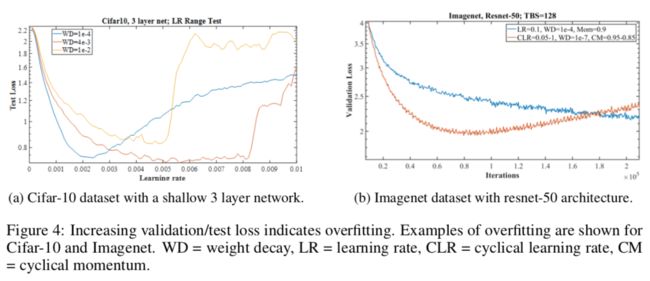
图4a,当WD=0.0001时,在lr为0.002附近时损失到最小值,之后开始过拟合,当WD=0.004时,损失在更大的学习率范围内保持稳定,同时达到了更低的损失值,说明该WD比之前的好,当WD=0.01时,lr在0.005附近时损失就开始有个尖锐的上升表明并不是过拟合,而是由于过大的学习率导致的训练不稳定。同理,红线在0.008的lr时也是一个意思。
第二个例子是图4b,蓝线是欠拟合,红线是用太小的权重衰减,WD=1e-7时,开始出现过拟合。
还有几个过拟合的例子可以参考图7a黄线,图9a蓝线,图11a。
设置网络超参的艺术最终会在欠拟合和过拟合之间的平衡点结束。
4 周期学习率,Batch Sizes,周期动量和权重衰减
4.1 回顾周期学习率和超级收敛
如果学习率过小,也会发生过拟合。大的学习率有正则化效果,但过大的LR又会导致训练不能收敛。由2015年提出,2017年更新的周期学习率(CLR)和学习率范围测试(LR range test)可用于选择学习率。
要使用CLR,需要指定最小和最大学习率边界和步长。一个周期由两步组成,一步从最小到最大线性增加学习率,另一步线性减少。作者在15年做了各种实验对比不同的学习率变化方式,发现效果都差不多,因此推荐用最简单的,线性变化。
在LR范围测试中,训练始于一个小的学习率,之后通过pre-training缓慢线性增加。这一步提供了在一段区间上不同学习率训练的网络的表现如何,以及最大学习率是什么的宝贵信息。当用一个小学习率开始时,网络开始收敛,之后随着学习率增加,最终变得太大而引起测试/验证损失的增加以及准确率的下降。这个极值处的学习率可以作为周期学习率的最大边界值,但如果是选择恒定学习率或网络不能收敛时,则需要更小的值。有3种方式来选择最小学习率的边界:
1 比最大界限小3到4倍
2 如果只有一个周期,则比最大界限小10到20倍
3 通过对一些初始学习率进行数百次迭代的简短测试,选择可以收敛的最大值,并且没有过拟合的迹象,如图1a所示那样。
需要注意的是,在训练没有变得不稳定之前,学习率增速(stepsize)也会影响最大最小学习率的选择。
超级收敛是在一个学习率周期内用非常大的学习率来加速收敛。大学习率有两个好处,一有正则化效应可以避免过拟合,二是可以更快的训练。图5a是一个例子,用范围从0.1到3.0的CLR只用1w个迭代就收敛了,与之相比,用值为0.1的常量初始学习率的常规做法需要8w个迭代。
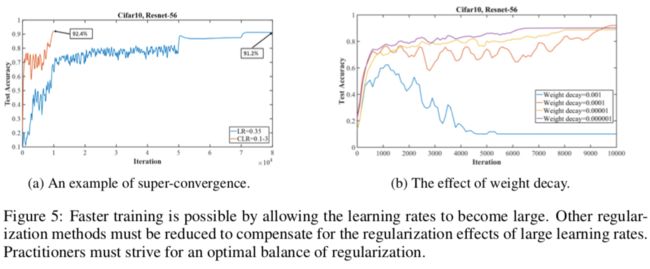
"1cycle"可以在训练结束前就达到准确率的瓶颈。
图5b说明权重衰减为或更小的值时能更好的用大学习率(如3.0),当权重衰减为时削弱了用大学习率训练网络的能力。需要平衡各种正则化技术,因为大学习率的正则化效应,所以必须减小其他形式的正则化。
Remark3 通用原则:必须为每个数据集和架构平衡正则化的总量
4.2 Batch Size
本节推荐使用1cycle学习率调度机制时使用更大的batch size。
比较batch size的一个难点是,保持一个固定的epochs个数与保持一个固定的迭代个数往往会得到矛盾的结果。
Remark4 从业者的目标是在达到最好效果的同时最小化所需的计算时间
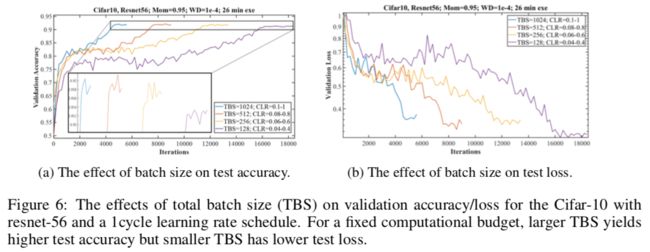
如图6a所示,更大的batch size使用更大的学习率。
硬件不限制的话,想用多大的batch size都可以,但如果有限的话,则使用符合显存限制的batch size以及更大的学习率。
4.3 周期动量
动量和学习率是紧密相关的。和学习率一样,只要不引起训练不稳定,动量能设置多大就设置多大。
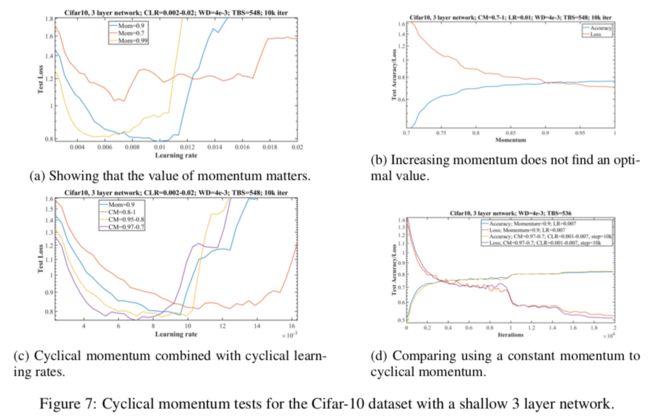
图7a说明动量的重要性,显然蓝线(值为0.9)效果最好,值得注意的是黄线(值为0.99),有过拟合的迹象(在开始发散之前(学习率0.01附近),最小值之间(学习率0.006附近))。
如图7b所示,实验证明动量范围测试对于找到最优动量并没有帮助。
Remark5 最佳动量值有助于提升网络训练
图7c用固定动量和周期动量作对比。并说明,在增加学习率的同时减小动量有3个好处:
1 如黄线和紫线所示,有更低的最小测试损失
2 更快的初始收敛,如黄线和紫线所示
3 在更大范围的学习率上有更好的收敛稳定性,如黄线所示
图7d是固定动量和周期动量的对比(两者差不多嘛。。)
当用周期学习率的时候,使用相反方向的周期动量是有意义的。但是固定学习率的时候,周期动量的效果不如固定动量(还是要配套使用)
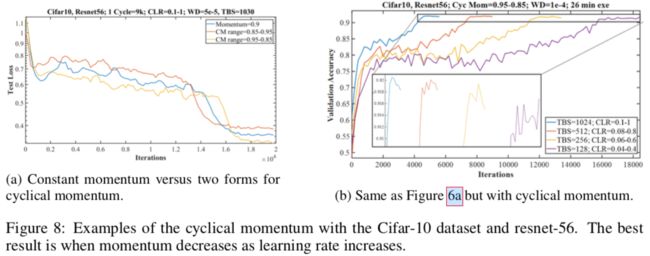
图8是resnet的实验结果。从浅层网络和深层网络得到的结论是一致的,只是有些具体的值不同。
4.4 权重衰减
本文实验说明权重衰减还是用固定值好(不要周期变化了)。
如果不知道怎么设置权重衰减,试试和0。更小的数据集和架构似乎需要更大的值,而更大的数据集和架构需要更小的值。另外,如果经验上合适,那么也可以试试(此处作者有很玄的解释)
Remark6 因为必须为每个数据集和架构平衡正则化的总量,所以权重衰减的值是一个关键,可以根据学习率的增加来调整正则化的关系
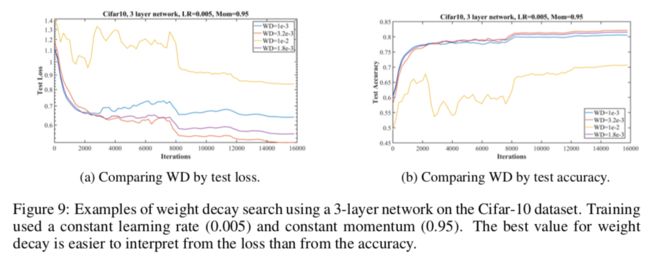
图10展示了同时调节权重衰减,学习率和动量。
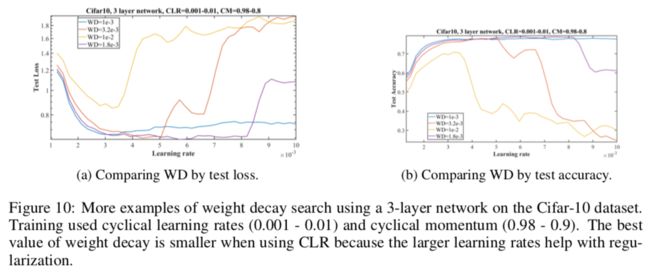
因为更大的学习率有正则化效应,所以用更小的权重衰减更合适。
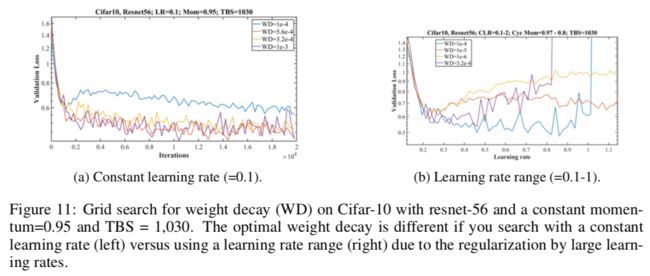
5 基于其他架构和数据集的实验
以上所有内容都可以浓缩为以下几条:
1 LR:对"大"学习率进行学习率范围测试。最大LR取决于架构。使用通过LR范围测试找到的最大学习率的1cycle 机制,最小学习率是最大学习率的1/10,学习率增速也需考虑(太快增加会导致不稳定)
2 Total batch size(TBS):更大的batch size更好,不过受限于GPU显存。用更大的batch size以便用更大的学习率
3 动量:简短的跑下值为0.99,0.97,0.95和0.9的动量值就可以很快找出最佳动量值。当用1cycle机制时,最好也用周期动量,其始于最大动量,随着学习率的增加而减少到0.8或0.85
4 权重衰减(WD):这需要网格搜索来确定合适的幅度,但通常不需要超过一个有效数字精度。更复杂的数据集需要更少的正则化因此测试更小的权重衰减值,如。而浅层架构需要更多正则化,因此测试更大的权重衰减值,如
5.1 CIFAR-10 Wide ResNet
32层,通道数从因子2改为因子4。

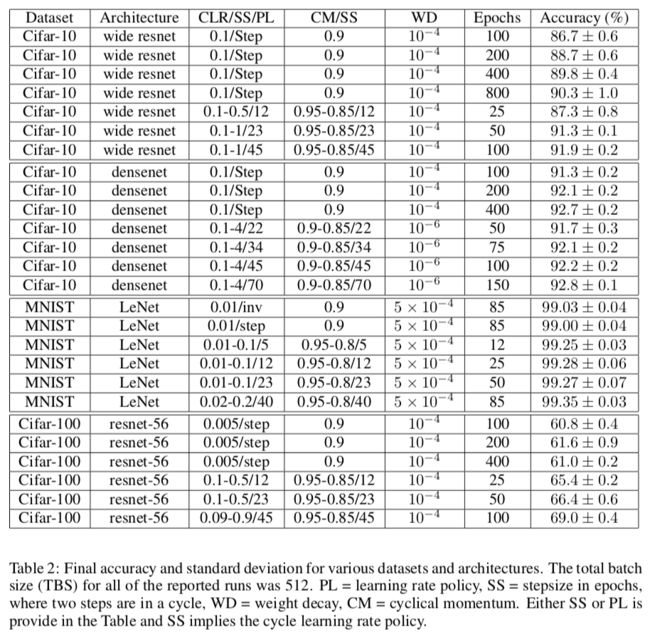
5.2 CIFAR-10 DenseNet
40层的DenseNet。找它的超参比Wide ResNet更有挑战。
图13c似乎说明架构的复杂增加了正则化效应,因此减少权重衰减是符合直觉的。
5.3 MNIST
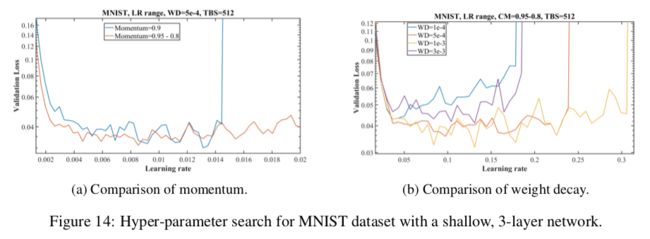
5.4 CIFAR-100
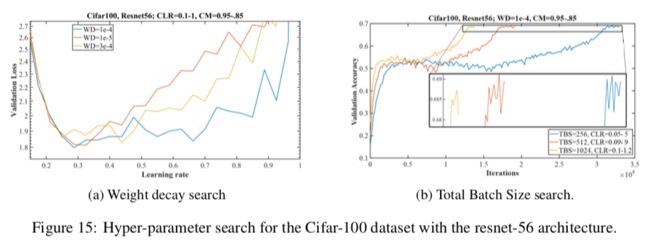
5.5 ImageNet
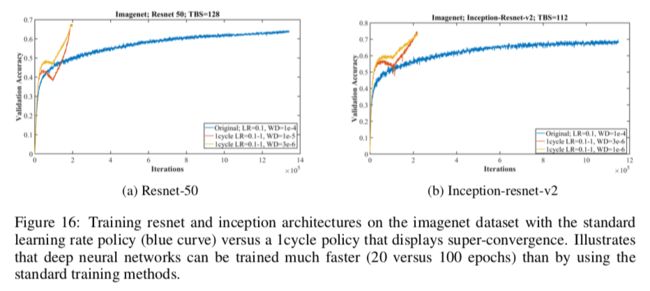
很明显,超级收敛比常规训练能快很多就收敛,效果还好一些。
这些实验说明深度学习模型训练起来可以比标准训练方法快很多。
6 讨论
因为各种训练深度学习模型的技巧散布于不同的论文,而且往往得到相互矛盾的结论,所以给人一种盲人摸象的感觉。本文重点介绍了各种remark和建议,以在加速网络训练的同时得到最佳效果。
七 读后感
信息密度还是非常高的一篇,读起来没那么容易。简直就是神文,堪称实验设计指导手册,各种玄学调参。此外本文给人的感觉是缺少一些理论依据,更多的是通过各种实验对比得出结论的。深度学习中这个事后找理论问题太明显了,本文算是其中的典范。最后,全部读完后,发现tricks并没有之前预期那么多,主要内容就是CLR和super convergence的内容。
八 补充
知乎:深度学习调参有哪些技巧?
初始化就跟黑科技一样,用对了超参都不用调;没用对,跑出来的结果就跟模型有bug一样不忍直视。
可视化与模型调试存在着极强的联系。
调参就是trial-and-error. 没有其他捷径可以走. 唯一的区别是有些人盲目的尝试, 有些人思考后再尝试. 快速尝试, 快速纠错这是调参的关键
1 刚开始,先上小规模数据,模型往大了放,直接奔着过拟合去。
2 Loss设计要合理,要注意loss的错误范围(主要是回归)。
3 观察loss胜于观察准确率
4 确认分类网络学习充分。网络慢慢从类别模糊到类别清晰的,如果网络预测分布靠近中间,再学习学习。
5 Learning Rate设置合理
6 对比训练集和验证集的loss
7 清楚receptive field的大小
多尺度的图片输入(或网络内部可以利用多尺度下的结果)有很好的提升效果
不像有fully connection的网络, 好歹有个fc兜底, 全局信息都有。fc作用就是可以把整张图的信息汇总,卷积本身一般没这个能力。
工程上更多从显而易见的地方入手,比如LR,比如数据本身有没有错漏,这些更有效率。
从业者通用的现状,80%的时间debug和tune,只有20%的时间搞数学或实现东西。
数据集构建的共同问题:
没有足够的数据
类别不平衡
噪声标签
训练集,测试集分布不同
数值不稳定(inf/NaN)经常随着exp, log, div操作的使用而出现。