微信公众号:生物信息学习
笔者邀请您,先思考:
1 线性回归是什么?
2 线性回归怎么应用?
本文解释了如何在R中运行线性回归。本教程将介绍线性回归的假设以及如果假设不满足如何处理。 它还包括拟合模型和计算模型性能指标以检查线性回归模型的性能。 线性回归是最流行的统计技术之一。 它已被使用了三十多年。 它几乎在每个领域都被广泛接受,因为它很容易理解线性回归的输出。
线性回归
它是一种发现称为一个连续的因变量或者目标变量与一个或者多个(连续或者不连续)的自变量之间的关系的方法论。
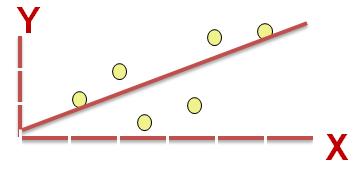
这是一条直线曲线。 在上图中,对角红线是一条回归线,也称为最佳拟合直线。 点与回归线之间的距离是误差(errors)。 线性回归旨在通过最小化点与回归线之间的垂直距离的平方和来找到最佳拟合直线。
变量类型
线性回归需要因变量是连续的,即数值(无类别或组)。
简单与元线性回归
当只有一个自变量时,线性回归是简单的线性回归(一元线性回归)。 而多元线性回归会有多个自变量。
回归方程
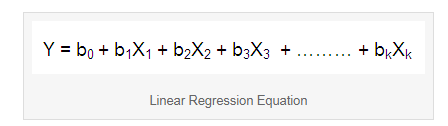
解释:
当所有自变量变量(Xs)等于0且时,b0是因变量(Y)的期望平均值的截距。b1是斜率,它代表因变量(Y)的变化量,如果我们改变X1一个单位保持其他变量不变。
重要术语:残差
观察到的(实际)因变量值与从回归线预测的因变量值之间的差异。
算法
线性回归基于最小二乘估计,其表示回归系数(估计值)应该以使每个观察到的响应与其拟合值的平方距离的总和最小化的方式来选择。
最小样本量
线性回归分析中需要每个自变量5个案例。
线性回归分析的假设
1.线性关系:线性回归需要依赖因变量和自变量之间的线性关系。
2.残差的正态性:线性回归需要残差应该正态分布。
3.同方差性:线性回归假定所有预测的因变量值的残差大致相等。换句话说,它意味着误差方差的不变性。
4.没有离群值问题
5.多重共线性:这意味着自变量之间有很高的相关性。线性回归模型不得面临多重共线性问题。
6.误差的独立性 - 无自相关
它指出,与一个观测相关的误差与任何其他观测的误差都不相关。当您使用时间序列数据时,这是一个问题。假设你从八个不同的地区收集了劳动者的数据。每个地区内的劳动力可能更倾向于来自不同地区的劳动力,也就是说,他们的错误不是独立的。
线性回归的分布
线性回归假设目标或因变量是正态分布的。 正态分布与高斯分布相同。 它使用高斯家族的连接函数。
标准化系数
标准化或标准化系数(估计)的概念出现在预测变量(又称自变量)以不同单位表示时。 假设你有3个独立变量 - 年龄,身高和体重。 变量“年龄”以年表示,身高以厘米为单位,体重以千克为单位。如果我们需要根据非标准化系数对这些预测因子进行排序,那么它们将不会是一个公平的比较,因为这些变量的单位并不相同。
标准化系数(或估计)主要用于排列预测变量(或自变量或解释变量),因为它消除了自变量和因变量的测量单位)。 我们可以用标准化系数的绝对值对自变量进行排序。 最重要的变量将具有最大的标准化系数绝对值。
标准化系数的解释
1.25的标准化系数值表示自变量中一个标准偏差的变化导致因变量增加1.25个标准偏差。
模型性能测量
1. R平方
它用模型中的所有自变量来解释因变量的方差比例。 它假定模型中的每个独立变量都有助于解释因变量的变化。 事实上,有些变量不会影响因变量,它们也无助于建立一个好的模型。
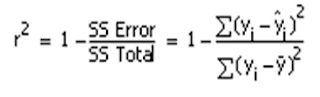 image
image
上述方程式的分子,yi-hat是预测值。 Y的平均值出现在分母中。
规则:
R平方越高,模型越适合您的数据。 在心理调查或研究中,我们通常发现低R平方值低于0.5。 这是因为我们试图预测人类行为,预测人类并不容易。 在这些情况下,如果您的R平方值很低,但您具有统计学上显着的独立变量(又称预测变量),您仍然可以生成关于预测变量值中的变化如何与响应值变化相关联的见解。
R平方可否为负?
是的,当水平线比您的模型更好地解释数据时。 它主要发生在你不包括截距的情况下。 没有截距,在预测目标变量方面,回归可能会比样本均值差。 这不仅是因为没有截距。 即使包含截距,它也可能是负的。
在数学上,当模型的误差平方大于水平线上的总平方和时,这是可能的。
R-squared = 1 - [(Sum of Square Error)/(Total Sum of Square)]
2.调整R平方
它衡量的只是那些真正影响因变量的自变量所解释的方差比例。 它惩罚你添加不影响因变量的自变量。

调整后的R-Squared比R-squared更重要
每次向模型添加自变量时,即使自变量不显着,R平方也会增加。 它永不衰落。 而调整R平方仅在自变量显著并且影响因变量时增加。
3. RMSE(均方根误差)
它解释了实际数据点与模型预测值的接近程度。 它测量残差的标准差。
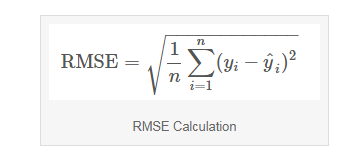
在上面的公式中,yi是因变量的实际值,yi-hat是预测值,n是样本大小。
很重要的一点
RMSE与因变量具有相同的单位。 例如,因变量是以美元计量的销售额。 假设这种销售模式的RMSE出来21.我们可以说它是21美元。
什么是好的RMSE分数?
没有关于好或坏RMSE评分的拇指规则。 这是因为它依赖于你的因变量。如果您的目标变量介于0到100之间。RMS的0.5可以认为是好的,但同样的0.5 RMSE可以被认为是差分,如果因变量的范围从0到10.因此,通过简单地查看 在价值。
较低的RMSE值表示更合适。 RMSE是衡量模型如何准确预测响应的一个很好的衡量标准,如果模型的主要目的是预测,那么它就是拟合最重要的标准。
如果您已经建立了良好的模型,那么您的训练和测试集的RMSE应该非常相似。 如果测试集的RMSE远高于训练集的RMSE,那么很可能是您的数据严重过拟合,即您创建了一个在样本中运行良好的模型,但在样本外的测试集上几乎没有预测价值。
RMSE与MAE
与平均绝对误差(MAE)相比,RMSE严格惩罚大的误差。
R平方与RMSE
R平方是个比例并且没有与目标变量相关联的单位,而RMSE具有与目标变量相关的单位。 因此,R平方是拟合的相对度量,RMSE是拟合的绝对度量。
下面的代码涵盖了对模型性能的假设测试和评估:
- 数据准备
- 多重共线性检验
- 多重共线性的处理
- 检查自相关
- 检查异常值
- 检查异方差
- 残差的正态性检验
- 前进,后退和逐步选择
- 计算RMSE
- 因变量的Box Cox变换
- 手动计算R平方和调整R平方
- 计算残差和预测值
- 计算标准化系数
R脚本:线性回归
理论部分结束了。 让我们用R -
加载所需的包
library(ggplot2)
library(car)
library(caret)
library(corrplot)
确保上面列出的软件包已经安装并加载到R中。如果它们尚未安装,则需要使用命令install.packages(“package-name”)进行安装。
读取数据
我们将使用cars包中的mtcars数据集。 这些数据摘自Motor Trend US杂志,包括32种汽车的燃料消耗和10个方面的汽车设计和性能。
data(mtcars)
str(mtcars)
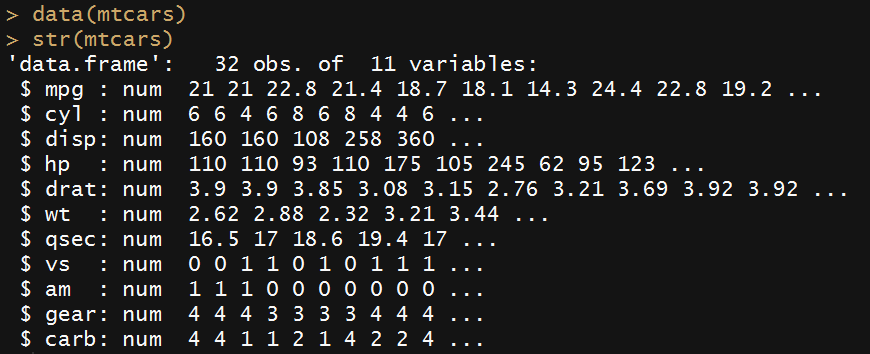
以上变量的变量描述将在下面列出它们各自的变量名称。

数据摘要
在这个数据集中,mpg是一个目标变量。 使用head()函数查看前6行数据。
head(mtcars)
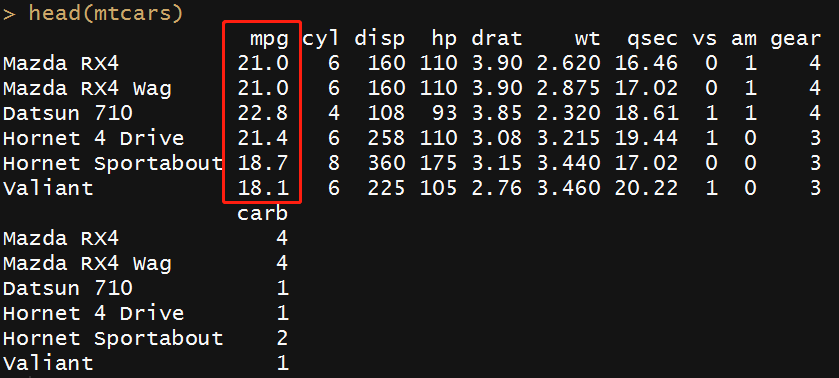
要查看变量的分布情况,请使用summary()函数。
summary(mtcars)
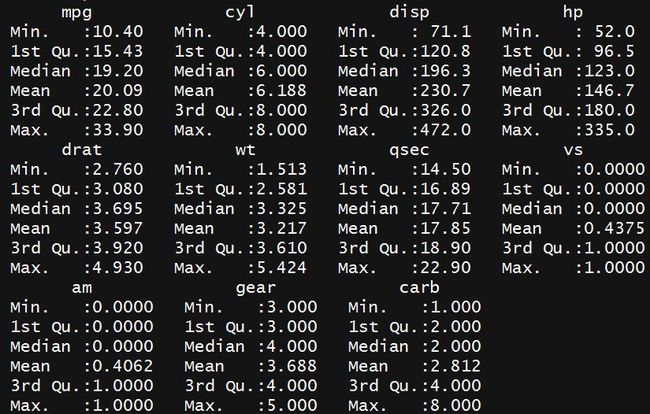
数据准备
确保分类变量存储为因子。 在下面的程序中,我们将变量转换为因子。
mtcars$am <- as.factor(mtcars$am)
mtcars$cyl <- as.factor(mtcars$cyl)
mtcars$vs <- as.factor(mtcars$vs)
mtcars$gear <- as.factor(mtcars$gear)
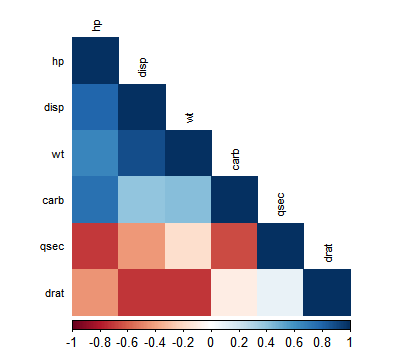
识别和修正共线性
在这一步中,我们正在识别彼此高度相关的自变量。 由于mpg是一个因变量,我们将在下面的代码中删除它。
mtcars_a <- subset(mtcars, select = -c(mpg))
numericData <- mtcars_a[sapply(mtcars_a, is.numeric)]
descrCor <- cor(numericData)
print(descrCor)

corrplot(
descrCor,
order = "FPC",
method = "color",
type = "lower",
tl.cex = 0.7,
tl.col = rgb(0,0,0)
)
highlyCorrelated <- findCorrelation(descrCor, cutoff=0.7)
highlyCorCol <- colnames(numericData)[highlyCorrelated]
dat3 <- mtcars[, -which(colnames(mtcars) %in% highlyCorCol)]
dim(dat3)
有三个变量“hp”“disp”“wt”被发现是高度相关的。 我们已经删除它们以避免共线。 现在,我们有7个独立变量和1个因变量。
开发回归模型
在这一步,我们正在建立多元线性回归模型。
fit <- lm(mpg ~ ., data=dat3)
summary(fit)
summary(fit)$coeff
anova(fit)
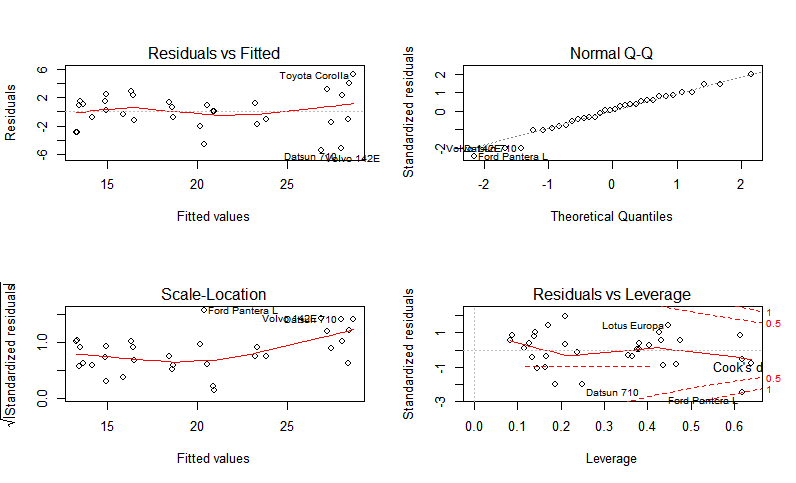
par(mfrow=c(2,2))
plot(fit)
查看线性回归模型的系数和ANOVA表
性回归模型测试估计等于零的零假设。 具有小于0.05的p值的独立变量意味着我们拒绝5%显着性水平的零假设。这意味着该变量的系数不等于0.大p值意味着变量对预测目标变量没有意义。
summary(fit)
anova(fit)
线性回归模型的关键图如下所示 :-
- 残留物与拟合值
- 正常Q-Q
- 缩放位置
- 残差与杠杆
计算模型性能度量
summary(fit)$r.squared
summary(fit)$adj.r.squared
AIC(fit)
BIC(fit)
更高的R平方和调整的R平方值,更好的模型。 然而,更低的AIC和BIC得分,更好的模型。
理解AIC和BIC
AIC和BIC是拟合度的衡量标准。 他们惩罚复杂的模型。 换句话说,它会惩罚更多的估计参数。 它相信一个概念,即一个具有较少参数的模型将被一个具有更多参数的模型要好。 一般来说,BIC比AIC更为免费参数惩罚模型。 两个标准都取决于估计模型的似然函数L的最大值。
AIC值大致等于参数的数量减去整个模型的似然性。 假设你有两个模型,AIC和BIC分数较低的模型更好。
变量选择方法
有三种变量选择方法 - 向前,向后,逐步。
1.以单个变量开始,然后基于AIC(“前进”)一次添加一个变量
2.从所有变量开始,基于AIC(’后退’)迭代地去除那些重要性低的变量
3.双向运行(’逐步’)
library(MASS)
step <- stepAIC(fit, direction="both")
summary(step)
step <- stepAIC(fit, direction="forward")
summary(step)
n <- dim(dat3)[1]
stepBIC <- stepAIC(fit,k=log(n))
summary(stepBIC)
在基于BIC执行逐步选择之后,查看以上估计值。 变量已经减少,但调整后的R-Squared保持不变(稍微改善)。 AIC和BIC分数也下降,这表明一个更好的模型。
AIC(stepBIC)
BIC(stepBIC)
计算标准化系数
标准化系数有助于根据标准化估计值的绝对值排列预测值。 值越高,变量越重要。
#使用QuantPsyc包的lm.beta函数计算
library(QuantPsyc)
lm.beta(stepBIC)
#自定义函数计算
stdz.coff <- function (regmodel)
{ b <- summary(regmodel)$coef[-1,1]
sx <- sapply(regmodel$model[-1], sd)
sy <- sapply(regmodel$model[1], sd)
beta <- b * sx / sy
return(beta)
}
std.Coeff <- data.frame(Standardized.Coeff = stdz.coff(stepBIC))
std.Coeff <- cbind(Variable = row.names(std.Coeff), std.Coeff)
row.names(std.Coeff) <- NULL
计算方差膨胀因子(VIF)
与独立变量高度相关的情况相比,差异膨胀因子衡量的是系数的变化幅度。 它应该小于5。
vif(stepBIC)
测试其它假设
#Autocorrelation Test
durbinWatsonTest(stepBIC)
#Normality Of Residuals (Should be > 0.05)
res=residuals(stepBIC,type="pearson")
shapiro.test(res)
#Testing for heteroscedasticity (Should be > 0.05)
ncvTest(stepBIC)
#Outliers – Bonferonni test
outlierTest(stepBIC)
#See Residuals
resid = residuals(stepBIC)
#Relative Importance
install.packages("relaimpo")
library(relaimpo)
calc.relimp(stepBIC)
查看实际值和预测值
#See Predicted Value
pred <- predict(stepBIC,dat3)
#See Actual vs. Predicted Value
finaldata <- cbind(mtcars,pred)
print(head(subset(finaldata, select = c(mpg,pred))))
其它有用的函数
#Calculating RMSE
rmse = sqrt(mean((dat3$mpg - pred)^2))
print(rmse)
#Calculating Rsquared manually
y = dat3[,c("mpg")]
R.squared = 1 - sum((y-pred)^2)/sum((y-mean(y))^2)
print(R.squared)
#Calculating Adj. Rsquared manually
n = dim(dat3)[1]
p = dim(summary(stepBIC)$coeff)[1] - 1
adj.r.squared = 1 - (1 - R.squared) * ((n - 1)/(n-p-1))
print(adj.r.squared)
#Box Cox Transformation
library(lmSupport)
modelBoxCox(stepBIC)
K-fold交叉验证
在下面的程序中,我们正在进行5倍交叉验证。 在5倍交叉验证中,数据被随机分成5个相同大小的样本。 在5个样本中,随机20%数据的单个样本保留为验证数据,其余80%用作训练数据。 然后这个过程重复5次,5个样本中的每一个都只用作验证数据一次。 稍后我们将结果平均。
library(DAAG)
kfold = cv.lm(data=dat3, stepBIC, m=5)
完整代码
library(ggplot2)
library(car)
library(caret)
library(corrplot)
data(mtcars)
str(mtcars)
head(mtcars)
summary(mtcars)
mtcars$am <- as.factor(mtcars$am)
mtcars$cyl <- as.factor(mtcars$cyl)
mtcars$vs <- as.factor(mtcars$vs)
mtcars$gear <- as.factor(mtcars$gear)
mtcars_a <- subset(mtcars, select = -c(mpg))
numericData <- mtcars_a[sapply(mtcars_a, is.numeric)]
descrCor <- cor(numericData)
print(descrCor)
corrplot(
descrCor,
order = "FPC",
method = "color",
type = "lower",
tl.cex = 0.7,
tl.col = rgb(0,0,0)
)
highlyCorrelated <- findCorrelation(descrCor, cutoff=0.7)
highlyCorCol <- colnames(numericData)[highlyCorrelated]
dat3 <- mtcars[, -which(colnames(mtcars) %in% highlyCorCol)]
dim(dat3)
fit <- lm(mpg ~ ., data=dat3)
summary(fit)
summary(fit)$coeff
anova(fit)
par(mfrow=c(2,2))
plot(fit)
summary(fit)$r.squared
summary(fit)$adj.r.squared
AIC(fit)
BIC(fit)
library(MASS)
step <- stepAIC(fit, direction="both")
summary(step)
step <- stepAIC(fit, direction="forward")
summary(step)
n <- dim(dat3)[1]
stepBIC <- stepAIC(fit,k=log(n))
summary(stepBIC)
AIC(stepBIC)
BIC(stepBIC)
library(QuantPsyc)
lm.beta(stepBIC)
stdz.coff <- function (regmodel)
{ b <- summary(regmodel)$coef[-1,1]
sx <- sapply(regmodel$model[-1], sd)
sy <- sapply(regmodel$model[1], sd)
beta <- b * sx / sy
return(beta)
}
std.Coeff <- data.frame(Standardized.Coeff = stdz.coff(stepBIC))
std.Coeff <- cbind(Variable = row.names(std.Coeff), std.Coeff)
row.names(std.Coeff) <- NULL
vif(stepBIC)
#Autocorrelation Test
durbinWatsonTest(stepBIC)
#Normality Of Residuals (Should be > 0.05)
res=residuals(stepBIC,type="pearson")
shapiro.test(res)
#Testing for heteroscedasticity (Should be > 0.05)
ncvTest(stepBIC)
#Outliers – Bonferonni test
outlierTest(stepBIC)
#See Residuals
resid = residuals(stepBIC)
#Relative Importance
install.packages("relaimpo")
library(relaimpo)
calc.relimp(stepBIC)
#See Predicted Value
pred <- predict(stepBIC,dat3)
#See Actual vs. Predicted Value
finaldata <- cbind(mtcars,pred)
print(head(subset(finaldata, select = c(mpg,pred))))
来自搜狐网:https://www.sohu.com/a/230584172_274950
