最近一段时间也写过不少简单的爬虫,但是觉得之前做的仅仅是换个网站,重写下解析过程,最后保存下数据就完了。爬的次数多了,基本套路也懂了,所以开始思考如何去改造简单的爬虫,使得爬虫更快,效率更高,规模更大,稳定性更强。这是接下来我想要深入学习的一个方向 。
任务
待抓取网站是美股吧,需要抓取的数据是:帖子浏览数、帖子标题、帖子内容 、评论数 、评论人、 评论时间、 评论内容。
http://guba.eastmoney.com/list,meigu.html
网站分析
1.导航页
图片上的导航页URL是http://guba.eastmoney.com/list,meigu_2.html
可以发现url后面的2就是页码,想要分页获取仅仅需要改变下页码就行了。
然后在这里就可以吧阅读数,评论数,帖子标题,作者,发布时间给提取出来。
另外还需要获取对应帖子的url,也要在这里解析出来,下一步才能请求详情页的数据。
因为之前对beautifulsoup不熟,所以代码里我就用了bs4来练习。

"""请求网站的首页,获取首页上的帖子数据"""
def request_title(title_page=1):
title_url = "http://guba.eastmoney.com/list,cjpl_" + str(title_page) + ".html"
return request('get', title_url, timeout=5)
"""解析首页上帖子的标题数据,包括阅读数,评论数,标题,作者,发布时间,评论的总页数"""
def parse_title(text):
article_list = []
soup = BeautifulSoup(text, 'lxml')
host_url = 'http://guba.eastmoney.com'
elem_article = soup.find_all(name='div', class_='articleh')
for item in elem_article:
article_dict = {'read_count': '', 'comment_count': '', 'page': '', 'title': '', 'tie': '', 'author': '',
'time': '', 'link': '','link_id':'', 'comment': ''}
article_dict['read_count'] = item.select_one("span.l1").text
article_dict['comment_count'] = item.select_one("span.l2").text
article_dict['page'] = int(math.ceil(int(article_dict['comment_count']) / 30.0))
article_dict['title'] = item.select_one("span.l3 > a").text
article_dict['author'] = item.select_one("span.l4 > a").text if item.select_one("span.l4 > a") else u'匿名作者'
article_dict['time'] = item.select_one("span.l5").text
href = item.select_one("span.l3 > a").get("href")
article_dict['link'] = host_url + href if href[:1] == '/' else host_url + '/' + href
article_dict['comment'] = []
article_list.append(article_dict)
return article_list
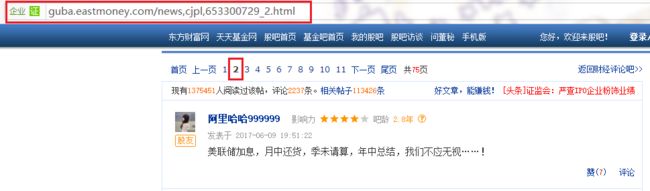
2. 帖子详情页
- 详情页这里的url中http://guba.eastmoney.com/news,cjpl,653300729_2.html
也能发现分页的规律,下划线后的2就是页码数。
"""请求评论页的数据"""
def request_comment(tie):
"""跳过一些不是帖子的链接"""
if re.compile(r'news,cjpl').search(tie['link']) == None:
return
print(tie['link']+' '+threading.currentThread().name)
for comment_url in get_comment_urls(tie):
text = request('get', comment_url, timeout=5)
parse_comment(text, tie)
"""解析出评论页的数据,包括作者,时间,评论内容和计算评论楼层"""
def parse_comment(text, tie):
soup = BeautifulSoup(text, 'lxml')
if (soup.find(name='div', id='zw_body')):
tie['tie'] = soup.find(name='div', id='zw_body').text.replace(u'\u3000', u'')
div_list = soup.find(id="mainbody").find_all(name='div', class_="zwlitxt")
for item in div_list:
comment_info = {"author": '', "time": '', "article": ''}
comment_info['author'] = item.find(name='span', class_="zwnick").text
comment_info['time'] = item.find(name='div', class_="zwlitime").text[3:]
if (item.find(name='div', class_="zwlitext stockcodec")):
comment_info['article'] = item.find(name='div', class_="zwlitext stockcodec").text
comment_info['article'] = u"没有评论内容" if comment_info['article'] == '' else comment_info['article']
else:
comment_info['article'] = u"没有评论内容"
tie['comment'].append(comment_info)
- 评论总页数的获取,在这个页面上无法通过解析页面获取,需要通过计算评论数 / 每页30条评论,然后使用math.ceil向上取整,就能得到评论总页数,然后就能分页,构造出请求评论的url了。注意30.0必须要带小数点.
article_dict['page'] = int(math.ceil(int(article_dict['comment_count']) / 30.0))
关于math.ceil()这个向上取整的函数有个坑要注意。
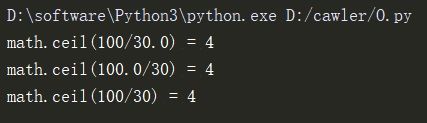
举个例子,分别在python2.7和python3.6环境下运行下面代码:
import math
print("math.ceil(100/30.0) =",math.ceil(100/30.0))
print("math.ceil(100.0/30) =",math.ceil(100.0/30))
print("math.ceil(100/30) =",math.ceil(100/30))
结果就是python3.6下非常正确的输出了结果4。
而python2.7下输出的都是浮点数,而且math.ceil(100/30)的结果还出错了,变成了3。
这就会使得抓取过程中出现了最后一页的评论数据没有抓取到的bug。
分析原因,计算是分两步进行的,math.ceil(100/30)先计算的是两个整数相除输出的会是整数3,然后再调用math.ceil()结果当然也会是3啦。如果其中有一个是浮点数,那么除法运算出来的也会是浮点数,这时候结果就不会出错。
python3可能是对此做了优化,这也算的上是一点环境差异吧。

-
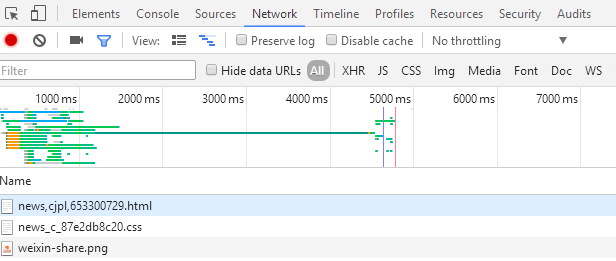
关于在这个页面中使用bs4和xpath获取不到阅读数、评论数、页数的原因分析。
- 猜测可能是js异步加载的问题。
先F12> network,先去js的响应里面找找看,经过一番查找后,却一无所获。
凡是浏览器中能显示出来的数据,一定是从某个响应加载或计算出来的,不可能凭空出现。
在找不到想要的数据时不要放弃,一定要坚信这一点。换个思路去其他地方看看。
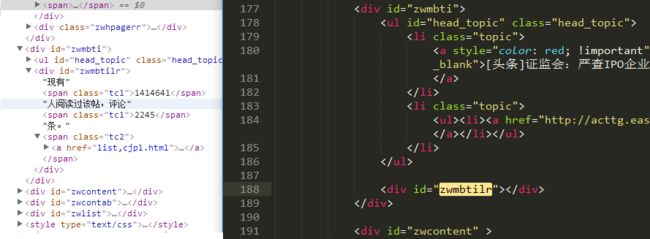
2.为了方便分析,先将请求到的news,cjpl,653300729.html文件右键 > save保存下来。
下图左边是浏览器,右边是文本编辑器打开的html文件,发现
里边应存在的评论和阅读数据,在这里看不到。
3.尝试搜索下评论数2245,看到下面的代码,相信已经真相大白了。
{var num=1414368; }var pinglun_num=2245 num就是阅读数,pinglun_num就是评论数
其实这段JS代码就是用document.getElementById("zwmbtilr").innerHTML
往zwmbtilr中动态加载了阅读数和评论数的元素,所以前面的那块地方就是空的。
所以这段JS代码使用bs4和xpath是取不到数据的,想要在这里取出来必须使用正则。

关于评论总页数的问题,实际上是根据下面自定义的规则计算出来的,2245是评论数,30是每页的评论数,1表示第一次进入时默认跳到的页数,也就是第1页,可以修改网页中这些数据看到效果。
news,cjpl,653300729_|2245|30|1
爬取数据的结果
 comment.png
comment.png
多线程
限于篇幅原因,多线程内容在这篇文章里。美股吧多线程爬虫(二)
参考链接:
@[dpkBat] http://www.jianshu.com/p/7738865f04e8