tidb1.0开始支持spark,有个组件tiSpark,不过目前只支持spark2.1版本。所以为了启用tiSpark,还需搭建spark集群。
在官网下载地址http://spark.apache.org/downloads.html上,我找到了with hadoop的版本。如下图:

下载地址: https://d3kbcqa49mib13.cloudfront.net/spark-2.1.1-bin-hadoop2.7.tgz
目前手中有4台资源
决定选用其中三台搭建spark集群,一台master,两台slave
链接如下:
| 域名 | IP | 主从关系 |
|---|---|---|
| tidb1 | 192.168.122.16 | Master |
| tidb2 | 192.168.122.18 | Slave |
| tidb3 | 192.168.122.19 | Slave |
顺便说一下,centos7的hostname设定和之前版本已经不一样了。现在只需输入以下命令指定
hostnamectl set-hostname name
name就是你需要指定的hostname
将压缩包下载后,分别上传至三台server的/usr/local目录下,并解压
cd /usr/local
tar zxvf spark-2.1.1-bin-hadoop2.7.tgz
准备
在搭建集群环境之前,首先要做的事情是让这三台机器可以互相免密登陆
编辑/etc/hosts
编辑三台server的/etc/hosts
编辑后内容如下:
#127.0.0.1 localhost tidb1 localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
#216.176.179.218 mirrorlist.centos.org
192.168.122.16 tidb1
192.168.122.18 tidb2
192.168.122.19 tidb3
注意:第一行一定要注释,我在安装过程中,spark启动后,日志文件报错,就是因为它没有去找我下面指定的ip和域名,而是老是去连接127.0.0.1
然后让它们生效
source /etc/hosts
安装ssh和rsync
可以通过下面命令查看是否已经安装:
rpm -qa|grep openssh
rpm -qa|grep rsync
如果没有安装ssh和rsync,可以通过下面命令进行安装:
yum install ssh
yum install rsync
service sshd restart
配置Master无密码登录所有Salve
tidb1节点的配置操作
以下是在tidb1节点的配置操作。
1)在tidb1节点上生成密码对,在tidb1节点上执行以下命令:
ssh-keygen -t rsa -P ''
生成的密钥对:id_rsa和id_rsa.pub,默认存储在"/root/.ssh"目录下。
2)接着在tidb1节点上做如下配置,把id_rsa.pub追加到授权的key里面去
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
3)修改ssh配置文件"/etc/ssh/sshd_config"的下列内容,将以下内容的注释去掉
# 启用 RSA 认证
RSAAuthentication yes
# 启用公钥私钥配对认证方式
PubkeyAuthentication yes
# 公钥文件路径(和上面生成的文件同)
AuthorizedKeysFile .ssh/authorized_keys
4)重启ssh服务,才能使刚才设置有效。
service sshd restart
5)验证无密码登录本机是否成功
ssh tidb1
6)接下来的就是把公钥复制到所有的Slave机器上。使用下面的命令进行复制公钥:
scp /root/.ssh/id_rsa.pub root@tidb2:/root/
scp /root/.ssh/id_rsa.pub root@tidb3:/root/
tidb2节点的配置操作
1)在"/root/"下创建".ssh"文件夹,如果已经存在就不需要创建了
mkdir /root/.ssh
2)将tidb1的公钥追加到tidb2的授权文件"authorized_keys"中去
cat /root/id_rsa.pub >> /root/.ssh/authorized_keys
3)修改ssh配置文件"/etc/ssh/sshd_config"的下列内容,将以下内容的注释去掉
# 启用 RSA 认证
RSAAuthentication yes
# 启用公钥私钥配对认证方式
PubkeyAuthentication yes
# 公钥文件路径(和上面生成的文件同)
AuthorizedKeysFile .ssh/authorized_keys
4)重启ssh服务,才能使刚才设置有效
service sshd restart
5)切换到tidb1使用ssh无密码登录tidb2
ssh tidb2
6)把"/root/"目录下的"id_rsa.pub"文件删除掉
rm –r /root/id_rsa.pub
tidb3节点的配置操作
1)在"/root/"下创建".ssh"文件夹,如果已经存在就不需要创建了
mkdir /root/.ssh
2)将tidb1的公钥追加到tidb3的授权文件"authorized_keys"中去
cat /root/id_rsa.pub >> /root/.ssh/authorized_keys
3)修改ssh配置文件"/etc/ssh/sshd_config"的下列内容,将以下内容的注释去掉
# 启用 RSA 认证
RSAAuthentication yes
# 启用公钥私钥配对认证方式
PubkeyAuthentication yes
# 公钥文件路径(和上面生成的文件同)
AuthorizedKeysFile .ssh/authorized_keys
4)重启ssh服务,才能使刚才设置有效
service sshd restart
5)切换到tidb1使用ssh无密码登录tidb3
ssh tidb3
6)把"/root/"目录下的"id_rsa.pub"文件删除掉
rm –r /root/id_rsa.pub
配置所有Slave无密码登录Master
tidb2节点的配置操作
1)创建tidb2自己的公钥和私钥,并把自己的公钥追加到"authorized_keys"文件中,执行下面命令
ssh-keygen -t rsa -P ''
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
2)将tidb2节点的公钥"id_rsa.pub"复制到tidb1节点的"/root/"目录下
scp /root/.ssh/id_rsa.pub root@tidb1:/root/
tidb1节点的配置操作
1)将tidb2的公钥追加到tidb1的授权文件"authorized_keys"中去
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
2)删除tidb2复制过来的"id_rsa.pub"文件
rm –r /root/id_rsa.pub
配置完成后测试从tidb2到tidb1无密码登录
ssh tidb1
tidb3节点的配置操作
1)创建tidb3自己的公钥和私钥,并把自己的公钥追加到"authorized_keys"文件中,执行下面命令:
ssh-keygen -t rsa -P ''
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
2)将tidb3节点的公钥"id_rsa.pub"复制到tidb1节点的"/root/"目录下
scp /root/.ssh/id_rsa.pub root@tidb1:/root/
tidb1节点的配置操作。
1)将tidb3的公钥追加到tidb1的授权文件"authorized_keys"中去
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
2)删除tidb3复制过来的"id_rsa.pub"文件
rm –r /root/id_rsa.pub
配置完成后测试从tidb3到tidb1无密码登录。
ssh tidb1
spark集群搭建
进入到Spark安装目录
cd /usr/local/spark-2.1.1-bin-hadoop2.7
进入conf目录并重命名并修改spark-env.sh.template文件
cd conf/
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
在该配置文件中添加如下配置
export JAVA_HOME=/usr/local/jdk18121
export SPARK_MASTER_IP=tidb1
export SPARK_MASTER_PORT=7077
保存退出
重命名并修改slaves.template文件
mv slaves.template slaves
vi slaves
在该文件中添加子节点所在的位置(Worker节点)
tidb2
tidb3
保存退出
配置环境变量:
vim /etc/profile
#set spark env
export SPARK_HOME=/usr/local/spark-2.1.1-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile
将配置好的Spark拷贝到其他节点上
cd /usr/local
scp -r spark-2.1.1-bin-hadoop2.7 root@tidb2:$PWD
scp -r spark-2.1.1-bin-hadoop2.7 root@tidb3:$PWD
Spark集群配置完毕,目前是1个Master,2个Worker,在tidb1上启动Spark集群
/usr/local/spark-2.1.1-bin-hadoop2.7/sbin/start-all.sh
启动后,控制台显示如下

在浏览器中访问tidb1:8080端口,可见启动后情况,如下图

关闭集群可用如下命令
/usr/local/spark-2.1.1-bin-hadoop2.7/sbin/stop-all.sh
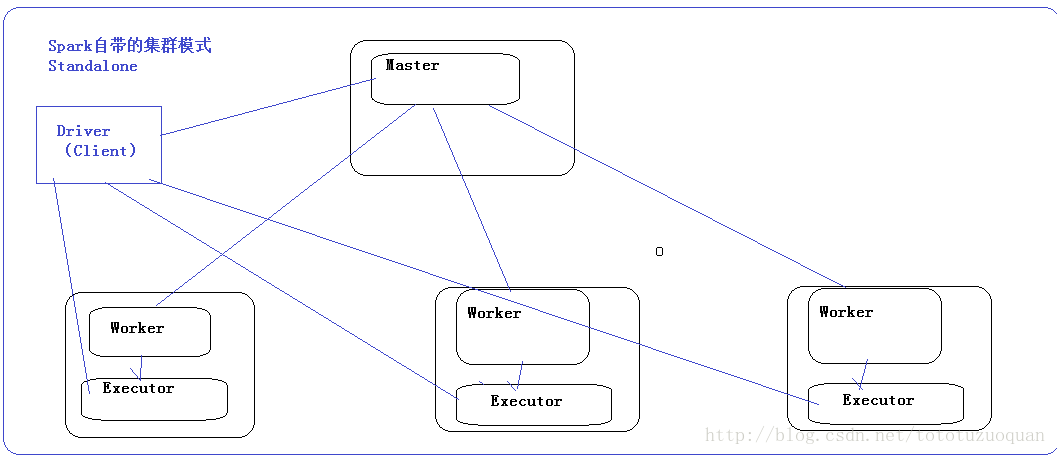
总结
简单介绍一下Spark集群的工作模式
首先启动一个Master(我这里是tidb1),然后Master和各个Worker(我这里是tidb2和tidb3)进行通信,其中真正干活的是Worker下的Executor。
我们还需要有一个客户端,这个客户端叫做Driver。它首先和Master建立通信,然后Master负责资源分配,接着让Worker启动Executor,最后让Executor和Driver进行通信。
效果图如下: