什么是ByteBuf
Netty提供了强大的随机和顺序访问零字节或多个字节的序列,为一个或多个原始的字节数组和JDK中NIO包下的ByteBuffer提供了抽像视图
通俗的理解就是一个byte数组的缓冲区
如何创建
推荐创建buffer的方式是使用Pooled或Unpooled类静态方法,而不是通过调用构造器的方式
这里以Unpooled类为例:
- 创建一个
初始容量为256,最大容量为Integer.MAX_VALUE的字节缓冲区
Unpooled.buffer();
- 创建一个
自定义初始容量大小,最大容量为Integer.MAX_VALUE的字节缓冲区
Unpooled.buffer(int initialCapacity);
- 创建一个
初始容量为256,最大容量为Integer.MAX_VALUE的直接字节缓冲区
Unpooled.directBuffer()
- 创建一个
自定义初始容量大小,最大容量为Integer.MAX_VALUE的直接字节缓冲区
Unpooled.directBuffer(int initialCapacity)
如何使用
1. 随机访问
ByteBuf使用了从0开始的索引,就像普通的原始字节数组一样,这意味着第一个字节的索引总是0,而最后一个字节的索引总是capacity - 1
例如,迭代所有缓冲区中的字节,可以使用类似如下的代码
ByteBuf buffer = ...;
for (int i = 0; i < buffer.capacity(); i ++){
byte b = buffer.getByte(i);
System.out.println((char) b);
}
2. 顺序访问
ByteBuf 提供了
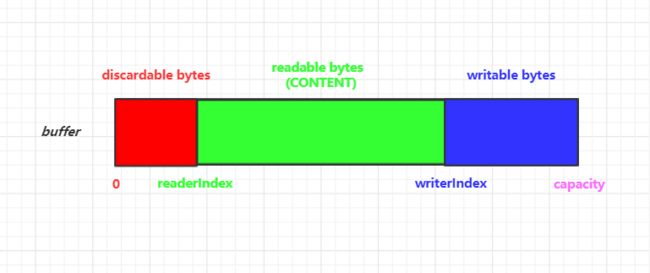
两个指针变量来支撑顺序读和写操作,即readerIndex和writeIndex
我们用一张图来展示一个缓冲区是如何通过这两个指针变量被分割成三个区域的
3. 可读(Readable)字节
可读字节又称
真实字节内容,表示的是实际被存储在缓冲区中的数据,任何以read或skip开头的操作都将会获得和跳过从当前readerIndex索引的数据,然后根据读取字节的数量来增加这个索引值
如果读操作的参数也是一个ByteBuf,并且没指定目标索引,那么该参数buffer的writerIndex值将亦随之增加,意思就是调用read方法的buffer字节数组缓冲区中的字节数据会被读出来再写入进参数buffer中,所以参数buffer缓冲区的writerIndex值会增加
需要注意的是,一个新分配,包装或复制的缓冲区的readerIndex值是0
迭代缓冲区的可读字节代码示例:
while (buffer.isReadable()) {
System.out.println(buffer.readByte());
}
4. 可写(Writable)字节
这是一个
需要被填充的未定义的空间,任何以write开头命名的操作都将从当前的writeIndex写入数据,并根据被写入数据的字节数量来增加该writeIndex的值
如果写操作的参数也是一个ByteBuf,并且没指定源索引,那么该参数buffer的readerIndex值将亦随之增加,意思就是参数buffer中的字节数据会被读出来再写入进调用write方法的buffer中
此外值得注意的是,一个新分配(allocated)buffer的默认writeIndex值为0,而包装或拷贝(wrapped/copied)的缓冲区的默认writeIndex值为该buffer缓冲区的容量的大小即capacity
下面是一个用随机整数填充buffer可写字节的代码示例:
ByteBuf buffer = ...;
// maxWritableBytes方法是返回该buffer最大可写字节的数量
// 因为int类型在Java中占用4个字节,故这里>=4即代表可以写一
// 个int值进buffer中
while (buffer.maxWritableBytes() >= 4) {
buffer.writeInt(random.nextInt());
}
这里简单提一下buffer.maxWritableBytes()方法的判断依据,其实就是根据buffer的maxCapacity - writeIndex的值
5. 可废弃(Discardable)字节
所谓可废弃字节就是指那些
已经被读操作读过的字节,最初的时候,可废弃字节段的大小是0。但是当读操作被执行时,可废弃字节段的大小会随着读操作一直增加到writeIndex
需要注意的是我们可以通过调用discardReadByted()方法来丢弃0索引至readerIndex索引之间的字节,我们可以通过上面画出的buffer图来理解
6. 清除(Clear)buffer缓冲区索引
通过调用clear()方法,可以同时设置readerIndex和writeIndex值为0,但是这仅仅只是设置这两个指针的值,并不是真的清除缓冲区的数据内容
7. 搜索(For Search)操作
对于简单的单字节搜索,使用indexOf(...) 和 bytesBefore(...)是尤其有用的
对于复杂搜索而言,需要使用forEachByte(...)函数完成,该函数有一个ByteProcessor类型的字节处理器参数
8. 标记和重置(Mark and reset)
每一个buffer都有两个标记索引,一个用来存储readerIndex,一个用来存储writeIndex
我们总是可以通过调用一个重置方法(reset)来重新定位这两个索引,他们的工作方式和InputStream的mark和reset方法很相似,除了没有读限制而已
9. 派生缓冲区(Derived buffers)
我们可以通过以下方法创建一个已存在缓冲区的视图,派生方法分非保留以及保留两类
- 非保留派生
duplicate()
slice()以及slice(int, int)
readSlice()
- 保留派生
retainedDuplicate()
retainedSlice()以及retainedSlice(int, int)
readRetainedSlice(int)
注意以上方法只是返回一个已存在缓冲区的视图而已,所谓视图就是一种新的展示形式,一个派生的缓冲区将会有一个独立的readerIndex,writerIndex以及标记索引(marker indexs),同时会共享其他内部数据表示
如果需要一个对于已存在缓冲区的完全拷贝,需要调用copy()方法
非保留和保留的区别
非保留的派生方法不会再返回的派生缓冲区的基础上调用retain()方法,因此它的引用计数不会增加
如果你需要去创建一个增加引用计数的派生缓冲区,就考虑使用retained开头的保留派生方法,如retainedDuplicate()等,保留方式派生的缓冲区会带来更少的垃圾回收
10. 和现有JDK类型的转换
实际开发中,经常会涉及到将ByteBuf和已有JDK类型之间的转换
- NIO Buffers之间的转换
可以通过nioBuffer()方法实现与NIO ByteBuffer之间的转换,但是需要注意的是返回的ByteBuffer将会共享或包含该buffer拷贝的数据,即当我们改变返回的NIO ByteBuffer的指针和limit的时候,并不会影响到原来的ByteBuf的索引和标记
- Strings之间转换
通过各种各样的toString(Chartset)方法来将一个ButeBuf转换为一个String,注意不是Object类型的toString() 方法哦
- I/O Streams之间的转换
通过ByteBufOutputStream和ByteBufInputStream实现
如何分类
既然是一个缓冲区,那么就会涉及到两点,内存
分配/回收效率以及如何优化内存资源使用
下面分别基于这两个视角来分类ByteBuf
分配/回收效率角度
从内存分配的角度看,ByteBuf可以分为两类
- 堆内
堆内分配的字节缓冲区的优点是内存分配和回收速度快,因为其基于JVM的分配和回收,不需要发生系统调用
而缺点方面,如果是进行网络IO操作,会存在二次内存复制(JVM会先将堆内缓冲区先copy到堆外直接内存,再从堆外直接内存copy数据到内核的Socket缓冲区),性能方面会有所下降
- 堆外
堆外内存又称直接内存,其直接受操作系统管理(而不是JVM)
Java堆外内存分配的字节缓冲区对象,会先通过Unsafe类的接口直接调用os::malloc来分配内存,然后返回分配到的内存的起始地址和大小,并利用java.nio.DirectByteBuffer对象保存这些值
这样就可以利用DirectByteBuffer对象直接操作直接内存,这些内存只有在DirectByteBuffer对象被回收掉之后才有机会被os回收,因此如果这些对象大部分都移到了old区,但是一直没有触发CMS GC或Full GC,那么悲剧将会发生,因为你的物理内存被他们耗尽了,因此为了避免这种悲剧的发生,通过-XX:MaxDirectMemorySize来指定最大的堆外内存大小,当使用达到了阈值的时候将调用System.gc来做一次full gc,以此来回收掉被使用的堆外内存
那使用直接内存的好处就是对于网络IO,节省了一次内存复制操作,无需将堆内数据先copy到堆外(native堆),而是直接从native堆(堆外)将数据copy到网络socket缓冲区发送即可
| 分类 | 优点 | 缺点 |
|---|---|---|
| 堆内 | 分配和回收速度快,易于控制 | 对于网络IO操作,存在二次内存复制 |
| 堆外 | 对于网络IO操作,少一次内存复制,速度快 | 容易存在内存泄露,难以控制 |
优化内存资源使用角度
无论何时,内存都是宝贵的资源,试想如果我们不限制的创建(分配内存空间)字节缓冲区ByteBuf的话,将是多么的浪费资源
因此有了池化和非池化的区别,这里可以类比线程池的设计思路
- 基于对象池(
Pooled)的ByteBuf
优点是可以重用ByteBuf对象,提升内存使用效率的同时又避免了频繁的分配和回收内存开销
缺点则是使用内存池会增加管理和维护的复杂性
- 基于非对象池(
Unpooled)的ByteBuf
优点是使用简单,维护简单,缺点则是GC或操作系统负担重
| 分类 | 优点 | 缺点 |
|---|---|---|
| Pooled 池化 | 重用ByteBuf对象,提升内存使用效率且避免了频繁的分配和回收内存开销 | 增加管理和维护的复杂性 |
| Unpooled 非池化 | 使用简单 | GC负担重 |
OK,ByteBuf的基本使用介绍完以后,下面我们将基于源码对ButeBuf的实现原理进行深入的分析
源码
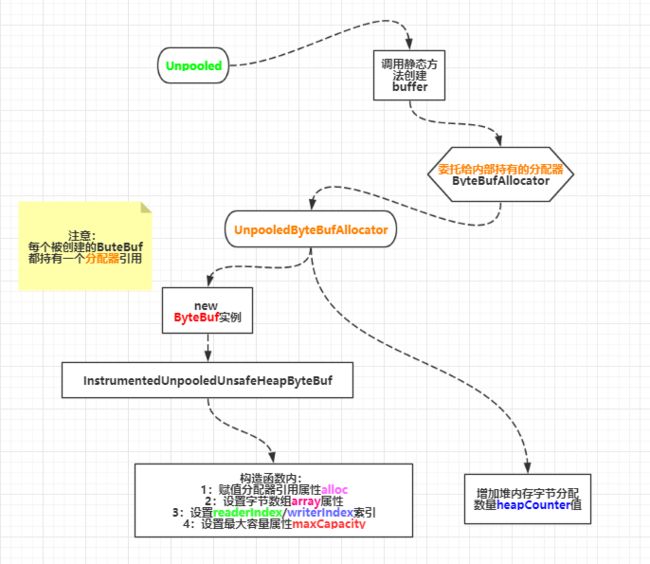
基于ByteBuf的创建流程来一步一步学习ByteBuf相关源码,为了降低学习难度,我们先从
Unpooled类入手
一个字节缓冲区的创建,本质上就是申请一块内存空间
一个
非池化创建ButeBuf的工具类
通过分配新的内存空间或通过包装/拷贝一个已存在的字节数组,字节缓冲区和一个String来创建一个新的ByteBuf对象
该类被final关键字修饰,并提供了大量的静态方法来实现创建ByteBuf对象,其ByteBuf对象创建工作实际上是委托给了内置默认的非池化字节分配器
public final class Unpooled {
// 默认的非池化字节分配器
private static final ByteBufAllocator ALLOC = UnpooledByteBufAllocator.DEFAULT;
创建堆内以及堆外字节缓冲区
/**
* Creates a new big-endian Java heap buffer with reasonably small initial capacity, which
* expands its capacity boundlessly on demand.
*/
public static ByteBuf buffer() {
return ALLOC.heapBuffer();
}
/**
* Creates a new big-endian direct buffer with reasonably small initial capacity, which
* expands its capacity boundlessly on demand.
*/
public static ByteBuf directBuffer() {
return ALLOC.directBuffer();
}
一个
非池化字节缓冲分配器
- UML
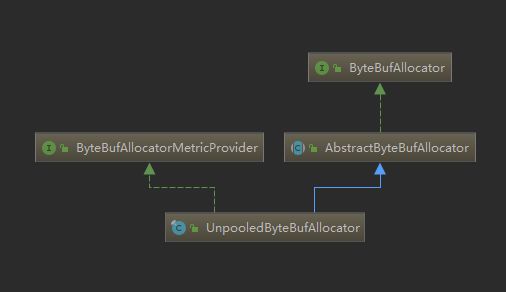
接着看调用链,发现heapBuffer方法是其抽象父类AbstractByteBufAllocator实现的
该分配器抽象类实现了接口ByteBufAllocator中的大部分方法,故UnpooledByteBufAllocator的方法调用大部分都是调用了其抽象基类的,这里我们重点看下这个抽象分配器类
public abstract class AbstractByteBufAllocator implements ByteBufAllocator {
// buffer默认初始容量
static final int DEFAULT_INITIAL_CAPACITY = 256;
// 默认最大容量
static final int DEFAULT_MAX_CAPACITY = Integer.MAX_VALUE;
// 是否默认直接内存分配
private final boolean directByDefault;
// 构造函数
protected AbstractByteBufAllocator(boolean preferDirect) {
// 根据是否倾向直接内存以及
// 是否在class path下发现有可以加速直接内存访问的sun.misc.Unsafe类
directByDefault = preferDirect && PlatformDependent.hasUnsafe();
emptyBuf = new EmptyByteBuf(this);
}
@Override
public ByteBuf heapBuffer() {
return heapBuffer(DEFAULT_INITIAL_CAPACITY, DEFAULT_MAX_CAPACITY);
}
可以看到这里调用了重载参数的heapBuffer方法,并传入了默认初始buffer容量以及默认最大容量
@Override
public ByteBuf heapBuffer(int initialCapacity, int maxCapacity) {
// 1. 如果初始容量以及最大容量都为0,则返回一个空的buffer对象
if (initialCapacity == 0 && maxCapacity == 0) {
return emptyBuf;
}
// 2. 校验参数合法性,主要是initialCapacity不可以大于maxCapacity,否则会抛IllegalArgumentException异常
validate(initialCapacity, maxCapacity);
// 3. 主要的创建方法
return newHeapBuffer(initialCapacity, maxCapacity);
}
/**
* Create a heap {@link ByteBuf} with the given initialCapacity and maxCapacity.
*/
protected abstract ByteBuf newHeapBuffer(int initialCapacity, int maxCapacity);
这里看到newHeapBuffer方法是一个protected修饰的抽象方法,其具体的实现由子类完成,我们将视角转向子类UnpooledByteBufAllocator
@Override
protected ByteBuf newHeapBuffer(int initialCapacity, int maxCapacity) {
return PlatformDependent.hasUnsafe() ?
new InstrumentedUnpooledUnsafeHeapByteBuf(this, initialCapacity, maxCapacity) :
new InstrumentedUnpooledHeapByteBuf(this, initialCapacity, maxCapacity);
}
这里会根据PlatformDependent.hasUnsafe()方法返回值分别调用不同ByteBuf实现类的构造函数
hasUnsafe内部就是去判断在class path下是否有可以加速直接内存访问的sun.misc.Unsafe类
我们以InstrumentedUnpooledUnsafeHeapByteBuf内部类为例
private static final class InstrumentedUnpooledUnsafeHeapByteBuf extends UnpooledUnsafeHeapByteBuf {
InstrumentedUnpooledUnsafeHeapByteBuf(UnpooledByteBufAllocator alloc, int initialCapacity, int maxCapacity) {
super(alloc, initialCapacity, maxCapacity);
}
@Override
protected byte[] allocateArray(int initialCapacity) {
byte[] bytes = super.allocateArray(initialCapacity);
((UnpooledByteBufAllocator) alloc()).incrementHeap(bytes.length);
return bytes;
}
@Override
protected void freeArray(byte[] array) {
int length = array.length;
super.freeArray(array);
((UnpooledByteBufAllocator) alloc()).decrementHeap(length);
}
}
- UML类图
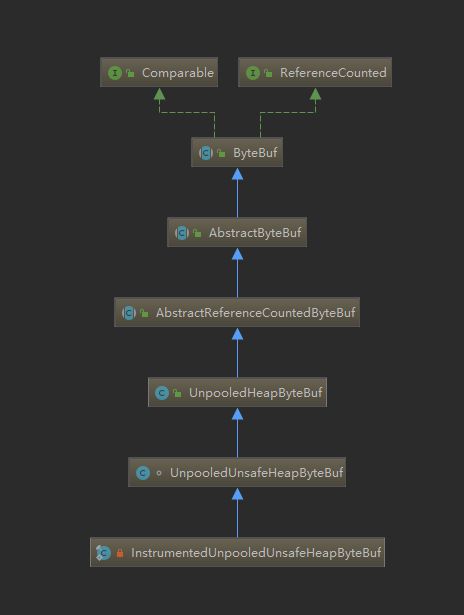
可以看到其构造函数就是调用父类的构造,且传入了this参数,作为即将分配字节缓冲区的分配器引用,我们逐一查看
大字节序的Java堆字节缓冲区实现类
public class UnpooledHeapByteBuf extends AbstractReferenceCountedByteBuf {
// 持有所属分配器引用
private final ByteBufAllocator alloc;
// 实际存储字节数组
byte[] array;
// 临时NIO buffer
private ByteBuffer tmpNioBuf;
// 构造函数为public,表示也可以直接调用,一般不推荐
public UnpooledHeapByteBuf(ByteBufAllocator alloc, int initialCapacity, int maxCapacity) {
// 继续调用父类,初始化buffer的最大容量属性
super(maxCapacity);
// 所属分配器不可为null
checkNotNull(alloc, "alloc");
// 校验容量参数合法性
if (initialCapacity > maxCapacity) {
throw new IllegalArgumentException(String.format(
"initialCapacity(%d) > maxCapacity(%d)", initialCapacity, maxCapacity));
}
// 赋值所属分配器实例引用
this.alloc = alloc;
// 1. 设置字节数组
setArray(allocateArray(initialCapacity));
// 2. 设置readerIndex,writerIndex索引
setIndex(0, 0);
}
// 分配数组方法
protected byte[] allocateArray(int initialCapacity) {
return new byte[initialCapacity];
}
这里可以看到allocateArray方法被protected修饰,且子类InstrumentedUnpooledUnsafeHeapByteBuf重写了该方法,也就是说这里实际上是调用了子类重写后的方法,这里将视角转到InstrumentedUnpooledUnsafeHeapByteBuf类
@Override
protected byte[] allocateArray(int initialCapacity) {
// 1. 调用父类UnpooledUnsafeHeapByteBuf分配字节数组方法,返回已分配的堆内字节数组
byte[] bytes = super.allocateArray(initialCapacity);
// 2. 获取所属的分配器,并调用分配器的incrementHeap方法
((UnpooledByteBufAllocator) alloc()).incrementHeap(bytes.length);
return bytes;
}
- 调用父类
UnpooledUnsafeHeapByteBuf类的分配字节数组方法
@Override
protected byte[] allocateArray(int initialCapacity) {
return PlatformDependent.allocateUninitializedArray(initialCapacity);
}
可以看到这里借助了PlatformDependent类,分配了一个未初始化的字节数组
static {
...
int tryAllocateUninitializedArray =
SystemPropertyUtil.getInt("io.netty.uninitializedArrayAllocationThreshold", 1024);
UNINITIALIZED_ARRAY_ALLOCATION_THRESHOLD = javaVersion() >= 9 && PlatformDependent0.hasAllocateArrayMethod() ?
tryAllocateUninitializedArray : -1;
}
public static byte[] allocateUninitializedArray(int size) {
return UNINITIALIZED_ARRAY_ALLOCATION_THRESHOLD < 0 || UNINITIALIZED_ARRAY_ALLOCATION_THRESHOLD > size ?
new byte[size] : PlatformDependent0.allocateUninitializedArray(size);
}
这里实际上满足了三目表达式条件,直接new了一个byte数组返回
- 这里主要看下所属分配器的incrementHeap方法做了什么,视角转到分配器UnpooledByteBufAllocator
void incrementHeap(int amount) {
metric.heapCounter.add(amount);
}
这里是做了一个监控,一个计数器去计数堆内存已经被创建的ByteBuf占了多少
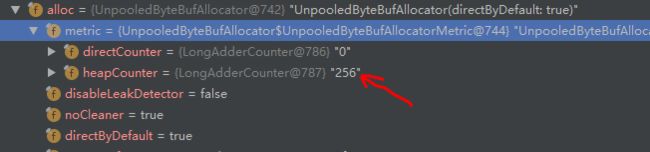
方法调用结束,再将视角转回到UnpooledHeapByteBuf类的构造函数中的setArray处
private void setArray(byte[] initialArray) {
array = initialArray;
tmpNioBuf = null;
}
setArray方法就是对实例属性array进行赋值以及将tmpNioBuf置为null
而setIndex方法则调用了抽象父类AbstractByteBuf的方法,我们继续将视角转向AbstractByteBuf类
public abstract class AbstractByteBuf extends ByteBuf {
// 读索引
int readerIndex;
// 写索引
int writerIndex;
// 已标记读索引
private int markedReaderIndex;
// 已标记写索引
private int markedWriterIndex;
// 最大容量
private int maxCapacity;
private static void checkIndexBounds(final int readerIndex, final int writerIndex, final int capacity) {
if (readerIndex < 0 || readerIndex > writerIndex || writerIndex > capacity) {
throw new IndexOutOfBoundsException(String.format(
"readerIndex: %d, writerIndex: %d (expected: 0 <= readerIndex <= writerIndex <= capacity(%d))",
readerIndex, writerIndex, capacity));
}
}
@Override
public ByteBuf setIndex(int readerIndex, int writerIndex) {
// 范围校验
if (checkBounds) {
checkIndexBounds(readerIndex, writerIndex, capacity());
}
setIndex0(readerIndex, writerIndex);
return this;
}
final void setIndex0(int readerIndex, int writerIndex) {
this.readerIndex = readerIndex;
this.writerIndex = writerIndex;
}
至此Unpooled.buffer()方法的源码已经分析完毕,放一张堆内分配非池化字节缓冲区创建图
下面我们分析一下采用非池化直接内存分配的字节缓冲区的创建流程
public static ByteBuf directBuffer() {
return ALLOC.directBuffer();
}
视角转到非池化字节缓冲分配器(UnpooledByteBufAllocator)的directBuffer方法
同理,directBuffer方法由其分配器的基类实现,故视角转到AbstractByteBufAllocator抽象字节缓冲分配器类的directBuffer方法
@Override
public ByteBuf directBuffer() {
return directBuffer(DEFAULT_INITIAL_CAPACITY, DEFAULT_MAX_CAPACITY);
}
也是一个重载默认参数的方法,继续
@Override
public ByteBuf directBuffer(int initialCapacity, int maxCapacity) {
if (initialCapacity == 0 && maxCapacity == 0) {
return emptyBuf;
}
validate(initialCapacity, maxCapacity);
return newDirectBuffer(initialCapacity, maxCapacity);
}
若initialCapacity和maxCapacity均为0,则返回一个空的buffer
校验参数合法性
转到newDirectBuffer方法创建直接内存缓冲区实例
protected abstract ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity);
这里是一个抽象的protected修饰的方法,具体的实现由子类UnpooledByteBufAllocator实现,我们跳转一下到子类中去看
@Override
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
final ByteBuf buf;
// 1.
if (PlatformDependent.hasUnsafe()) {
// 2.
buf = noCleaner ? new InstrumentedUnpooledUnsafeNoCleanerDirectByteBuf(this, initialCapacity, maxCapacity) :
new InstrumentedUnpooledUnsafeDirectByteBuf(this, initialCapacity, maxCapacity);
} else {
buf = new InstrumentedUnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
// 3.
return disableLeakDetector ? buf : toLeakAwareBuffer(buf);
}
该方法我们分三点来分析
利用PlatformDependent.hasUnsafe()判断是否
在classpath下存在sun.misc.Unsafe类关于noCleaner请看
莫那一鲁道博友的Netty 内存回收之 noCleaner 策略文章,这里为true,继续往下走,调用InstrumentedUnpooledUnsafeNoCleanerDirectByteBuf类的构造函数根据是否禁用泄露检测
disableLeakDetector,决定是否检测泄露缓冲区
同样是UnpooledByteBufAllocator非池化字节缓冲分配器的内部静态类
- UML
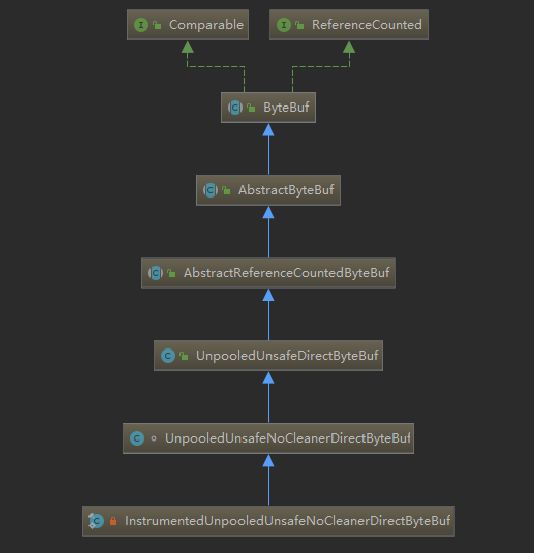
- 源码
private static final class InstrumentedUnpooledUnsafeNoCleanerDirectByteBuf
extends UnpooledUnsafeNoCleanerDirectByteBuf {
InstrumentedUnpooledUnsafeNoCleanerDirectByteBuf(
UnpooledByteBufAllocator alloc, int initialCapacity, int maxCapacity) {
super(alloc, initialCapacity, maxCapacity);
}
@Override
protected ByteBuffer allocateDirect(int initialCapacity) {
ByteBuffer buffer = super.allocateDirect(initialCapacity);
((UnpooledByteBufAllocator) alloc()).incrementDirect(buffer.capacity());
return buffer;
}
@Override
ByteBuffer reallocateDirect(ByteBuffer oldBuffer, int initialCapacity) {
int capacity = oldBuffer.capacity();
ByteBuffer buffer = super.reallocateDirect(oldBuffer, initialCapacity);
((UnpooledByteBufAllocator) alloc()).incrementDirect(buffer.capacity() - capacity);
return buffer;
}
@Override
protected void freeDirect(ByteBuffer buffer) {
int capacity = buffer.capacity();
super.freeDirect(buffer);
((UnpooledByteBufAllocator) alloc()).decrementDirect(capacity);
}
}
这里的构造函数调用父类UnpooledUnsafeDirectByteBuf的构造方法
$\color{red}{UnpooledUnsafeDirectByteBuf}
public class UnpooledUnsafeDirectByteBuf extends AbstractReferenceCountedByteBuf {
// 分配器引用
private final ByteBufAllocator alloc;
// 临时NioBuf
private ByteBuffer tmpNioBuf;
private int capacity;
private boolean doNotFree;
// JDK的ByteBuffer
ByteBuffer buffer;
long memoryAddress;
public UnpooledUnsafeDirectByteBuf(ByteBufAllocator alloc, int initialCapacity, int maxCapacity) {
// 1.
super(maxCapacity);
if (alloc == null) {
throw new NullPointerException("alloc");
}
checkPositiveOrZero(initialCapacity, "initialCapacity");
checkPositiveOrZero(maxCapacity, "maxCapacity");
if (initialCapacity > maxCapacity) {
throw new IllegalArgumentException(String.format(
"initialCapacity(%d) > maxCapacity(%d)", initialCapacity, maxCapacity));
}
// 2.
this.alloc = alloc;
// 3.
setByteBuffer(allocateDirect(initialCapacity), false);
}
// protected 修饰的方法,由于子类重写了该方法,所以此处调用给了子类的allocateDirect方法
protected ByteBuffer allocateDirect(int initialCapacity) {
return ByteBuffer.allocateDirect(initialCapacity);
}
这里分三步分析
继续向上调用
父类AbstractByteBuf的构造函数,赋值maxCapacity属性值赋值自身属性分配器alloc
这一步我们拆分为两步走,第一步先调用allocateDirect方法分配直接内存,第二部将分配完成的直接内存通过setByteBuffer赋值到JDK的ByteBuffer属性上
- allocateDirect分配直接内存
由于子类InstrumentedUnpooledUnsafeNoCleanerDirectByteBuf重写了分配内存方法,故此处实际调用的是子类的方法
@Override
protected ByteBuffer allocateDirect(int initialCapacity) {
// 1.
ByteBuffer buffer = super.allocateDirect(initialCapacity);
// 2.
((UnpooledByteBufAllocator) alloc()).incrementDirect(buffer.capacity());
return buffer;
}
-
中调用父类
UnpooledUnsafeNoCleanerDirectByteBuf的方法分配直接内存@Override
protected ByteBuffer allocateDirect(int initialCapacity) {
return PlatformDependent.allocateDirectNoCleaner(initialCapacity);
}
还是同样的套路,利用了PlatformDependent类完成实际分配内存的工作,返回一个JDK的ByteBuffer对象
public static ByteBuffer allocateDirectNoCleaner(int capacity) {
assert USE_DIRECT_BUFFER_NO_CLEANER;
// 1. 增加直接内存分配计数器
incrementMemoryCounter(capacity);
try {
// 2.
return PlatformDependent0.allocateDirectNoCleaner(capacity);
} catch (Throwable e) {
decrementMemoryCounter(capacity);
throwException(e);
return null;
}
}
static ByteBuffer allocateDirectNoCleaner(int capacity) {
// Calling malloc with capacity of 0 may return a null ptr or a memory address that can be used.
// Just use 1 to make it safe to use in all cases:
// See: http://pubs.opengroup.org/onlinepubs/009695399/functions/malloc.html
return newDirectBuffer(UNSAFE.allocateMemory(Math.max(1, capacity)), capacity);
}
static ByteBuffer newDirectBuffer(long address, int capacity) {
ObjectUtil.checkPositiveOrZero(capacity, "capacity");
try {
return (ByteBuffer) DIRECT_BUFFER_CONSTRUCTOR.newInstance(address, capacity);
} catch (Throwable cause) {
// Not expected to ever throw!
if (cause instanceof Error) {
throw (Error) cause;
}
throw new Error(cause);
}
}
UNSAFE.allocateMemory(Math.max(1, capacity))方法返回的是一个直接内存的地址,本质上是一个long型整数
public native long allocateMemory(long var1);
而具体直接内存的地址获取则是由sun.misc包下的Unsafe类的native方法分配的
到这里我们看到是利用了java.nio.DirectByteBuffer类的构造器利用反射创建了一个DirectByteBuffer对象,传入了已经分配好的直接内存地址(long型整数)以及初始容量大小(256)
分配直接内存总结起来有三点:
增加直接内存计数器
利用Unsafe类分配一个直接内存地址,Long整数
调用JDK nio包的DirectByteBuffer构造函数反射创建对象返回
分配直接内存方法结束后,将视角重新回到UnpooledUnsafeDirectByteBuf类,看下setByteBuffer方法做了什么
final void setByteBuffer(ByteBuffer buffer, boolean tryFree) {
if (tryFree) {
ByteBuffer oldBuffer = this.buffer;
if (oldBuffer != null) {
if (doNotFree) {
doNotFree = false;
} else {
freeDirect(oldBuffer);
}
}
}
this.buffer = buffer;
memoryAddress = PlatformDependent.directBufferAddress(buffer);
tmpNioBuf = null;
capacity = buffer.remaining();
}
这里tryFree传入的是false,if条件不会进入,后面的就是将分配的JDK的NIO包下的直接内存缓冲区DirectByteBuffer赋值到Netty的UnpooledUnsafeDirectByteBuf类的buffer属性上,以及赋值直接内存地址memoryAddress,capacity容量等属性
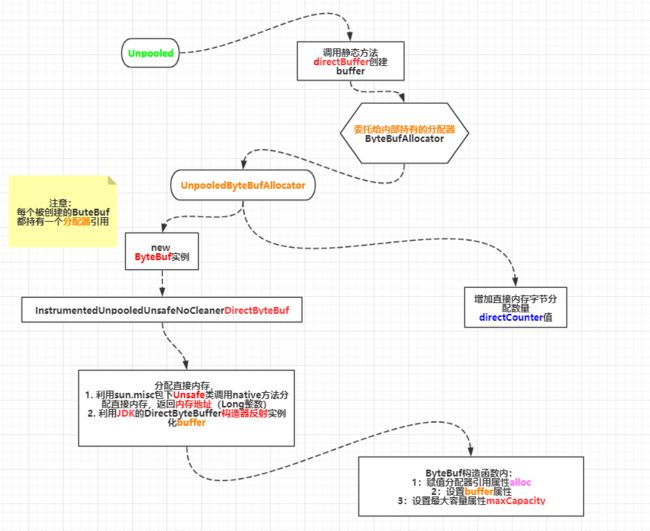
至此,整个堆内/堆外内存分配流程都已经分析完毕,至于Netty检测直接内存泄漏的原理后续文章会分析