
一、 任务目标
- Use linear regression with basis functions, you can choose any basis functions as you like.
- Calculate the least squares solution; then add quadratic regularization (i.e. ridge), test different choices of λ,present the test performance
- Use cross validation to find out an optimal set of basis functions. For example, you can select from polynomials of different orders
- Use logistic regression with basis functions, you can choose any basis functions
- Use the Bayesian information criterion to find out an optimal set of basis functions, verify whether your choice is correct using the test data
- Use lasso regression For linear regression:
- Calculate model evidence in the Bayesian framework, and perform model selection accordingly, verify your choice using the test data
- Use Fisher’s LDA
- Try to divide the training data into multiple classes (e.g. using k-means), and train a multi-class classifier accordingly, use it on the test data, and convert the multi-class results into binary classes; show the performance
二、 数据集介绍
2-D Points Date Set
Abstract:Using a binary classifier to divide a set of 2-D points to two subsets

数据下载地址见: http://staff.ustc.edu.cn/~dongeliu/statlearn.html
三、 实验过程
1)加载训练数据和测试数据,并可视化

read_csv()函数说明:https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_csv.html。第一个参数为本地数据库的绝对路径; 第二个参数代表 List of column names to use,即数据集中各列的名称。
完成文件加载后,利用Dataframe.values返回以array类型保存的数据内容。紧接着,我们对数据进行可视化,以训练数据为例:
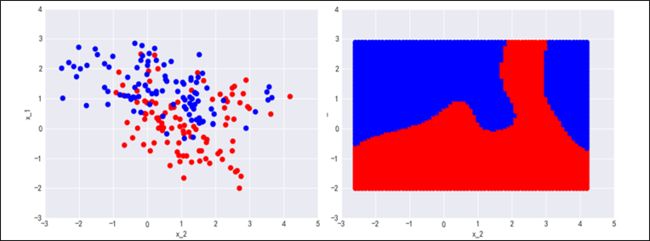
同理我们可以对测试数据进行可视化。注意:数据集并没有直接给出测试点的label,而是给出了P(C1|x),即 x 属于True 的概率,我们设定阈值为0.5,if P(C1|x)>0.5,label(x) = True, else label(x) = False。数据可视化后结果如图3-3,蓝色点代表属于True类,红色点代表属于FALSE类。
2)训练一个最小平方误差线性回归器进行二分类
线性分类问题可以视为一个特殊的回归问题,只不过此回归模型的训练样本只取两个特殊实数值:{0,1}。可以预见,对一个实例x, 若label = 1,则训练好的线性回归模型倾向于给出接近于1的值,反之则给出接近于近零值,因此我们对这个回归模型取阈值函数,就得到了分类模型。
我们先训练一个带基函数的最小平方误差线性回归器,基函数取多项式基。

以二阶多项式线性回归器为例:
i) 先将二维数据点x(x1,x2)扩展成新的矢量 x’(1, x1, x2, x1x2, x12, x22).可以通过 sklearn.preprocessing.polynomialFeature()函数实现:http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.PolynomialFeatures.html
ii) 通过linear_model.LinearRegression( )函数获得一个线性回归器.
http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
参数 fit_intercept:控制是否对函数进行截断,设为 true 则偏置 w0 始终为 0。
reg.fit(Xtrain,ctrain):根据训练数据Xtrain,数据标签ctrain进行训练,训练完成后,可以通过reg.coef_返回回归模型的权重矢量[w0, w1, w2, w3, w4, w5 ]。
3)将LS线性回归器在测试集上进行测试,计算错误分类率

错误分类率的定义如下:p( x) 取自ptest.txt, p(C1| x)取自C1test.txt.
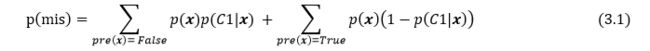
4)用简单交叉验证的方法寻找LS线性回归分类器的最佳阶数M
我们以阶数M为自变量,训练不同阶数的多项式LS线性回归器,并在测试集上进行测试,计算相应的错误分类率。结果见图3-7.
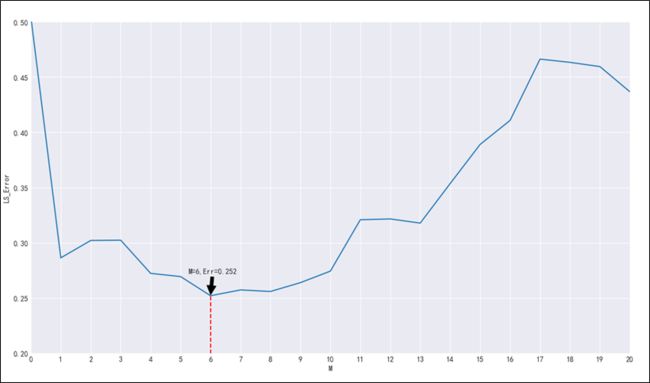
由图3-7知,随着阶数M的增大,误差率先下降再上升,符合从欠拟合到过拟合的变化规律。最佳阶数M = 6,此时误差率 =0.252.
5)在贝叶斯框架下进行模型选择,计算模型证据,选择最佳阶数M
在步骤4中,以及在Proj 1 kNN 中我们用交叉验证的方法进行模型选择。在本节探讨的贝叶斯框架中,模型比较可以直接在训练集上进行,无需验证集。定义模型证据为:
式中,D为训练数据,Mi为模型,p(w)为模型Mi的参数先验分布。模型证据表征了模型Mi生成训练数据集D的概率。
在线性基函数模型中,引入超参α,β后,可以把模型证据写成如下形式:
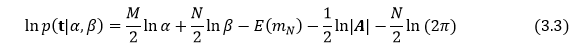
其中:
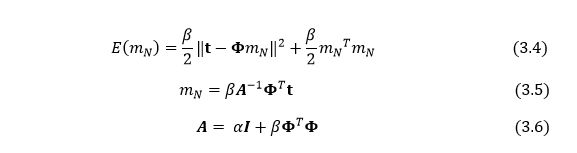
式中的Φ为多项式基函数表示下的训练数据矩阵。
我们固定参数α的值为0.00005。β 的值可以通过最大化模型证据函数得到。由于在本实验中,我们训练数据的标签值t 只取离散的0和1,假定标注可靠(噪声极小),可将p(t|x****,w**) 看做服从 β 值(方差的倒数)很大的高斯分布,取 β =1000000。
根据式(3.3),不难编程计算线性回归模型的模型证据,key code 见图3-8。

我们画出模型证据和多项式阶数的关系,见图3-9。我们发现随着阶数增大,模型证据变大,在M=6时,模型证据达到峰值,随后又下降。在步骤5中,我们通过交叉验证寻找到的最佳M =5,造成两者的差异主要原因可能源于在计算Model evidenc时,对超参 β 值的估计过于粗略。

6)训练ridge回归器进行二分类

ridReg = linear_model.Ridge (alpha = 1,fit_intercept=False) 含义:初始化一个惩罚系数为1,不截断的ridge回归器。
ridReg.fit(Xtrain,ctrain) 含义:用训练数据训练得到一个ridge 回归器。
Ridge 回归等价于w服从高斯先验下的极大后验概率估计。
7)计算ridge回归器在不同惩罚系数下的错误分类率,研究正则化技术对抑制过拟合的作用
由图3-7知,当阶数M=11时发生过拟合。在本节实验中,我们探讨惩罚系数大小对模型复杂度的控制。我们从小到大地增大惩罚系数,训练得到ridge 回归器,并计算在测试集上的错误分类率。
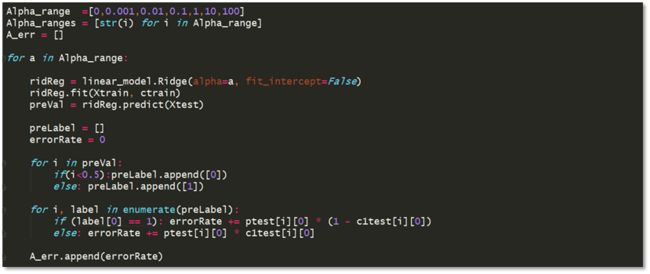
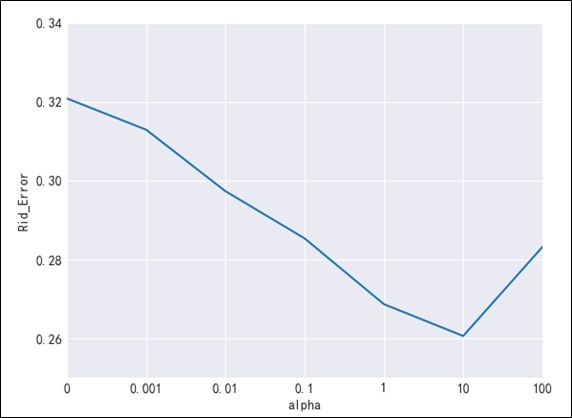
我们画出模型错误分类率和正则化惩罚系数的关系见图3-11。随着惩罚系数的增大,错误率下降,过拟合现象得到抑制,在 λ =10 时,取到最低错误率0.2606(M =11).但是随着λ的继续增大,发生欠拟合现象,错误率再次上升。
8)训练lasso回归器进行二分类,计算错误分类率,并与ridge回归器作比较

Lasso 回归等价于w服从拉普拉斯先验下的极大后验概率估计。
可以利用sklearn.linear.Lasso()实现:http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Lasso.html
lasoReg = linear_model.Lasso (alpha = 100,fit_intercept=False,max_iter=100000) 含义:初始化一个lasso 回归器,惩罚系数为100,不截断,最大迭代次数为100(坐标下降法求解)。
同样地,我们画出不同惩罚系数下,lasso回归器的错误分类率如图3-13所示。注意:当惩罚系数过大或过小时,算法不容易收敛,程序容易崩溃,可通过增大精度误差或减小迭代次数强迫收敛,当然这样做牺牲了算法可靠性。

由图3-13 看出,在惩罚系数较小时,lasso回归器性能较好,当 λ = 0.001时,错误分类率为0.244 (M=11)
通过print(ridReg.coef_),print(lasoReg.coef_)打印ridge回归器和lasso回归器的模型系数,我们不难发现:lasso倾向于给出关于w的稀疏解,并且随着惩罚洗漱的增大,越来越多的参数会变为零。而ridge回归器倾向于将参数朝零点方向收缩,但参数不会变为零。
9)训练LDA二分类,计算错误分类率

可以调用 scikit_learn 库中的LinearDiscriminantAnalysis()函数实现目的:
http://scikit-learn.org/stable/modules/generated/sklearn.discriminant_analysis.LinearDiscriminantAnalysis.html
LDA=LinearDiscriminantAnalysis() 含义:初始化一个LDA分类器
LDA.fit(xtrain,ctrain.ravel()) 含义:使用训练数据训练LDA,
ctrain.ravel() 含义: 将标签矩阵从 [n_samples, 2] 形状reshape成 [1, n_samples ] 形状。
实验结果:通过LDA 分类器将数据点投影到一维直线上进行决策分类后,LDA分类误差率为:0.286.
10)训练多项式基函数逻辑回归分类器,用简单交叉验证的方法寻找最佳阶数M

可以调用 scikit_learn 库中的LogisticRegression()函数实现目的:
logic = LogisticRegression(fit_intercept=False) 含义:初始化一个逻辑回归器,注意:在sklearn库中,逻辑回归分类器必须带正则项,默认为L-2正则项。
类似步骤4,我们可以用简单交叉验证的方法寻找最佳阶数 M ,画出阶数M与逻辑回归分类器错误分类率的关系,见图3-14.
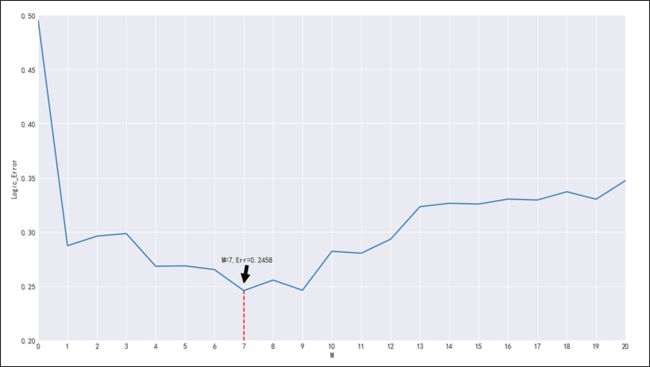
由图3-14看出,随着阶数M上升,逻辑回归器的拟合效果提高,分类误差率下降,并在M =7时,逻辑回归分类器达到最低分类误差率:0.2458
11)在训练集上计算贝叶斯信息准则(BIC), 根据贝叶斯信息准则选择逻辑回归模型的最佳阶数
BIC(贝叶斯信息准则)是对model evidence (模型证据) 的估计,应用于模型选择。其定义如下:
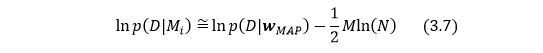
式中D为训练数据,Mi为模型,Wmap为模型参数的最大后验估计,M为模型参数数量,N为训练数据点数。
由于在sklearn 中,逻辑回归模型已经使用正则项对模型复杂度做了惩罚,并且求得的 w 为假定似然服从伯努利分布条件下的解。因此我们对BIC 做如下近似:

式中,c(x)取自 ctrain.txt,如果c(x)=1, 则p(x,c(x)|w)=σ(wTΦ(x)), 如果c(x)=0,则p(x,c(x)|w)=1-σ(wTΦ(x)).
由于 σ(wTΦ(x)) 或 (1-σ(wTΦ(x)))容易得到近零值,故将逻辑回归器的输出值加1后再取对数。
根据上述思路,不难编程计算模型的贝叶斯信息,见图3-15.
12)改变阶数M,计算相应的逻辑回归模型的BIC,画出M 和 BIC 的关系如图3-16
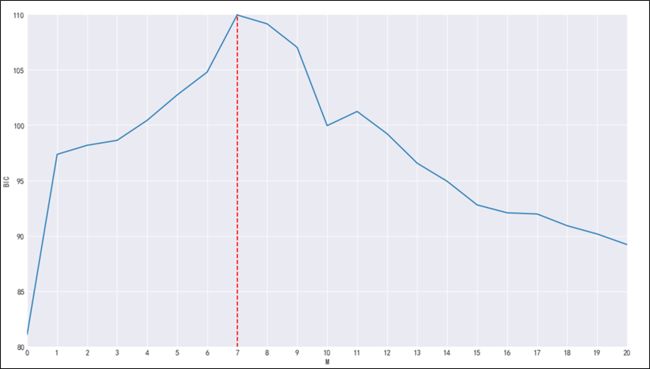
由图3-16可以看出,随着阶数M的增大,对数据的拟合效果提升,BIC 不断增大,当M=7时,BIC达到最大值,与图3-14中的分析结果(M=7时,错误分类率最低 )一致。随着M的继续增大,虽然对数据的拟合效果继续提升,但是提升程度不大,而模型的复杂度却越来越复杂,这导致整体的BIC 值开始下降。
13)利用Kmeans算法将训练数据划分成多类,并可视化
利用sklearn.cluster.Kmeans()函数实现:
http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
kmeans = KMeans(n_clusters = N_clusters, random_state = 0) 初始化一个Kmeans聚类器,参数含义:
n_clusters:聚类数 ;random_state: 随机数种子,用于决定Kmeans 的初始聚类中心。
kmeans.fit(xtrain) :用训练数据训练Kmeans聚类器。
kmeansLabel = kmeans.labels_:返回训练数据聚类后的标签。

对训练数据完成聚类后,我们对数据重新进行可视化,以聚成3类为例,划分结果如图3-18.
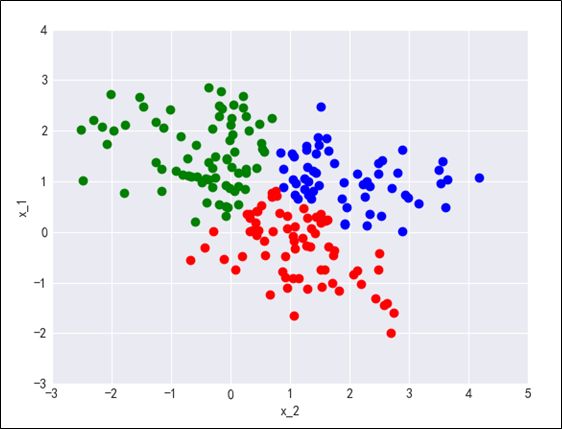
14)以步骤10划分后的数据为训练数据,训练一个多分类器,并将之转化为二分类器

可以通过sklearn.multiclass.OneVsRestClassifier() 实现一个“一对多”的多分类器。
http://scikit-learn.org/stable/modules/generated/sklearn.multiclass.OneVsRestClassifier.html
mulClassifier = OneVsRestClassifier(LinearSVC()) 含义:训练一个以线性SVM为基分类器的“一对多”多分类器; mulClassifier.fit(xtrain,kmeansLabel) 含义:用训练数据训练该分类器,kemansLabel即步骤10对训练数据划分后的标签。
训练得到多分类器后,我们考虑如何将之转化成二分类。
一个很自然的想法是:假设多分类器已经将数据划分成了3类,即D1={x|preLabel(x)=C1}, D2={x|preLabel(x)=C2}, D3={x|preLabel(x)=C3},则在每一类数据Di中, 我们根据原始数据的True-False标签继续训练一个二分类器。则整个二分类任务变成了“分治任务”,即先做多分类,然后在每一类中做二分类。
考虑到每一类数据Di 包含的数据点较少,子二分类模型不宜复杂。我们简单地统计Di 中的属于True的点数 ti 和属于False的点数 fi ,如果 ti >fi, 则设置整个Di 的数据标签Ci = True, 若ti <= fi, 则设置Ci = False. 事实上,子二分类器本质上是一个KNN,只不过Ki = 数据Di 的点数。
根据上述思路,不难编程实现将多分类器转化为二分类,key code 见图3-18.
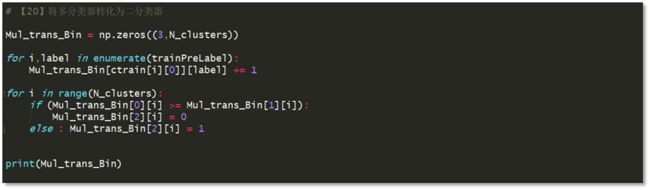
15)将由多分类器转化而来的二分类器在测试集上进行测试,利用简单交叉验证的方法探寻最佳聚类数
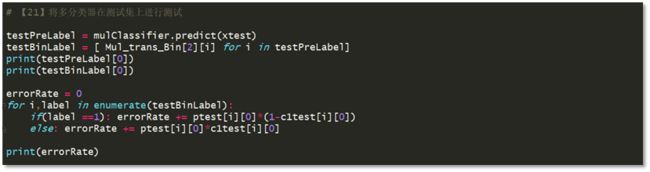
testPreLabel = mulClassifier.predict(xtest) 含义:得到测试数据点的多分类标签Ci
testBinLabel = [ Mul_trans_Bin[2][i] for i in testPreLabel] 含义:查找Ci对应的二分类标签True or False, 作为数据点的最终标签。当聚类数为3时,错误分类率为0.281.
我们改变聚类数,得到聚类数和错误分类率的关系如图3-20所示。当聚类数C=7时,达到最低错误分类率:0.254.

四、 实验总结
针对上表中的二分类算法,我们有以下几点结论,这些结论在本文第二部分中均得到具体阐述。
在一定条件下,线性回归算法可以解决线性分类问题,但是常见线性回归算法建立在目标值服从高斯分布的假设下,而在分类问题中,目标值显然不服从高斯分布。可以预见,此类算法的分类效果对离群噪点的鲁棒性较差。
我们可以通过构建多个二分类器的方法得到多分类器。反过来,也可以通过“分而治之”的思想将多分类器转化为一个二分类器。在面对线性不可分且异类点相对集中的数据时,这种算法会有较好的分类性能,对噪点的鲁棒性也较强。
-
模型选择方法除了交叉验证外,还包括贝叶斯派的BIC最大准则,模型证据最大准则等,这些方法只需根据训练数据就能进行模型选择,无需验证集,但是理论复杂,实现困难,在实际中较难应用。
