1.Java中==和equal有什么区别
==比较的是对象的地址,也就是是否是同一个对象;
equal比较的是对象的值。
例如:
Integer r1 = newInteger(900);//定义r1整型对象
Integer r2 = newInteger(900);//定义r2整型对象
System.out.println(r1==r2);//返回false
System.out.println(r1.equal(r2));//返回true
2.jmeter如何对登录进行压测,在一个时间段内达到一定数量的用户
线程启动了就会直接发送测试请求。
如果要模拟在一瞬间高并发量测试的时候,需要调高线程数量,这很耗测试机器的性能,往往无法支持较大的并发数,无法控制每次测试的瞬间并发量。
解决:使用集合点;
作用:阻塞线程,直到指定的线程数量到达后,再一起释放,可以瞬间产生很大的压力。
详细操作可参见:Jmeter使用集合点,模拟达到指定的线程数后高并发测试
3.spring的Aop原理,具体使用
就是将那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。
AOP把软件系统分为两个部分:核心关注点和横切关注点。业务处理的主要流程是核心关注点,与之关系不大的部分是横切关注点。横切关注点的一个特点是,他们经常发生在核心关注点的多处,而各处都基本相似。比如权限认证、日志、事务处理。Aop 的作用在于分离系统中的各种关注点,将核心关注点和横切关注点分离开来。
AOP用来封装横切关注点,具体可以在下面的场景中使用:
Authentication 权限
Caching 缓存
Context passing 内容传递
Error handling 错误处理
Lazy loading 懒加载
Debugging 调试
logging, tracing, profiling and monitoring 记录跟踪 优化 校准
Performance optimization 性能优化
Persistence 持久化
Resource pooling 资源池
Synchronization 同步
Transactions 事务
可参考:https://segmentfault.com/a/1190000009165134
4.get和post的区别
相同点
都是向服务器发送请求:Get是向服务器发送索取数据的一种请求,而Post是向服务器提交数据的一种请求
不同点
(1)、请求的数据
GET请求,请求的数据会附加在URL之后,以?分割URL和传输数据,多个参数用&连接。URL的编码格式采用的是ASCII编码,而不是uniclde,即是说所有的非ASCII字符都要编码之后再传输。
POST请求:POST请求会把请求的数据放置在HTTP请求包的包体中。上面的item=bandsaw就是实际的传输数据。
因此,GET请求的数据会暴露在地址栏中,而POST请求则不会。
(2)、用途
GET用于从服务器端获取数据,包括静态资源(HTML|JS|CSS|Image等等)、动态数据展示(列表数据、详情数据等等)。
POST用于向服务器提交数据,比如增删改数据,提交一个表单新建一个用户、或修改一个用户等。
(3)、缓存
GET时默认可以复用前面的请求数据作为缓存结果返回,此时以完整的URL作为缓存数据的KEY。所以有时候为了强制每次请求都是新数据,可以在URL后面加上一个随机参数Math.random或时间戳new Date().getTime()、或版本号,比如abc.com?a=1&rnd=0.123987之类的。这也是目前一些静态资源后面加一个很长的版本号的原因,jquery-min.js?v=13877770表示一个版本,当页面引用jquery-min.js?v=13877771时浏览器必然会重新去服务器请求这个资源。jQuery.ajax方法,如果cache=false,则会在GET请求参数中附加”_={timestamp}”来禁用缓存。
POST一般则不会被这些缓存因素影响。
(4)、安全性
默认对于nginx的access log,会自动记录get或post的完整URL,包括其中带的参数。
对于POST来说,请求的报文却不会被记录,这些对于敏感数据来说,POST更安全一些。
(5)、Url长度限制
GET是通过URL提交数据,因此GET可提交的数据量就跟URL所能达到的最大长度有直接关系。
HTTP协议本身对GET和POST都没有对长度的限制,而对于URL长度上的限制是浏览器受服务器的配置限制或者内存的大小。
(6)、幂等
GET幂等,POST不幂等
幂等是指同一个请求方法执行多次和仅执行一次的效果完全相同。
引入幂等主要是为了处理同一个请求重复发送的情况,比如在请求响应前失去连接,如果方法是幂等的,就可以放心地重发一次请求。这也是浏览器在后退/刷新时遇到POST会给用户提示的原因:POST语义不是幂等的,重复请求可能会带来意想不到的后果。
比如在微博这个场景里,GET的语义会被用在「看看我的Timeline上最新的20条微博」这样的场景,而POST的语义会被用在「发微博、评论、点赞」这样的场景中。
5.jmeter压力测试注册,参数化如何保证id不重复
1).使用UUID,JMeter函数助手给大家提供了一个UUID()函数,UUID来生成一个附机字符串。
import java.util.UUID;
UUID uuid1 = UUID.randomUUID(); //获取UID的值
vars.put("order_id",(uuid1.toString()).toUpperCase().replaceAll("-",""));
//去掉UUID的“-”,再赋值给order_id 运行获取的参数就是:3F2504E04F8911D39A0C0305E82C3301
2)、用__RandonString()与__time()组合
只要TPS足够大还是可能会有重复现象的
3)、使用多个函数组合:{time}+{group}+{thread number}+{迭代计数}
group获取:JMeter的线程组可以通过ctx来获取,线程组是类似这样的格式:线程组 1-1
使用BeanShell Sampler,${__BeanShell(((ctx.getThread().getThreadName().toString()).split(" ")[1]).split("-")[0],group)},并把线程组的Id放到了group中
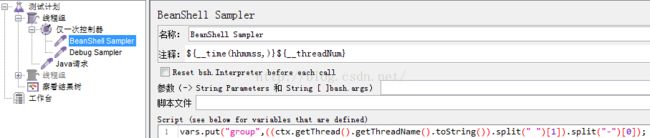
thread number获取:可以通过__threadNum获取
time获取:通过__time(hhmmss,)获取,可以指定输出格式,这里只输出时分秒
迭代计数器获取:通过__counter获取
合在一起:${__time(hhmmss,)}${group}${__threadNum}${__counter(,)}
6.Oracle中varchar2的最大长度
最大长度为4000
7.Linux中强制杀死进程的命令
首先,用ps查看进程:$ ps -ef 或者:$ ps -aux
拿到进程的PID后,执行:$ kill -s 9 1827
其中-s 9 制定了传递给进程的信号是9,即强制、尽快终止进程。
1827则是上面ps查到的某个进程的PID。
8.栈的特点
栈是一种数据结构,它按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来)。
1),先进后出 (好比高高的蒸笼一层一层的,放在最下面的蒸笼的包子最后才能拿出来),比如进123,出321
2),具有记忆功能,栈的特点是先进栈的后出栈,后进栈的先出栈,所以你对一个栈进行出栈操作,出来的元素肯定是你最后存入栈中的元素,所以栈有记忆功能。
3),对栈的插入与删除操作中,不需要改变栈底指针。
4),栈可以使用顺序存储也可以使用链式存储,栈也是线性表,因此线性表的存储结构对栈也适用
线性表可以链式存储。
9.Jenkins发布版本前,需要设置哪些参数
安装必要的插件:如搜索下载以下插件(Maven Integration plugin 、Publish Over SSH、Deploy to container Plugin)
全局工具配置,配置 jdk、git、maven、tomcat
配置服务器参数及git相关参数。
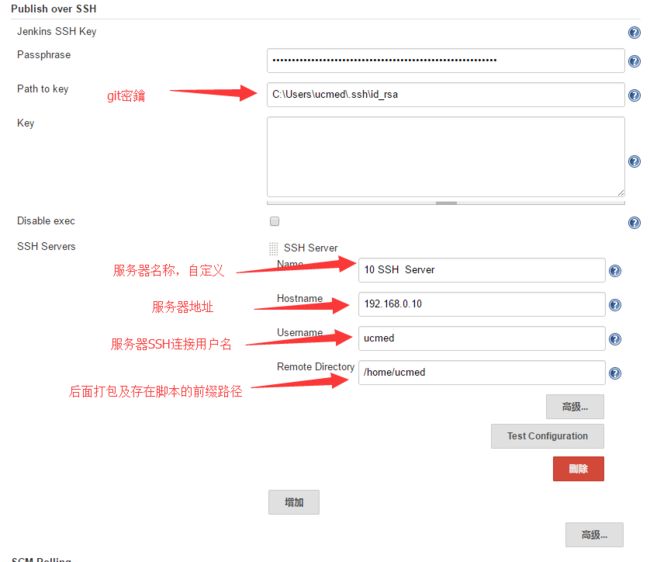
构建项目,点击新建,然后构建一个maven项目.
10.app自动化,启动driver需要设置哪些参数
DesiredCapabilities capabilities = new DesiredCapabilities();
capabilities.setCapability(MobileCapabilityType.AUTOMATION_NAME, "Selendroid");
capabilities.setCapability(MobileCapabilityType.PLATFORM_NAME, "Android");
capabilities.setCapability(MobileCapabilityType.PLATFORM_VERSION, "2.3");
capabilities.setCapability(MobileCapabilityType.DEVICE_NAME, "Android Emulator");
capabilities.setCapability(MobileCapabilityType.APP, myApp);
capabilities.setCapability(MobileCapabilityType.APP_PACKAGE: "com.mycompany.package");
capabilities.setCapability(MobileCapabilityType.APP_ACTIVITY: ".MainActivity");
|platformName|你要测试的手机操作系统|iOS, Android, 或 FirefoxOS|
|platformVersion|手机操作系统版本|例如: 7.1, 4.4|
|appPackage| 你想运行的Android应用的包名|比如com.example.android.myApp, com.android.settings|
|appActivity| 你要从你的应用包中启动的 Android Activity 名称。它通常需要在前面添加 . (如:使用.MainActivity 而不是 MainActivity) |MainActivity, .Settings|
|app|.ipa or .apk文件所在的本地绝对路径或者远程路径,也可以是一个包括两者之一的.zip。 Appium会先尝试安装路径对应的应用在适当的真机或模拟器上。针对Android系统,如果你指定app-package和app-activity(具体见下面)的话,那么就可以不指定app。 会与 browserName 冲突 |比如/abs/path/to/my.apk或http://myapp.com/app.ipa|
11.登录功能,有哪些方式可以保证安全性
12.sql 计算每个员工的总分并排名
13.已上线的项目,如何监控
使用一些开源的工具
14.hashmap,hashtree,hashlink的区别
Map map = new TreeMap();
//TreeMap取出来的是排序后的键值对。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好
Map map = new LinkedHashMap();
//LinkedHashMap 是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列.
Map map = new HashMap();
//HashMap里面存入的键值对在取出的时候是随机的,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。在Map 中插入、删除和定位元素,HashMap 是最好的选择。
15.UI自动化主要适用于哪些情况
1)、操作过程完全机械的,即测试人员不必用脑子。
2)、每次的操作行为经常是重复上一次的动作。
3)、经常要进行的测试活动。
4)、该场景完全几乎不会或者极少会改动。
16.使用selenium自动化,用什么工具管理测试用例
testng
17.接口测试用例场景如何设计
接口测试用例场景
18.给一个网站设计性能测试方案
获取用户数信息、获取业务数据量、场景业务的调查、与性能指标指标相关的调查
可参考:https://www.cnblogs.com/mxqh2016/p/6385860.html
19.锁的机制,如何避免并发
多线程并发解决方案(原子变量的使用)
20.悲观锁,乐观锁的使用有哪些?有何区别
Java 中的悲观锁和乐观锁的实现
21.线程池的安全
线程的三种实现方式:
1)、 Thread类,可extends
2)、 Runable接口,需要实现run方法,通过new Thread类调用
3)、 callable接口,需要实现call方法,通过 FutureTask 调用,并获取返回值,可结合线程池使用。
四类线程池
newCachedThreadPool
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
这种类型的线程池特点是:
工作线程的创建数量几乎没有限制(其实也有限制的,数目为Interger. MAX_VALUE), 这样可灵活的往线程池中添加线程。
如果长时间没有往线程池中提交任务,即如果工作线程空闲了指定的时间(默认为1分钟),则该工作线程将自动终止。终止后,如果你又提交了新的任务,则线程池重新创建一个工作线程。
在使用CachedThreadPool时,一定要注意控制任务的数量,否则,由于大量线程同时运行,很有会造成系统瘫痪。
newFixedThreadPool
创建一个指定工作线程数量的线程池。每当提交一个任务就创建一个工作线程,如果工作线程数量达到线程池初始的最大数,则将提交的任务存入到池队列中。
FixedThreadPool是一个典型且优秀的线程池,它具有线程池提高程序效率和节省创建线程时所耗的开销的优点。但是,在线程池空闲时,即线程池中没有可运行任务时,它不会释放工作线程,还会占用一定的系统资源。
newSingleThreadExecutor
创建一个单线程化的Executor,即只创建唯一的工作者线程来执行任务,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。如果这个线程异常结束,会有另一个取代它,保证顺序执行。单工作线程最大的特点是可保证顺序地执行各个任务,并且在任意给定的时间不会有多个线程是活动的。
newScheduleThreadPool
创建一个定长的线程池,而且支持定时的以及周期性的任务执行,支持定时及周期性任务执行。
21.selenium具体如何启动webdriver
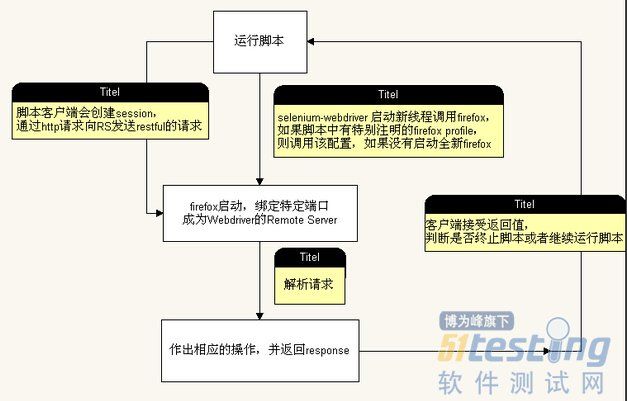
以firefox为例。
当测试脚本启动firefox的时候,selenium-webdriver 会首先在新线程中启动firefox浏览器。如果测试脚本指定了firefox的profile,那么就以该profile启动,否则的话就新启1个profile,并启动firefox;
firefox一般是以-no-remote的方法启动,启动后selenium-webdriver会将firefox绑定到特定的端口,绑定完成后该firefox实例便作为webdriver的remote server存在;
客户端(也就是测试脚本)创建1个session,在该session中通过http请求向remote server发送restful的请求,remote server解析请求,完成相应操作并返回response;
客户端接受response,并分析其返回值以决定是转到第3步还是结束脚本;
22.selenium自动化框架设计模式
selenium目前比较流行的设计模式就是page object,那么到底什么是page object呢,简单来说,就是把页面作为对象,在使用中传递页面对象,来使用页面对象中相应的成员或者方法,能更好的提现java的面向对象和封装特性。而使用时间长了会发现该模式也存在一点问题,那就是元素每次都要获取,并且获取元素与页面方法不分离,增加代码冗余度,用过springMVC框架的人都知道,注解方式的开发会大大增加开发效率,使页面变得整洁。
什么是pageFactory 设计模式呢?
准确来说就是在page object模式基础上更好的利用了面向对象的思维,将获取元素与操作页面的方法进行分离,以前获取元素要findelementbyid等等,现在只要一个注解就可以搞定,并且再次跑自动化回归测试时候,代码有获取缓存的特性,所以会比第一次跑的快,只要id,name不变。
23.安卓和iOS有什么区别
1.android是google公司做的手机系统,ios是苹果公司做的手机系统。
2.android手机系统的手机很多厂家公司在做如HTC,三星,中兴等等。。。 ios只有苹果公司的手机和数码产品才会是ios的手机系统。
3.android手机系统和ios软件开发工具不同,平台不同。软件也不用,所以两个两个平台的软件不能通用,但是好的软件都会有两个系统版本,如QQ 有IOS版也是就iphoneQQ,和android版QQ。
4.安卓手机完全开源,任何软件开发商或者个人都能开发安卓的软件。苹果IOS完全封源开发
正是由于开源和各个品牌手机硬件差异极大,导致安卓手机的系统体验各有差异,软件兼容性也不如IOS。所以安卓手机总体的系统体验,流畅度,软件兼容性,明显不如系统和软件开发都对硬件有极其针对性的IOS,软件数量也不如IOS,游戏数量也不如IOS,而且很多高质量软件,特别是游戏都是先出现在IOS上。
.安卓系统的软件几乎都是免费,而IOS的软件和游戏,好的基本都付费,当然苹果可以越狱,越狱后也是免费使用。
安卓手机支持FLASH,可以玩QQ农场,不过需要高端安卓机2.2以上系统才支持。IOS不支持FLASH,只支持HTML5,所以苹果上不能看FLASH,甚至苹果有时候连HTML5的视频兼容性也不好。
安卓手机使用起来上手快,下载歌曲电影等直接放到手机里就能看,IOS则需要同步到手机中,不过越狱后也能直接放到手机里看。
24.使用jmeter如何进行混合场景的压测
25.项目周期短,迭代频繁,使用什么开发流程比较敏捷
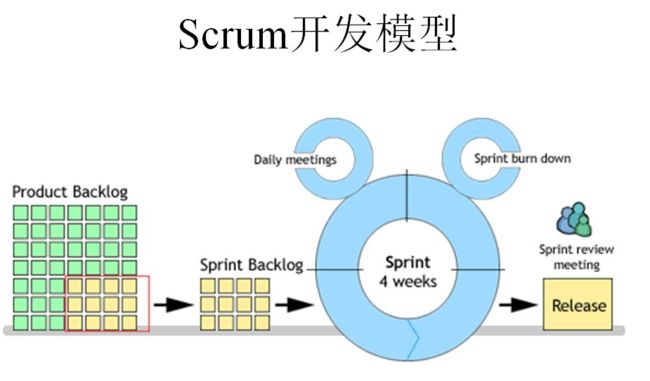
什么是Sprint?
Sprint是短距离赛跑的意思,这里面指的是一次迭代,而一次迭代的周期是1个月时间(即4个星期),也就是我们要把一次迭代的开发内容以最快的速度完成它,这个过程我们称它为Sprint。
如何进行Scrum开发?
1、我们首先需要确定一个Product Backlog(按优先顺序排列的一个产品需求列表),这个是由Product Owner 负责的;
2、Scrum Team根据Product Backlog列表,做工作量的预估和安排;
3、有了Product Backlog列表,我们需要通过 Sprint Planning Meeting(Sprint计划会议) 来从中挑选出一个Story作为本次迭代完成的目标,这个目标的时间周期是1~4个星期,然后把这个Story进行细化,形成一个Sprint Backlog;
4、Sprint Backlog是由Scrum Team去完成的,每个成员根据Sprint Backlog再细化成更小的任务(细到每个任务的工作量在2天内能完成);
5、在Scrum Team完成计划会议上选出的Sprint Backlog过程中,需要进行 Daily Scrum Meeting(每日站立会议),每次会议控制在15分钟左右,每个人都必须发言,并且要向所有成员当面汇报你昨天完成了什么,并且向所有成员承诺你今天要完成什么,同时遇到不能解决的问题也可以提出,每个人回答完成后,要走到黑板前更新自己的 Sprint burn down(Sprint燃尽图);
6、做到每日集成,也就是每天都要有一个可以成功编译、并且可以演示的版本;很多人可能还没有用过自动化的每日集成,其实TFS就有这个功能,它可以支持每次有成员进行签入操作的时候,在服务器上自动获取最新版本,然后在服务器中编译,如果通过则马上再执行单元测试代码,如果也全部通过,则将该版本发布,这时一次正式的签入操作才保存到TFS中,中间有任何失败,都会用邮件通知项目管理人员;
7、当一个Story完成,也就是Sprint Backlog被完成,也就表示一次Sprint完成,这时,我们要进行 Srpint Review Meeting(演示会议),也称为评审会议,产品负责人和客户都要参加(最好本公司老板也参加),每一个Scrum Team的成员都要向他们演示自己完成的软件产品(这个会议非常重要,一定不能取消);
8、最后就是 Sprint Retrospective Meeting(回顾会议),也称为总结会议,以轮流发言方式进行,每个人都要发言,总结并讨论改进的地方,放入下一轮Sprint的产品需求中;