一 写在前面
未经允许,不得转载, 谢谢~~~
之前写了一篇关于DPCNN文章解读的笔记,所以再整理了相关的数据集处理情况和实验情况一并分享出来,有需要的同学可以参考一下。
模型本身结构比较简单,具体的实现是应深度学习课程邱锡鹏教授的要求,基于fastNLP这个框架来实现的, 这个框架是邱老师团队为了简化NLP的编程而发布的,封装了一些dataloader,常见模型等,对于文本任务还是比较友好的。
实验选择了原论文中使用的一个AG news数据集进行论文结果的复现,原论文用了unsupervised embedding的训练方法能到93.13%(6.87%错误率),我和小组成员复现的情况在没有使用unsupervised embedding的情况下能都达到91.49%, 相差1.64%。
这边列了一些主要的资源信息:
- 论文原文: ACL2017- Deep Pyramid Convolutional Neural Networks for Text Categorization
- 论文blog:论文 | 《Deep Pyramid Convolutional Neural Networks for Text Categorization》DPCNN文本分类模型介绍
- 数据集-官网完整版: AG's corpus of news articles
- 数据集-分类任务集:AG news主题分类数据集
- fastNLP:fastNLP
二 网络模型及数据集介绍
2.1 DPCNN网络模型
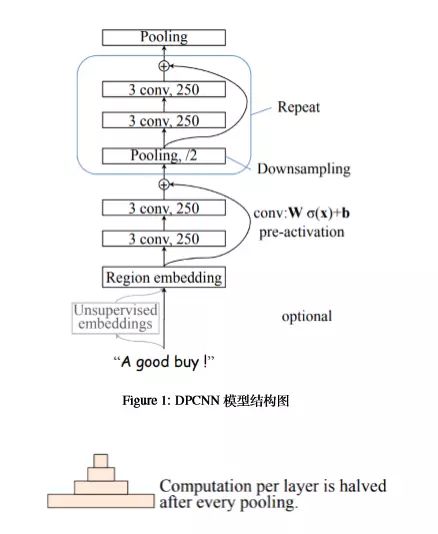
网络模型如上所示,具体的分析都写在上一篇博客里了, 这里的细节就不赘述了~
2.2 AG news数据集
- 我们采用的数据集是原论文使用的数据集之一 AG news。
- AG news是由 ComeToMyHead 超过一年的努力,从 2000 多不同的新闻来源搜集的超过 1 百万的新闻文章。
- 官网下载到完整的数据集的
newsSpace.bz2的格式为{ source,url,title,image,category,description,rank,pubdate,video }; 完整的数据集可以用于做数据挖掘(聚类,分类等、信息检索(排名,搜索等)等多种任务; - 本次实验采用其中的主题分类数据集由XiangZhang([email protected])从以上数据集中构建;
- 主题分类数据集文件从以上原始语料库中选择4个最大的类,每个类包含30,000训练样本和1900测试样本,因此总的训练样本是120,000,总的测试样本是7600。
- 主要数据文件说明如下:
-
classes.txt包含包含类名称,即:World、Sports、Business、Sci/Tec; -
train.csv和test.csv包含了逗号分隔的3栏,格式为 { label, title,description },分别是类索引 (1-4), 标题和描述; - 标题和描述都有双引号""包含,其中的内部引号由双重引号标出,新行由\n分隔;
-
三 具体实现过程
1 全局路径和全局变量:util.py
- 主要定义了数据集的路径和一些全局变量;
- 这些参数直接在这个文件里修改即可。
# some global varible
dataset_path = 'dataset/'
classes_txt = dataset_path + 'classes.txt'
train_csv = dataset_path + 'train.csv'
test_csv = dataset_path + 'test.csv'
pickle_path = 'result/'
# some global variable
word_embedding_dimension = 300
num_classes = 4
2 数据加载文件:dataloader.py
- 主要是用AG news数据集进行处理生成
dataset_train和dataset_test; - 具体实现主要基于fastNLP
- 主要的处理流程包括:
- 读入数据;
- label转为int类型;
- title和description转小写;
- 用空格分割description得到单词序列;
- 计算单词序列的长度并得到文本中最大的句子包含的句子长度
max_se_len - 根据训练数据构建词汇表;
- 根据词汇表将每个单词序列中的单词提换出呢个对应的单词id;
- 对短的单词序列用0做padding,全部变成等长的序列(DPCNN模型需要);
- 可以按照以上的处理思路自己用PyTorch写一个数据加载的代码,也可以按照fastNLP的需求配置创建一个虚拟环境(我自己是创建了一个名为
fastnlp的虚拟环境的) - 这部分的代码文件比较长:
from fastNLP import DataSet
from fastNLP import Instance
from fastNLP import Vocabulary
from utils import *
# read csv data to DataSet
dataset_train = DataSet.read_csv(train_csv,headers=('label','title','description'),sep='","')
dataset_test = DataSet.read_csv(test_csv,headers=('label','title','description'),sep='","')
# preprocess data
dataset_train.apply(lambda x: int(x['label'][1])-1,new_field_name='label')
dataset_train.apply(lambda x: x['title'].lower(), new_field_name='title')
dataset_train.apply(lambda x: x['description'][:-2].lower()+' .', new_field_name='description')
dataset_test.apply(lambda x: int(x['label'][1])-1,new_field_name='label')
dataset_test.apply(lambda x: x['title'].lower(), new_field_name='title')
dataset_test.apply(lambda x: x['description'][:-2].lower()+ ' .', new_field_name='description')
# split sentence with space
def split_sent(instance):
return instance['description'].split()
dataset_train.apply(split_sent,new_field_name='description_words')
dataset_test.apply(split_sent,new_field_name='description_words')
# add item of length of words
dataset_train.apply(lambda x: len(x['description_words']),new_field_name='description_seq_len')
dataset_test.apply(lambda x: len(x['description_words']),new_field_name='description_seq_len')
# get max_sentence_length
max_seq_len_train=0
max_seq_len_test=0
for i in range (len(dataset_train)):
if(dataset_train[i]['description_seq_len'] > max_seq_len_train):
max_seq_len_train = dataset_train[i]['description_seq_len']
else:
pass
for i in range (len(dataset_test)):
if(dataset_test[i]['description_seq_len'] > max_seq_len_test):
max_seq_len_test = dataset_test[i]['description_seq_len']
else:
pass
max_sentence_length = max_seq_len_train
if (max_seq_len_test > max_sentence_length):
max_sentence_length = max_seq_len_test
print ('max_sentence_length:',max_sentence_length)
# set input,which will be used in forward
dataset_train.set_input("description_words")
dataset_test.set_input("description_words")
# set target,which will be used in evaluation
dataset_train.set_target("label")
dataset_test.set_target("label")
# build vocabulary
vocab = Vocabulary(min_freq=2)
dataset_train.apply(lambda x:[vocab.add(word) for word in x['description_words']])
vocab.build_vocab()
# index sentence by Vocabulary
dataset_train.apply(lambda x: [vocab.to_index(word) for word in x['description_words']],new_field_name='description_words')
dataset_test.apply(lambda x: [vocab.to_index(word) for word in x['description_words']],new_field_name='description_words')
# pad title_words to max_sentence_length
def padding_words(data):
for i in range(len(data)):
if data[i]['description_seq_len'] <= max_sentence_length:
padding = [0] * (max_sentence_length - data[i]['description_seq_len'])
data[i]['description_words'] += padding
else:
pass
return data
dataset_train= padding_words(dataset_train)
dataset_test = padding_words(dataset_test)
dataset_train.apply(lambda x: len(x['description_words']), new_field_name='description_seq_len')
dataset_test.apply(lambda x: len(x['description_words']), new_field_name='description_seq_len')
dataset_train.rename_field("description_words","description_word_seq")
dataset_train.rename_field("label","label_seq")
dataset_test.rename_field("description_words","description_word_seq")
dataset_test.rename_field("label","label_seq")
print("dataset processed successfully!")
3 网络模型实现:model.py
- 这个在github上也能找到一些代码;
- 基于PyTorch实现的;
- 实现的时候参考了一个源码, 但是修改了他的一点小问题(添加了漏掉的一处shortcut);
- 贴一下修改之后的吧:
import torch
import torch.nn as nn
class ResnetBlock(nn.Module):
def __init__(self, channel_size):
super(ResnetBlock, self).__init__()
self.channel_size = channel_size
self.maxpool = nn.Sequential(
nn.ConstantPad1d(padding=(0, 1), value=0),
nn.MaxPool1d(kernel_size=3, stride=2)
)
self.conv = nn.Sequential(
nn.BatchNorm1d(num_features=self.channel_size),
nn.ReLU(),
nn.Conv1d(self.channel_size, self.channel_size, kernel_size=3, padding=1),
nn.BatchNorm1d(num_features=self.channel_size),
nn.ReLU(),
nn.Conv1d(self.channel_size, self.channel_size, kernel_size=3, padding=1),
)
def forward(self, x):
x_shortcut = self.maxpool(x)
x = self.conv(x_shortcut)
x = x + x_shortcut
return x
class DPCNN(nn.Module):
def __init__(self,max_features,word_embedding_dimension,max_sentence_length,num_classes):
super(DPCNN, self).__init__()
self.max_features = max_features
self.embed_size = word_embedding_dimension
self.maxlen = max_sentence_length
self.num_classes=num_classes
self.channel_size = 250
self.embedding = nn.Embedding(self.max_features, self.embed_size)
torch.nn.init.normal_(self.embedding.weight.data,mean=0,std=0.01)
self.embedding.weight.requires_grad = True
# region embedding
self.region_embedding = nn.Sequential(
nn.Conv1d(self.embed_size, self.channel_size, kernel_size=3, padding=1),
nn.BatchNorm1d(num_features=self.channel_size),
nn.ReLU(),
nn.Dropout(0.2)
)
self.conv_block = nn.Sequential(
nn.BatchNorm1d(num_features=self.channel_size),
nn.ReLU(),
nn.Conv1d(self.channel_size, self.channel_size, kernel_size=3, padding=1),
nn.BatchNorm1d(num_features=self.channel_size),
nn.ReLU(),
nn.Conv1d(self.channel_size, self.channel_size, kernel_size=3, padding=1),
)
4 训练网络:train.py
- 这部分也是用了fastNLP的借口,总共就没几行代码:
from utils import *
from model import *
from dataloader import *
from fastNLP import Trainer
from copy import deepcopy
from fastNLP.core.losses import CrossEntropyLoss
from fastNLP.core.metrics import AccuracyMetric
from fastNLP.core.optimizer import Adam
from fastNLP.core.utils import save_pickle
# load model
model=DPCNN(max_features=len(vocab),word_embedding_dimension=word_embedding_dimension,max_sentence_length = max_sentence_length,num_classes=num_classes)
# define loss and metric
loss = CrossEntropyLoss(pred="output",target="label_seq")
metric = AccuracyMetric(pred="predict", target="label_seq")
# train model with train_data,and val model with test_data
# embedding=300 gaussian init,weight_decay=0.0001, lr=0.001,epoch=5
trainer=Trainer(model=model,train_data=dataset_train,dev_data=dataset_test,loss=loss,metrics=metric,save_path=None,batch_size=64,n_epochs=5,optimizer=Adam(lr=0.001, weight_decay=0.0001))
trainer.train()
# save pickle
save_pickle(model,pickle_path=pickle_path,file_name='new_model.pkl')
5 测试网络:test.py
- 这个就更简单了哈哈哈
- 其中
trained_model.pkl就是我们训练好之后的网络模型;
from utils import *
from model import *
from dataloader import *
from fastNLP import Tester
from fastNLP.core.metrics import AccuracyMetric
from fastNLP.core.utils import load_pickle
# define model
model=DPCNN(max_features=len(vocab),word_embedding_dimension=word_embedding_dimension,max_sentence_length = max_sentence_length,num_classes=num_classes)
# load checkpoint to model
load_model = load_pickle(pickle_path=pickle_path, file_name='trained_model.pkl')
# use Tester to evaluate
tester=Tester(data=dataset_test,model=load_model,metrics=AccuracyMetric(pred="predict",target="label_seq"),batch_size=4)
acc=tester.test()
print(acc)
四 实验结果
1 中间过程
训练阶段一共做了以下几组对比实验来确定比较好的训练条件,大家也可以参考一下:
-
关于语料选择
AG文本分类语料库由{label,title,description}三者构成,DPCNN论文中没有明确指出分类任务时使用的是 title 还是 description,因此我们在其他条件不变的情况下进行了分别使用 title 和 description 的对比实验。
具体实验设置情况如下所示:- 实验 1:input=title, word_embedding=300, embedding_init = random, batch_size=32, lr=0.01, epoch=5;
- 实验 2:input=description, word_embedding=300, embedding_init = random, batch_size =32, lr=0.01, epoch=5;
- 实验2优于实验1;
-
关于batch_size选择
原论文中选用了batch_size=100,但考虑到设备的限制,在实验复现的过程中我们 选择了较为常见的32和64进行对比实验。在原来实验2的基础上新增加一组batch_size=64, 其他条件保持不变的实验 3,具体实验设置情况如下所示:- 实验2:input=description,word_embedding=300,embedding_init=random,batch_size= 32, lr=0.01, epoch=5;
- 实验3:input=description,word_embedding=300,embedding_init=random,batch_size= 64, lr=0.01, epoch=5;
- 实验3优于实验2;
-
关于word_embedding的选择
在复现的过程中我们选择了三个不同纬度的 embedding,分别为 300、500 和 100 进行网络模型的训练和测试。并基于以上两组实验的结果,选用 descrition 语料集并将 batch_size 设置为 64. 具体的实验设置如下所示:- 实验4:input=description,word_embedding=300,embedding_init=random,batch_size= 64, lr=0.01, epoch=5;
- 实验5:input=description,word_embedding=500,embedding_init=random,batch_size= 64, lr=0.01, epoch=5;
- 实验6:input=description,word_embedding=100,embedding_init=random,batch_size= 64, lr=0.01, epoch=5;
- 符合参数越多,网络能表示信息越多,但是越难训练的规律;
learning_rate调整
以上实验都采用的是 0.01 的 learning_rate,但是从实验情况看到几乎每个实验随着训练的进行,其在测试集上的表现都是动荡的。因此考虑到使用的数据集比较小,所以在接下 来的实验中将学习率由原来的 0.01 调整为 0.001,希望网络模型能够更加稳定。
注:关于每个具体的实验结果情况和实验分析我就不再详细描述了,也是一些非常基础的内容.....
2 最终实验
综合考虑以上几组对比实验的结果,以及考虑 learning_rate 的调整选择最优的实 验条件重新进行网络模型的训练过程。另外还在原来的实验基础上参考原论文设置加入了 weight_decay=0.0001的正则化项。最终保留word_embedding=300和word_embedding的100 两项展开实验。
具体的实验设置情况如下所示:
- 实验8:input=description,word_embedding=300,embedding_init=gaussian,batch_size= 64, lr=0.001, epoch=5;
- 实验9:input=description,word_embedding=100,embedding_init=gaussian,batch_size= 64, lr=0.001, epoch=5;
实验结果
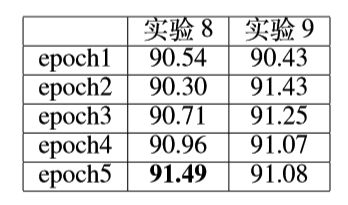
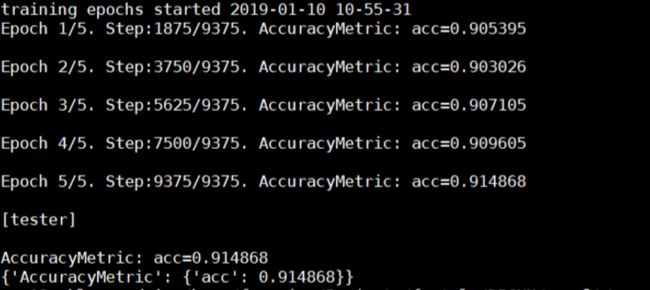
在没有用unsupervised embeding的情况下,最佳训练条件下得到的实验结果如图能够在测试集上达到 91.49% 的准确度,与DPCNN 原论文展示的 93.13% 仅相差 1.64%。
五 写在最后
暂时就先写这么多吧~~~~
写完一个报告又整理一篇博客的肌肉酸痛感,啊啊啊~如果觉得还可以的话,点个喜欢可以不可以呢(-o⌒) ☆
后面等我想整理的时候再传到github上好了。