机器学习实战笔记-knn算法实战
本文内容源于《机器学习实战》一书,主要介绍了knn(k-nearest neighbor)算法的原理、python代码实现、以及两个简单的应用案例。
一般步骤
机器学习一般流程如下,主要包括从数据获取到预处理,到分析数据筛选特征最后到模型训练、选择、评估、使用的过程。
1.收集数据
2.输入数据(字符型、数值型)
3.分析数据(空置、异常值、缺失值.....垃圾数据)
4.训练算法
5.测试算法,5--->4/1,根据测试结果返回4或者1继续。
6.使用算法
需要掌握的知识
- Numpy基础
需要用到numpy的一些基础,这部分内容对自己用代码实现算法帮助很大。涉及到<数组,矩阵,计算>等操作,需要用到什么可以学习或者检索相关的api。 - matplotlib基础
这个库是python中涉及到图形绘制,可以展现数据的规律。 - 基本的算法及数学知识,包括<高数、线性代数、概率论>知识。
knn(k-nearest neighbor)算法
用于测量不同特征值之间的距离进行分类。
- 优点:精度高、
异常值不敏感、无数据输入假定 - 缺点:计算复杂、
空间复杂 - 适用数据:数值型、标签型
算法原理:在已经有分类标签的数据集中,输入无标签的新数据,计算新数据特征和训练集特征的距离,选择排名前k个最近的距离,统计这些属于哪个类别。
- 伪代码:
- 计算未知点和数据集中已知点的距离
- 按距离递增排序
- 选取与当前点距离最小的k个点
- 计算类别频率
- 返回频率最高的类别作为分类结果
k-最近邻算法核心代码
'''
knn
inX:测试集
dataSet:训练集
labels:标签
K:选取前K个值
'''
def classify0(inX,dataSet,labels,k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX,(dataSetSize,1)) - dataSet
#tile用于把inX横向或者纵向复制,即把inX扩充成于dataSet相同维度。
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis = 1)
distances = sqDistances**0.5
sorteDistIndicies = distances.argsort()
#计算距离,新数据每个点和训练集的距离;
#argsort(),排序并返回原数组索引.
#[8,2,1,4,5,7]--->index[0:k]---->取k个索引
classCount = {}
for i in range(k):
voteIlabel = labels[sorteDistIndicies[I]]
classCount[voteIlabel] = classCount.get(voteIlabel,0)+1
#遍历,排序后前k个索引,labels[index]--->类别
#字典get方法,统计类别次数,没有返回0,次数+1
sortedClassCount = sorted(classCount.items(),
key = operator.itemgetter(1),reverse =True)
return sortedClassCount[0][0]
对于上述代码,其实可以拆解成以下2部分更容易理解:
- 首先是计算距离
- 其次是统计k范围内类别个数
关于距离的计算,其实距离的选择有很多种,因此产生了许多对knn算法的改进版本:比如距离加权knn等
自己将书上的代码拆成2块便于理解,有一点小区别在于:对字典按值进行排序,例子用了operator.itemgetter()方法,自己用了字典的items()方法.
代码中的技巧和思路:1.数组排序后返回索引--
array.argsort()方法;2.统计某一类别出现的次数,巧妙用了字典的get()方法。
'''
knn:
1.计算距离
2.升序排序,选k值
3.计算类别概率
'''
#计算测试数据和训练集所有点的距离,返回排序后的索引
def CountDistance(sample,d_train):
Size = d_train.shape[0]
diffMat = tile(sample,(Size,1)) - d_train
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
dist_index = distances.argsort()
return dist_index
#统计类别,返回前k个距离最多的类别
classCount ={}
def LabelCount(dist_index,k,labels):
for i in range(k):
kind = labels[dist_index[I]]
‘’‘
思路很优秀,利用字典的get方法,来统计相应类别在前k个距离中出现的次数,得到类似的结果{'A':10,'B':3},然后根据字典的值进行降序排序,即可得到结果。
’‘’
classCount[kind] = classCount.get(kind,0)+1
result = sorted(classCount.items(),key = lambda x:x[1],reverse=True)
return result[0][0]
#函数整合在一起
def knn(sample,d_train,k,labels):
dist_index = CountDistance(sample,d_train)
result = LabelCount(dist_index,k,labels)
return result
小结:这个是python实现的最基础的knn核心代码,主体思想就是
距离计算和统计标签类别。
练习题-1
海伦约会对象分类案例
按照1-6的步骤进行,需要进行测试
数据准备
将txt文件,按行读取,转化成数组(因为元素可以是字符串和数);不必按照书上做,太繁琐,先根据文件行数设置空矩阵,然后往里填数字。
import numpy as np
filename = 'datingTestSet.txt'
path = '/Users/tony/github/machine-learning-in-action/k-Nearest Neighbor/'+filename
def load_txt(filename):
f = open(filename,'r')
mid= f.readlines()
mid2 = [x.strip('\n').split('\t') for x in mid]
arr = np.array(mid2)
labels = arr[:,3]
groups = arr[:,0:3]
return groups,labels
分析数据
拿到数据首先要对数据进行观察,由于只有3个特征,可以做散点图来查看特征之间的关系。需要用到matplotlib绘图功能。
import matplotlib.pyplot as plt
def plot(dt,labels):
plt.figure()
a1 = np.char.replace(labels,'largeDoses','r')
a2 = np.char.replace(a1,'didntLike','b')
a3 = np.char.replace(a2,'smallDoses','g')
c = a3
plt.scatter(dt[:,0],dt[:,1],c=a3,marker='o',alpha=0.5)
plt.xlabel('pilot distance')
plt.ylabel('game time')
plt.legend(loc =2 ,)
plt.show()
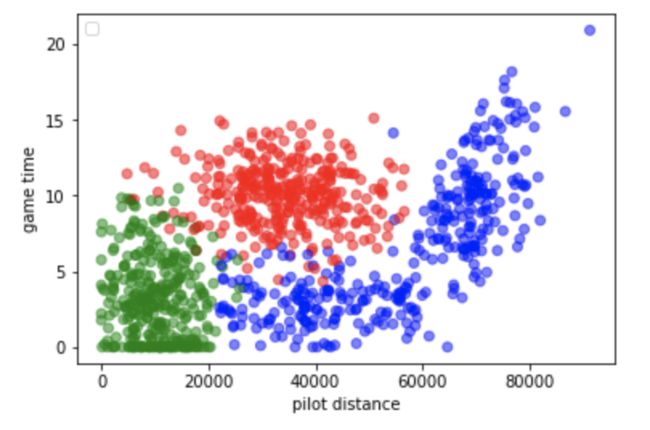
关于三类对象的游戏时间和旅行距离的散点图,通过将三类人的类别标签映射到图像上,可以使得数据更为明显。说明海伦在意的对象类型和游戏时间以及旅行距离有明显的联系。
观察数据可以发现,旅行距离的数值要远大于游戏和冰淇淋的值,为了避免这个值太大而对另外两个特征造成影响,需要进行数据的归一化处理。
归一化数值:0-1归一化,new = (old - min) / (max - min)
- 使用现成的
sklearn包更为便捷
因为已经得到现成的特征向量,所以直接归一化就行了 - 虽然也可以写一个函数来实现归一化,但是效率不高。
测试分类器
用错误率来衡量分类结果
- 涉及到训练集和测试集的划分:
- 关于数据划分,可以直接用sklearn的
train_test_split,在model_selection下。(但这样划分,缺少验证集)- 其中
random_state代表随机种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。 - 随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。
- 其中
- 每一个测试样本带入分类器,查看分类结果,判断并记录下对错
- 可以使用交叉验证和留出法对数据进行划分。
- 关于数据划分,可以直接用sklearn的
分类器测试结果
- 以下是用于测试分类结果的函数,输出为分类错误率。
这个结果仅对于
一次样本划分的数据集而言,而且k值选择仅为1次,所以这个函数里面的参数可以进一步改变,
<调参>,来查看不同数据划分和k值选择情况下分类结果是怎么样的。
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
def datingTest(X_test,X_train,y_train,test_size,k):
'''
knn测试
test_size:测试集大小
k:距离升序排序的前k个值
...
剩下的是划分的数据集
output:分类错误率
'''
error_rate = {'true':0,'false':0}
y_predict = []
for i in range(test_size):
result = classify0(X_test[i],X_train,y_train,20)
y_predict.append(result)
print('the classify result is : %s , the real answer is : %s'%(result,y_test[I]))
if result==y_test[I]:
error_rate['true'] += 1
else:
error_rate['false'] += 1
er_rate = error_rate['false']/100
return er_rate

当k选择20时,分类错误率为0.2,可以接受,说明分类效果良好。(当然,书上效果比较粗略,未考虑到数据集划分方式以及不同k值选取对分类结果的影响。)
使用算法
对于分类效果良好的模型,可以直接拿来使用。
关于判断约会对象的小程序基本功能和用法如下:
* 根据输入的3条属性,来给出这个人是否值得约会
* 在输入测试数据时,记得要对其进行归一化
最终的约会决策模型
def personDecision():
ice =float(input('ice cream consumed per year:'))
travel = float(input('travel distance per year:'))
game = float(input('game time per year:'))
person = np.array([travel,game,ice]).reshape(1,-1)
#需要归一化
person_norm = preprocessing.normalize(person, norm='l2')
decision = classify0(person_norm,X_train,y_train,20)
print('You might have %s with this guy.'%decision)
return
代码整合
将上述步骤代码整合如下:
import numpy as np
from numpy import *
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
import operator
def classify0(inX,dataSet,labels,k):
'''
knn分类器
-----------
inX:测试样本
dataSet:训练集
labels:训练标签
k:距离最近的前k个值
'''
dataSetSize = dataSet.shape[0]
diffMat = tile(inX,(dataSetSize,1)) - dataSet
#tile用于把inX横向或者纵向复制,即把inX扩充成于dataSet相同维度。
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis = 1)
distances = sqDistances**0.5
sorteDistIndicies = distances.argsort()
#计算距离,新数据每个点和训练集的距离;
#argsort(),排序并返回原数组索引.
#[8,2,1,4,5,7]--->index[0:k]---->取k个索引
classCount = {}
for i in range(k):
voteIlabel = labels[sorteDistIndicies[I]]
classCount[voteIlabel] = classCount.get(voteIlabel,0)+1
#遍历,排序后前k个索引,labels[index]--->类别
#字典get方法,统计类别次数,没有返回0,次数+1
sortedClassCount = sorted(classCount.items(),
key = operator.itemgetter(1),reverse =True)
return sortedClassCount[0][0]
'''
最终使用的约会对象分类模型
'''
def personDecision():
'''
约会对象筛选模型:
output:根据这个人的习惯:ice,travel,game,初步判断是否值得约会
'''
ice =float(input('ice cream consumed per year:'))
travel = float(input('travel distance per year:'))
game = float(input('game time per year:'))
person = np.array([travel,game,ice]).reshape(1,-1)
#需要归一化
person_norm = preprocessing.normalize(person, norm='l2')
decision = classify0(person_norm,X_train,y_train,20)
print('You might have %s with this guy.'%decision)
return
def load_txt(filename):
'''
读取数据集
'''
f = open(filename,'r')
#按行读取,返回list
mid= f.readlines()
mid2 = [x.strip('\n').split('\t') for x in mid]
arr = np.array(mid2)
labels = arr[:,3]
groups = np.array(arr[:,0:3],dtype=float)
return groups,labels
if __name__ =='__main__':
filename = 'datingTestSet.txt'
path = '/Users/tony/github/machine-learning-in-action/k-Nearest Neighbor/'+filename
G,L = load_txt(filename)
#归一化
G_normalized = preprocessing.normalize(G, norm='l2')
#划分数据集
X_train,X_test,y_train,y_test = train_test_split(G_normalized,L,test_size = 0.1,random_state = 21)
personDecision()
练习题-2
手写识别系统:
- 存在图像文件,是手写字体,存储为图像的形式,需要通过knn模型,识别出每幅图像真实的数字信息。
步骤如练习1
准备数据
因为数据集已经有了,需要做的是将其读取到python中
查看数据发现,数据是以txt文件保存的,每个文件都是数字排列组成的图像,文件名是这组数据代表的数字以及这个数字的样本编号
需要做的是将整个文件作为一个向量存储。涉及到矩阵的向量化处理。
思路是:
- 将每个文件读取成一个array
- 记录每个文件的label信息,根据文件名
- 由于已经分好了,不需要对数据集进行划分
手写识别模型代码汇总
- 主要包括:knn分类器
- 文件读取函数
read_file() - 图像转数组函数
changeTodataSet()
from numpy import *
import operator
import os
'''
手写识别模型
'''
def classify0(inX,dataSet,labels,k):
'''
knn分类器
-----------
inX:测试样本
dataSet:训练集
labels:训练标签
k:距离最近的前k个值
'''
dataSetSize = dataSet.shape[0]
diffMat = tile(inX,(dataSetSize,1)) - dataSet
#tile用于把inX横向或者纵向复制,即把inX扩充成于dataSet相同维度。
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis = 1)
distances = sqDistances**0.5
sorteDistIndicies = distances.argsort()
#计算距离,新数据每个点和训练集的距离;
#argsort(),排序并返回原数组索引.
#[8,2,1,4,5,7]--->index[0:k]---->取k个索引
classCount = {}
for i in range(k):
voteIlabel = labels[sorteDistIndicies[I]]
classCount[voteIlabel] = classCount.get(voteIlabel,0)+1
#遍历,排序后前k个索引,labels[index]--->类别
#字典get方法,统计类别次数,没有返回0,次数+1
sortedClassCount = sorted(classCount.items(),
key = operator.itemgetter(1),reverse =True)
return sortedClassCount[0][0]
def read_file(file,path):
'''
将图像文件读取成数组
file:文件名
output:该文件的数组向量
'''
PT = path+file
with open(PT,'r') as f:
txt = f.readlines()
mid_str = list(map(lambda x:x.strip('\n'),txt))
arr = []
for i in range(32):
mid_int = list(map(lambda x:int(x),mid_str[I]))
arr.extend(mid_int)
return array(arr)
def changeTodataSet(path):
'''
批量读取文件,成为数组,组成数据集
'''
dataList = os.listdir(path)
labels = array(list(map(lambda x:x.split('_')[0],dataList)))
group = array(list(map(lambda x:read_file(file = x,path=path),dataList)))
return group,labels
def HandwritingRecgnize():
'''
手写识别模型
output:识别结果,错误数量,识别错误率。
'''
num = len(group_text)
error = 0
for i in range(num):
predict_num = classify0(group_text[i],group_train,labels_train,20)
real_num = labels_text[I]
print('the predict num is : %s'%predict_num,'the real num is : %s'%real_num)
if predict_num !=real_num:error += 1
print('predict error time is :%d'%error)
print('total error rate is :%f'%(error/num))
return
if __name__ == '__main__':
group_train,labels_train = changeTodataSet('./digits/trainingDigits/')
group_text,labels_text = changeTodataSet('./digits/testDigits/')
HandwritingRecgnize()
尝试用sklearn来分类
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights=’uniform’, algorithm=’auto’, leaf_size=30, p=2, metric=’minkowski’, metric_params=None, n_jobs=None, **kwargs)¶
sklearn官方手册
从下面的结果可以看出
-
KNeighborsClassifier是一个knn的分类器,在设置好k值后确定分类模型 -
neigh.fit用训练样本的数据和标签去拟合这个模型 -
neigh.predict预测分类结果 -
neigh.score提供测试集计算模型分类精度
整理代码
通过调用sklearn的api可以得到更简洁的代码
from numpy import *
import numpy as np
import operator
import os
from sklearn.neighbors import KNeighborsClassifier
def read_file(file,path):
'''
将图像文件读取成数组
file:文件名
output:该文件的数组向量
'''
PT = path+file
with open(PT,'r') as f:
txt = f.readlines()
mid_str = list(map(lambda x:x.strip('\n'),txt))
arr = []
for i in range(32):
mid_int = list(map(lambda x:int(x),mid_str[I]))
arr.extend(mid_int)
return array(arr)
def changeTodataSet(path):
'''
批量读取文件,成为数组,组成数据集
'''
dataList = os.listdir(path)
labels = array(list(map(lambda x:x.split('_')[0],dataList)))
group = array(list(map(lambda x:read_file(file = x,path=path),dataList)))
return group,labels
def sk_knn():
'''
用sklearn在做knn分类
'''
neigh = KNeighborsClassifier(n_neighbors=20)
neigh.fit(group_train,labels_train)
result = neigh.predict(group_text)
accuracy = neigh.score(group_text,labels_text)
return result,accuracy
if __name__ == '__main__':
group_train,labels_train = changeTodataSet('./digits/trainingDigits/')
group_text,labels_text = changeTodataSet('./digits/testDigits/')
result,accuracy = sk_knn()
num = len(result)
for i in range(num):
predict_num = result[I]
real_num = labels_text[I]
print('the predict num is :%s'%predict_num,'the real num is :%s'%real_num)
print('the accuracy of this model is :%f'%accuracy)
update 18.12.10
在阅读机器学习相关书籍时,回顾了一下knn算法,其中关于knn计算开销的问题,在《统计学习方法》一书中提到,可以采用kd树来减小计算量,附上笔记和学习感悟。
knn算法实现-->kd树
最简单的方法是线性扫描,但计算量会随训练集增大开销增大。
所以可以用kd-tree来提高效率,减少计算距离的次数。
首先来学习一下树结构--->
二叉查找树定义:每棵二叉查找树都是一棵二叉树,每个结点有一个comparable键,每个结点的键都大于左子树任意结点的键,小于右子树任意结点的键。-----《算法》
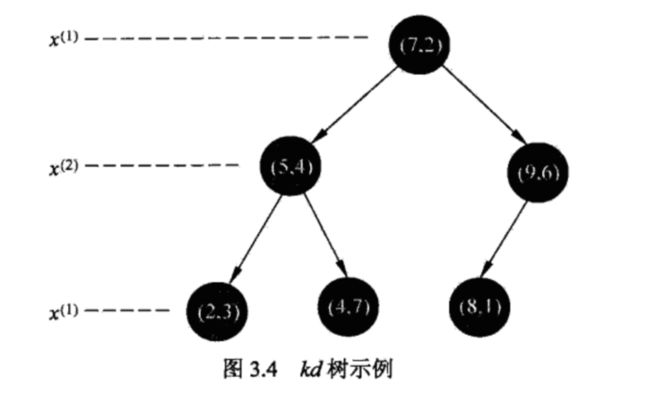
构造kd树
平衡kd树:
- 1.根结点-->找x^(1) 的特征坐标中位数作为切分点,将区域分成2个子区域,过x^(i),垂直坐标轴;
- 2.由根结点生成深度为1的左右子节点;left < x^(i),right > x^(i),保存实例点在根结点中;
- 3.递归
- 4.直到两个子区域没有实例停止

文字可能比较难理解,但是结合这个例题,可以轻松了解。
首先将这个数据集T,
T是一个6行2列的数组,按照特征顺序,比如第一个特征,即T中的第一列,取出[2,5,9,4,8,7],按中位数7,排序,类似于二分查找,7左边的数字都要小于7,7右边的数字要大于7,于是数据集被分成2个子集;
接下来对两个子集继续用上述的方法递归即可(
用第二个特征进行递归,以此类推)
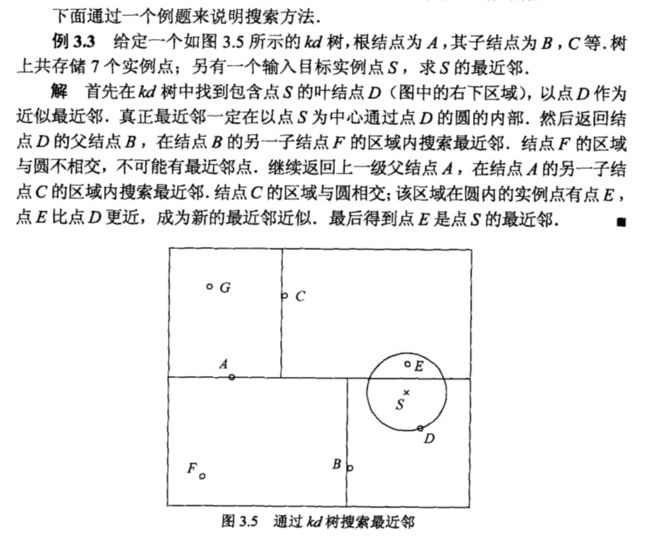
搜索kd树
目标点x;kd树
- 找出包含x的叶结点-->从根结点出发,递归访问kd树,目标节点当前维的坐标小于切分点的坐标,左移;否则右移,直到子结点是终点。
- 把该结点作为'当前最近点'
- 递归向上退回,对每个结点如下操作:
- a)结点实例点比当前最近点与目标点更近,则该点为当前最近点
- b)查找同一结点下另一子节点中的实例点,是否画圆可以相交,可以则将其作为'当前最近点'重新定义半径,继续递归;不相交退回到上一结点。
- 当退回到根结点时,结束搜索
小结
通过2个例子的练习:约会对象分类、手写识别分类。发现knn算法存在一些问题:
-
算法核心在于计算测试样本与训练集所有样本之间的距离
- 首先对于
样本量的需求极大,需要足够多的训练样本才能保证模型的精度; - 其次对于大数据集
计算开销巨大,非常耗时间; - 第三,关于
k值选取,需要人工调参,不同k值带来的分类结果不尽相同,同时,knn判别的距离也有多种,比如3个点,A,B1,B2。测试数据点离A更近,而离B更远,选择不同距离判断方式带来的分类情况不同。
- 首先对于
-
在算法实现过程中的一些注意事项
- 数据集导入过程中,需要将其转化为数组的形式(特征向量),便于计算机处理;
- 在
准备数据的过程中,需要对数据进行归一化、去除异常值、填补缺失值等一系列操作,这一过程可以统称为特征工程(虽然这两个例子的数据都是干净的,无需太多处理); -
测试算法过程中涉及到模型评估以及最终模型的选择,需要涉及到数据集划分、调参等工作; - 需要熟悉
numpy、sklearn等库等操作,可以极大提高工作效率减少代码量,做到有的放矢有重点的将时间花在其他重要的方面。
推荐阅读
1.《机器学习实战》
2.sklearn-nearest neighbors
3.《统计学习方法》