
看到本笔记系列的名字么?:R在数量生态学中的应用--矩阵·度量·聚类·排序·空间。其实到排序这一部分已经算是接近尾声了,因为空间分析哪一部分我打算放弃,目前的生态数据规模很少有空间数据。接下来,搬好小板凳,咱们好好讲讲排序。
如果说聚类分析的目的在于寻找数据的间断性,那么排序(ordination)的目的就在于寻找数据的连续性(通过连续的排序轴展示数据的主要趋势)。
要讲排序就要知道我们是在哪里排序,这里就引出多维空间的概念。假设我有10个样本的物种丰度表:
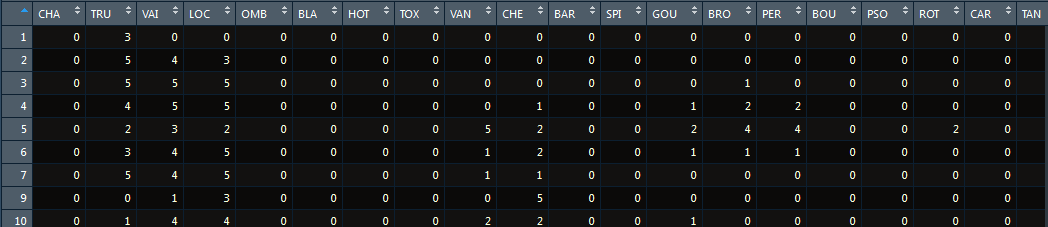
行为样本,列为物种(也可以理解为特征)。我们要对这10个样本进行排序:
- 假如只有一个物种: 那么根据这一个物种在每个样本中的值就可以排序啦。
- 假如有两个物种("CHA", "TRU"):我们可以建立二维坐标轴,横坐标是"CHA",纵坐标为TRU,根据这两个物种的值,我们也可以画出点来。
- 假如有三个物种:那么就是三维坐标来画点,也是可以画的。
那么大于三个物种的时候呢?那就是n维空间中的点了,是无法画出来的。
所以我们要找到一种方法,将n维空间中的点,在二维平面内展现出来。
由于这么多的点无法共面,所以要找到一个平面,使空间中的所有点都能投影在这个平面上,而且投影的点之间的距离,越能反应真实距离越好。这个投影过程就是排序运算过程。好的排序方法是投影过程信息损失最少。
排序的主要目的之一是生成可视化的排序图,这就决定了排序过程实际上是讲多维空间的数据尽可能的数据点排列在可视化的低维空间,也就是使最前面的几个排序轴尽可能包含数据结构变化的主要趋势。本章讲的非约束排序只是描述性方法,不存在检验评估排序结果是否显著性的问题,下一章约束排序则需要对排序结果进行显著性检验。
降维空间内的排序
大部分排序方法(NMDS除外)都是基于关联矩阵特征向量的提取。这也产生一个问题:多少个排序轴值得保留和解读?
PCA
如果一个数据矩阵中每个变量都是正态分布,这样的矩阵可以称作多元正态分布矩阵。PCA排序分析的对象是离差矩阵(dispersion matrix),即包含方差和协方差的变量之间的关联矩阵,或不同纲量的变量之间的相关系数矩阵。可见,如果变量之间不相关,PCA的分析也就没有意义了。PCA致力于分析定量数据,展示对象的欧氏距离,线性关系。
使用rda()函数对Doubs环境数据进行PCA分析
# 导入本章所需的程序包
library(ade4)
library(vegan)
library(gclus)
library(ape)
rm(list = ls())
setwd("D:\\Users\\Administrator\\Desktop\\RStudio\\数量生态学\\DATA")
# 导入CSV文件数据
spe <- read.csv("DoubsSpe.csv", row.names=1)
env <- read.csv("DoubsEnv.csv", row.names=1)
spa <- read.csv("DoubsSpa.csv", row.names=1)
# 删除没有数据的样方8
spe <- spe[-8,]
env <- env[-8,]
spa <- spa[-8,]
# 显示环境变量数据集的内容
summary(env) # 描述性统计
# 全部环境变量数据的PCA分析(基于相关矩阵:参数scale=TURE)
# ********************************************************
env.pca <- rda(env, scale=TRUE) # 参数scale=TRUE 表示对变量进行标准化
env.pca
Call: rda(X = env, scale = TRUE)
Inertia Rank
Total 11
Unconstrained 11 11
Inertia is correlations
Eigenvalues for unconstrained axes:
PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8 PC9 PC10 PC11
6.098 2.167 1.038 0.704 0.352 0.319 0.165 0.112 0.023 0.017 0.006
summary(env.pca) # 默认scaling=2
summary(env.pca, scaling=1)
注意函数summary()内的参数scaling,为绘制排序图所选择的标尺类型,与函数rda()内数据标准化的参数scale无关。
Call:
rda(X = env, scale = TRUE)
Partitioning of correlations:
Inertia Proportion
Total 11 1
Unconstrained 11 1
Eigenvalues, and their contribution to the correlations
Importance of components:
PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8 PC9 PC10 PC11
Eigenvalue 6.0980 2.1671 1.03760 0.70351 0.35185 0.31913 0.16455 0.11171 0.023109 0.017361 0.0060618
Proportion Explained 0.5544 0.1970 0.09433 0.06396 0.03199 0.02901 0.01496 0.01016 0.002101 0.001578 0.0005511
Cumulative Proportion 0.5544 0.7514 0.84570 0.90966 0.94164 0.97066 0.98561 0.99577 0.997871 0.999449 1.0000000
Scaling 1 for species and site scores
* Sites are scaled proportional to eigenvalues
* Species are unscaled: weighted dispersion equal on all dimensions
* General scaling constant of scores: 4.189264
Species scores
PC1 PC2 PC3 PC4 PC5 PC6
das 1.45634 1.1597 -0.83818 -0.6394 1.1820 -0.5578
alt -1.40158 -1.3396 0.58576 0.4854 0.7004 0.8234
pen -0.77254 -1.1499 -1.80693 -3.1715 0.1565 1.1780
(......)
Site scores (weighted sums of species scores)
PC1 PC2 PC3 PC4 PC5 PC6
1 -1.05160 -0.65504 -0.536188 -0.74739 0.04135 0.08372
2 -0.77560 -0.36292 0.104662 0.13751 0.16547 -0.30155
3 -0.70642 -0.21672 0.417881 -0.05503 0.18807 -0.11896
4 -0.65572 -0.13076 0.064532 0.16799 -0.04275 -0.01082
5 -0.31707 -0.29517 0.238423 0.19922 0.11293 0.20052
(······)
PCA 结果术语:
Inertia (惯量):变量自相关系数的总和,也等于变量的个数。
Constrained Unconstrained (约束非约束):PCA是非约束排序
Eigenvalue (特征根):每个排序轴重要性(方差)的指标,可以用特征根数值,也可以用占总变差的比例表示(每轴特征根除以总惯量)
-
Scaling(标尺):排序结果投影到排序空间的可视化方式。
- Scaling1(1型标尺)=(distance biplot,距离双序图):特征向量被标准化为单位长度,关注的是对象之间的关系。双序图中对象之间的距离近似于欧氏距离,代表变量的箭头之间的夹角没有意义。
- Scaling2 (2型标尺)=(correlation,biplot 相关双序图):特征向量被标准化为特征根的平方根,关注的是变量之间的关系。双序图中对象之间的距离不再近似于欧氏距离,代表变量的箭头之间的夹角反映变量之间的相关性。
Species scores:变量箭头在排序图中的坐标
Site scores : 对象在排序图中的坐标。
提取、解读和绘制vegan程序输出的PCA结果
PCA不是统计检验,而是一种探索分析方法,其目的是在低维空间尽可能多滴展示数据的主要趋势特征。选择多少个排序轴并没有统一的标准。不过也有两种判别方法:
- Kaiser-Guttman准则
- 断棍模型(broken stick model)
# 查看和绘制PCA输出的部分结果
# ****************************
?cca.object # 解释vegan包输出的排序结果对象结构和如何提取部分结果
# 特征根
(ev <- env.pca$CA$eig)
PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8 PC9 PC10 PC11
6.097995220 2.167125814 1.037602930 0.703508127 0.351852003 0.319125849 0.164550682 0.111707052 0.023109109 0.017361390 0.006061823
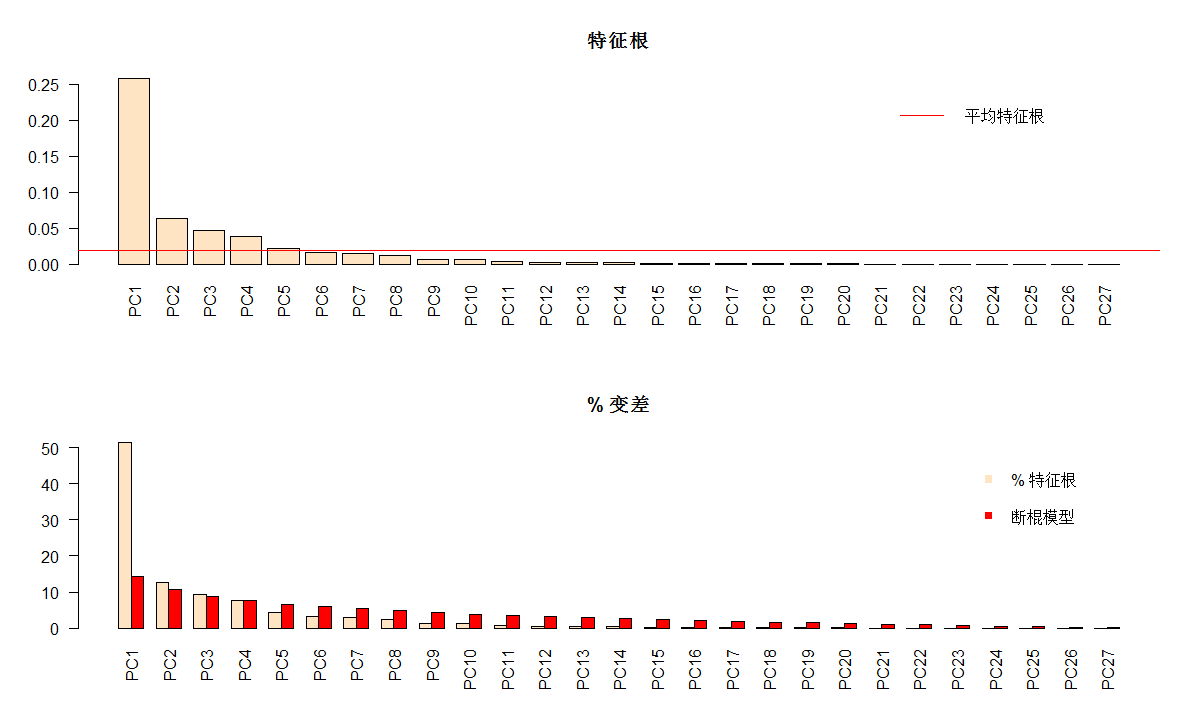
# 应用Kaiser-Guttman准则选取排序轴
PC1 PC2 PC3
6.097995 2.167126 1.037603
# 断棍模型
n <- length(ev)
bsm <- data.frame(j=seq(1:n), p=0)
bsm$p[1] <- 1/n
for (i in 2:n) {
bsm$p[i] = bsm$p[i-1] + (1/(n + 1 - i))
}
bsm$p <- 100*bsm$p/n
bsm
j p
1 1 0.8264463
2 2 1.7355372
3 3 2.7456382
4 4 3.8820018
5 5 5.1807031
6 6 6.6958547
7 7 8.5140365
8 8 10.7867637
9 9 13.8170668
10 10 18.3625213
11 11 27.4534304
# 绘制每轴的特征根和方差百分比
par(mfrow=c(2,1))
barplot(ev, main="特征根", col="bisque", las=2)
abline(h=mean(ev), col="red") # 特征根平均值
legend("topright", "平均特征根", lwd=1, col=2, bty="n")
barplot(t(cbind(100*ev/sum(ev),bsm$p[n:1])), beside=TRUE,
main="% 变差", col=c("bisque",2), las=2)
legend("topright", c("% 特征根", "断棍模型"),
pch=15, col=c("bisque",2), bty="n")
#两种方法是否保留相同的轴数?
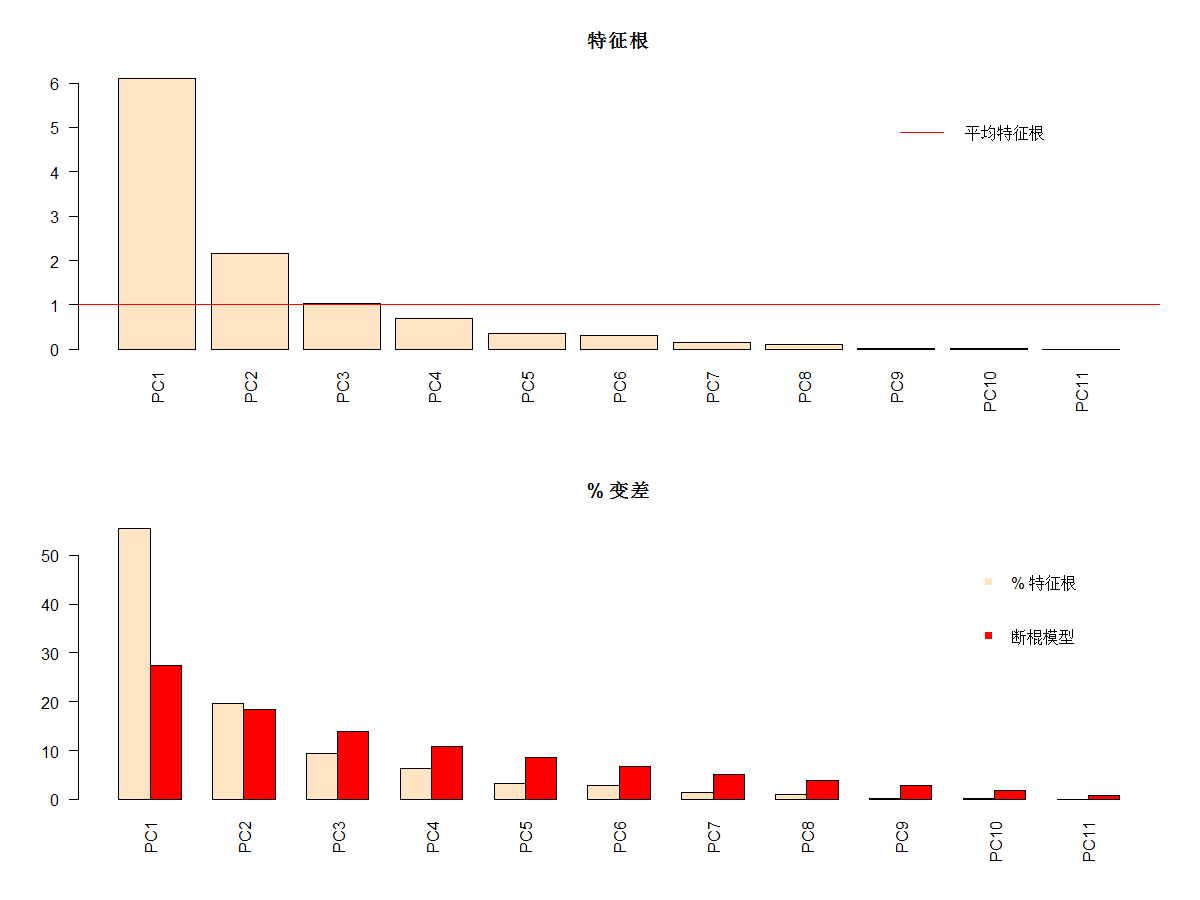
样方和变量的双序图
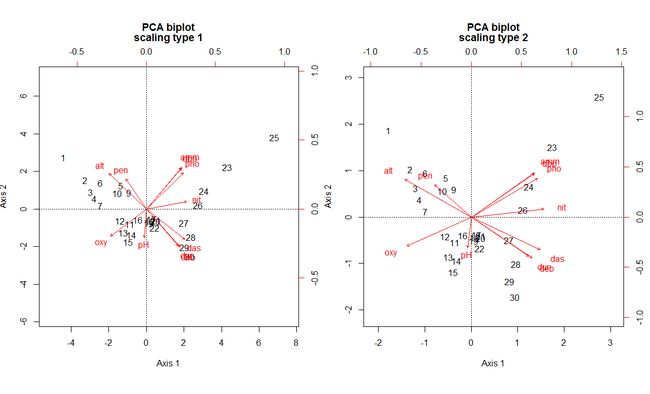
两种PCA双序图:1型标尺和2型标尺
#********************************
# 使用biplot()函数绘制排序图
par(mfrow=c(1,2))
biplot(env.pca, scaling=1, main="PCA-1型标尺")
biplot(env.pca, main="PCA-2型标尺") # 默认 scaling = 2

# 使用cleanplot.pca()函数绘图
source("cleanplot.pca.R")
cleanplot.pca(env.pca, point=TRUE)
# point=TRUE表示样方用点表示,变量用箭头表示

cleanplot.pca(env.pca)
# 默认样方仅用序号标识(同vegan包的标准)
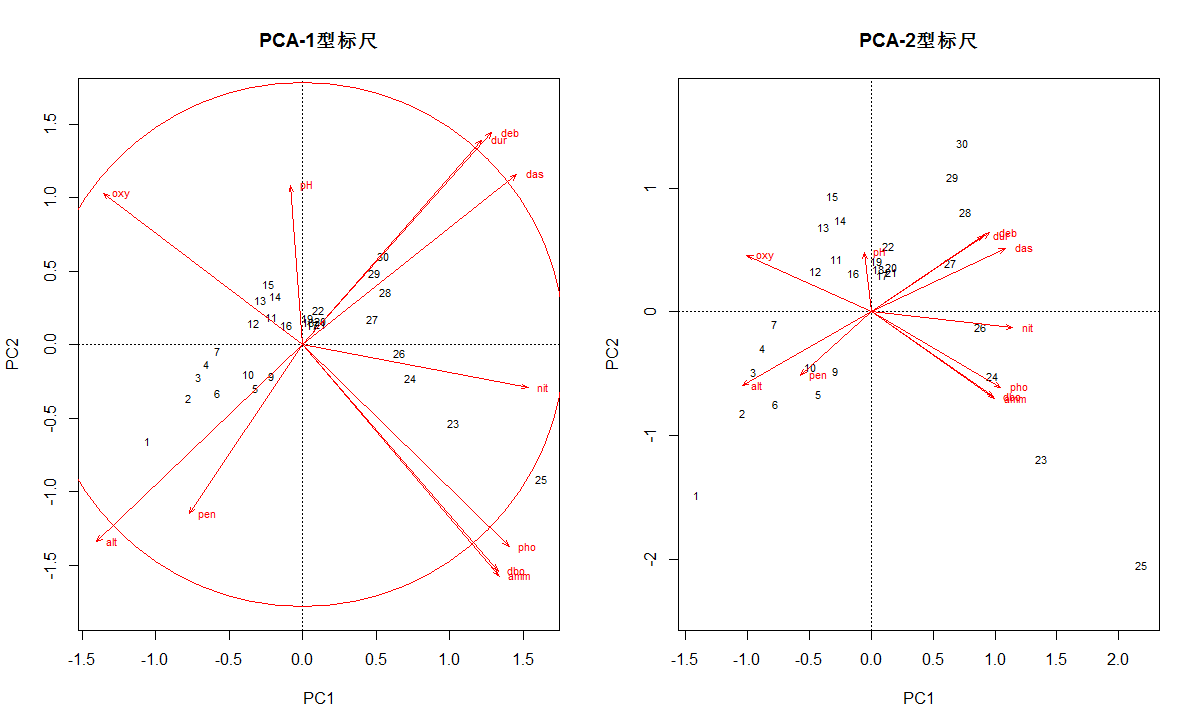
cleanplot.pca(env.pca, ahead=0)
# ahead=0表示变量用无箭头的线表示
#左图中圆圈代表什么意义?看下面解释内容
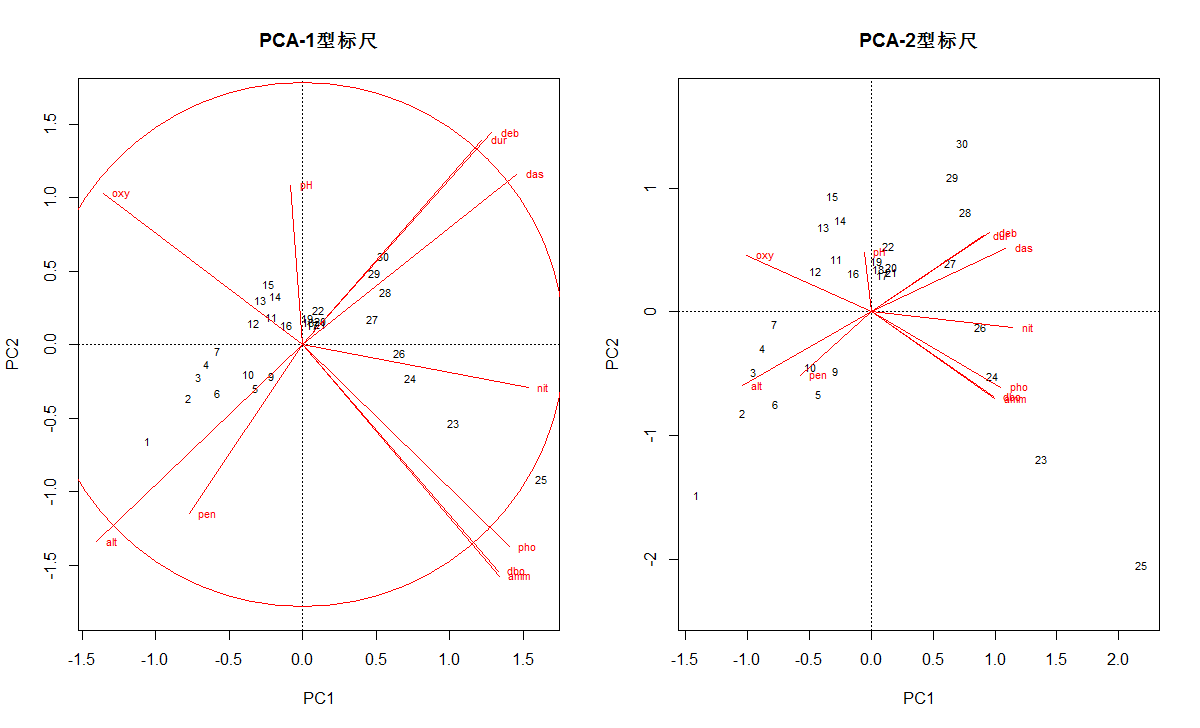
- 1型标尺双序图中的平衡贡献圆:
其半径代表变量的向量长度对排序的平均贡献率。因此在任何二维排序图中,如果某个变量的箭头长度长于圆的半径,代表他对这个排序空间的贡献大于所有变量的平均长度。
组合聚类结果和排序结果
- 在排序图内用不同颜色去区分不同样方组
- 将聚类树添加到排序图上
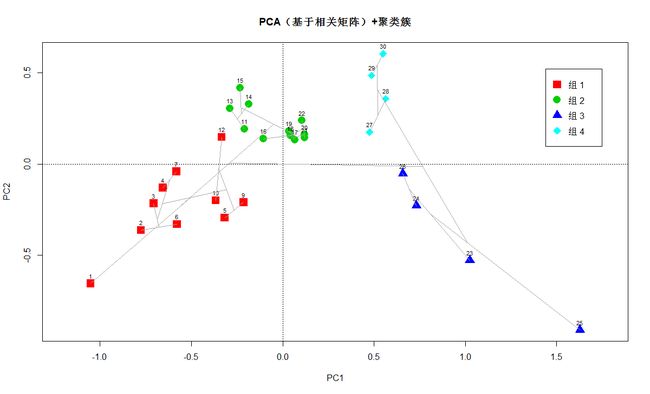
# 组合聚类分析结果和排序结果
# ***************************
# 使用环境变量数据对样方进行基于变量标准化后欧氏距离的Ward聚类分析
env.w <- hclust(dist(scale(env)), "ward")
# 裁剪聚类树,只保留4个聚类簇
gr <- cutree(env.w, k=4)
grl <- levels(factor(gr))
# 提取样方坐标,1型标尺
sit.sc1 <- scores(env.pca, display="wa", scaling=1)
# 按照聚类分析的结果对样方进行标识和标色(1型标尺)
p <- plot(env.pca, display="wa", scaling=1, type="n",
main="PCA(基于相关矩阵)+聚类簇")
abline(v=0, lty="dotted")
abline(h=0, lty="dotted")
for (i in 1:length(grl)) {
points(sit.sc1[gr==i,], pch=(14+i), cex=2, col=i+1)
}
text(sit.sc1, row.names(env), cex=.7, pos=3)
# 在排序图内添加聚类树
ordicluster(p, env.w, col="dark grey")
legend(locator(1), paste("组",c(1:length(grl))), pch=14+c(1:length(grl)),
col=1+c(1:length(grl)), pt.cex=2)
转化后的物种数据PCA分析
PCA是一种展示样方之间的欧氏距离的线性方法,理论上并不适用于物种多度分析。然而我们可以通过对数据进行转化来做PCA。
# 鱼类多度数据的PCA分析
# **********************
# 物种数据Hellinger转化
spe.h <- decostand(spe, "hellinger")
spe.h.pca <- rda(spe.h)
spe.h.pca
Call: rda(X = spe.h)
Inertia Rank
Total 0.5025
Unconstrained 0.5025 27
Inertia is variance
Eigenvalues for unconstrained axes:
PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8
0.25796 0.06424 0.04632 0.03850 0.02197 0.01675 0.01472 0.01156
(Showed only 8 of all 27 unconstrained eigenvalues)
#绘制每轴的特征根和方差百分比
ev <- spe.h.pca$CA$eig
evplot(ev)
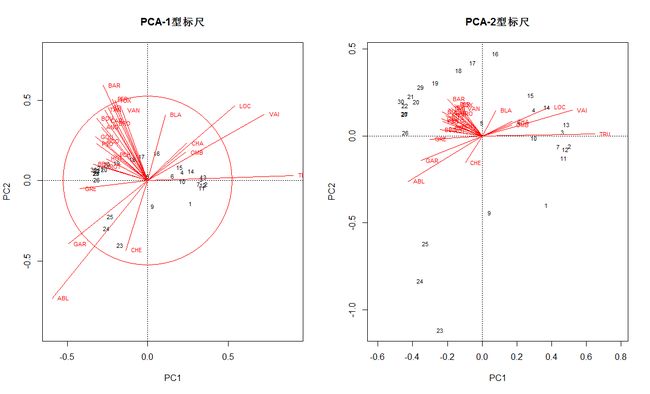
# PCA双序图
cleanplot.pca(spe.h.pca, ahead=0)
#这里物种不像环境变量那样能够明显分组。但也能看出物种沿着梯度更替
#分布。在1型标尺的双序图内,可以观察到有8个物种对于第一、二轴有很大
#贡献。可以比较一下,这些物种与4.10.3节聚类分析中聚类簇的指示种是否
#重合?
使用PCA函数进行PCA分析
# 使用PCA()和biplot.PCA()两个函数进行环境数据的PCA分析
# **********************************************************
source("PCA.R") #导入PCA.R脚本,此脚本必须在当前工作目录下或给路径
# PCA,这里默认是1型标尺双序图
env.PCA.PL1 <- PCA(env, stand=TRUE)
biplot.PCA(env.PCA.PL1)
abline(h=0, lty=3)
abline(v=0, lty=3)
# PCA,生成2型标尺双序图
env.PCA.PL2 <- PCA(env, stand=TRUE)
biplot.PCA(env.PCA.PL2 ,scaling=2)
abline(h=0, lty=3)
abline(v=0, lty=3)
#这里主成分轴正负方向是随机的,可能与vegan包输出的排序图成镜像关
#系。但没有关系,因为对象或变量之间的相对位置没有变化。
参考:
相应分析的R包ca和mca,cca,RDA的R实现整理
使用Vegan包进行生态学数据排序分析的学习(一)
原来你是这样的排序分析