最近肺炎的发展速度属实有点恐怖。刚知道python的pyecharts这个库,想到pyecharts可视化的特点,正好可以扒一下肺炎实时播报的官网也做个地图。
第一步扒取数据:发现一个大问题,各省的确诊人数网页源代码里竟然没有。百度才知道这是js渲染生产的,又是一顿查。找到一种方法。用selenium执行一遍网页渲染的过程就可以了,首先安装selenium。
pip install selenium
在引用库的时候还需要webdriver这个启动浏览器的东西,我用的是google,所以要下载chromedriver。先查找自己chrome的版本
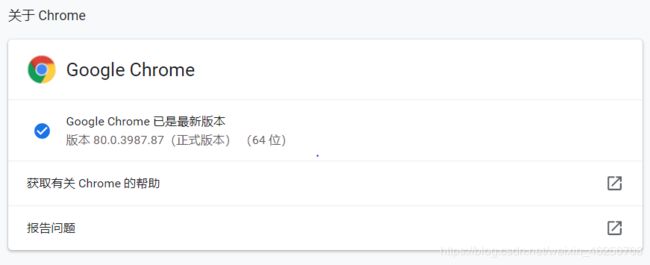
然后找到chromedriver的对应版本,下载
下载之后把exe文件解压到编代码的文件夹里就可以使用了。现在可以爬数据了,导入库
from selenium import webdriver
然后驱动浏览器,并访问网址
driver = webdriver.Chrome()
driver.get('https://news.163.com/special/epidemic/#map_block')
这里记住得设置一个等待,要不然爬取数据的时候可能程序运行完了网页还没打开
driver.implicitly_wait(5)
这时就可以获取数据了
data = driver.page_source
还是得用正则表达式筛选一下想要的数据,别忘了在前面导入import re
name = re.findall(r'(.*?)',data,re.S)[1:32]
value = re.findall(r'span class="item_confirm">(.*?)',data,re.S)[1:32]
爬取成功
![]()
已经爬取到数据了,接下来就是可视化的部分了,用到pyecharts的Map块。
pyecharts文档链接在这里——按照文档里把库导入

地图的代码如下
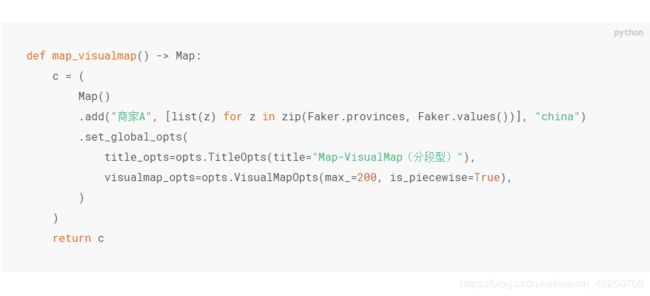
但是我Faker这个下不下来,后来查了一下用了这个大佬的方法:地址
整体代码如下:
from pyecharts.charts import Map
from pyecharts import options as opts
import re
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://news.163.com/special/epidemic/#map_block')
driver.implicitly_wait(5)
#data = driver.find_element_by_xpath('/html/body/div[3]/div[2]/div[2]/ul[1]/li[1]/div/span[1]').text#.get_attribute('href')
data = driver.page_source
attr = re.findall(r'(.*?)',data,re.S)[1:32]
value = re.findall(r'span class="item_confirm">(.*?)',data,re.S)[1:32]
sequence = list(zip(attr, value))
def map_visualmap(sequence, year) -> Map:
c = (
Map()
.add(year, sequence, "china", )
.set_global_opts(
title_opts=opts.TitleOpts(title="新冠装状病毒各省确诊人数"),
visualmap_opts=opts.VisualMapOpts(max_=130, min_=95),
)
)
return c
map = map_visualmap(sequence, '新冠病毒感染情况')
map.render(path='2020.html')
看一下成果吧!
以上就是脚本之家小编整理的全部内容,感谢大家的学习和支持。