最近和春晖、刘丁讨论定时器的问题,又仔细看了下 go timer 两个版本的实现,再结合 epoll 事件驱动,对比 Nginx, 实现方式如出一辙。只不过 go 的是无阻塞顺序编程,Nginx 异步回调。
高并发
老生常谈了,什么是“高并发编程”呢?核心只有两个,epoll 和 NonBlock. Nginx 和 go 实现方式太像了,go runtime 库所提供的接口都是无阻塞的,用 epoll 来实现事件驱动,效率非常高,后面的定时器就是典型案例。先举一个 openresty 的例子,这本书蛮不错,以后好好研究下:
location /sleep_1 {
default_type 'text/plain';
content_by_lua_block {
ngx.sleep(0.01)
ngx.say("ok")
}
}
location /sleep_2 {
default_type 'text/plain';
content_by_lua_block {
function sleep(n)
os.execute("sleep " .. n)
end
sleep(0.01)
ngx.say("ok")
}
}
上面的配置,很好理解,两个 location 都是 sleep(0.01) 秒操作,但是区别在哪呢?先看压测
➜ nginx git:(master) ab -c 10 -n 20 http://127.0.0.1/sleep_1
...
Requests per second: 860.33 [#/sec] (mean)
...
➜ nginx git:(master) ab -c 10 -n 20 http://127.0.0.1/sleep_2
...
Requests per second: 56.87 [#/sec] (mean)
...
性能差距 10 倍,原因就在于 sleep1 使用 openresty 提供的非阻塞 sleep 操作,执行的时候会导致协程切换,出让 cpu, 但是 sleep2 调用了系统函数,这是阻塞的,cpu 空转,openresty lua 开发的坑也很多。
阻塞 Block 是高并发的敌人,go 同理,很多人认为 goroutine 很历害,但是一遇到 cgo, 或是需要系统调用就会出问题,阻塞操作占用了大量的 m, 系统线程猛增,这时 gc 又会出来捣乱。借用 qyuhen 老师的一句话,每写一行代码,都得知道背后发生了什么。为了搞清楚 go 背后的原理,最近 春晖 在翻译 go-internal,有兴趣的可以看看,需要有汇编和 go runtime 知识。
无阻塞操作
平时使用最多的 Read, Write 操作,go 都做了无阻塞封装。Netpoll Accept 连接时,先设置成 SetNonBlock 模式,再使用 epoll et 边缘触发方式注册到 netpoll 中。对于 Read 操作,如果当前有数据,那么读出后返回。如果没有,那么调用 waitRead 将当前 goroutine 挂起,让出 process, 等待网络消息或是超时回调唤醒
// Read implements io.Reader.
func (fd *FD) Read(p []byte) (int, error) {
......
for {
n, err := syscall.Read(fd.Sysfd, p)
if err != nil {
n = 0
if err == syscall.EAGAIN && fd.pd.pollable() {
if err = fd.pd.waitRead(fd.isFile); err == nil {
continue
}
}
......
}
err = fd.eofError(n, err)
return n, err
}
}
waitRead 函数最终会调用 netpollblock 函数,并 gopark 在这里,runtime 释放当前 goroutine 所使用的 process
func netpollblock(pd *pollDesc, mode int32, waitio bool) bool {
gpp := &pd.rg
if mode == 'w' {
gpp = &pd.wg
}
......
if waitio || netpollcheckerr(pd, mode) == 0 {
gopark(netpollblockcommit, unsafe.Pointer(gpp), "IO wait", traceEvGoBlockNet, 5)
}
// be careful to not lose concurrent READY notification
old := atomic.Xchguintptr(gpp, 0)
if old > pdWait {
throw("runtime: corrupted polldesc")
}
return old == pdReady
}
那么 Read 函数是如何继续?goroutine 如何唤醒的呢?
- SetReadDeadline 超时到时,定时器唤醒
- Netpoll 收到了消息,触发epollin 消息唤醒
SetDeadline,每次对 conn 读写前设置,并且只对下一次读写生效。先来看一下 go 如何实现
//go:linkname poll_runtime_pollSetDeadline internal/poll.runtime_pollSetDeadline
func poll_runtime_pollSetDeadline(pd *pollDesc, d int64, mode int) {
......
pd.seq++ // invalidate current timers 用来检测当前定时任务是否过期
// Reset current timers. 删除老的任务
if pd.rt.f != nil {
deltimer(&pd.rt)
pd.rt.f = nil
}
if pd.wt.f != nil {
deltimer(&pd.wt)
pd.wt.f = nil
}
// Setup new timers.
if d != 0 && d <= nanotime() {
d = -1
}
if mode == 'r' || mode == 'r'+'w' {
pd.rd = d
}
if mode == 'w' || mode == 'r'+'w' {
pd.wd = d
}
if pd.rd > 0 && pd.rd == pd.wd {
pd.rt.f = netpollDeadline
pd.rt.when = pd.rd
// Copy current seq into the timer arg.
// Timer func will check the seq against current descriptor seq,
// if they differ the descriptor was reused or timers were reset.
pd.rt.arg = pd
pd.rt.seq = pd.seq
addtimer(&pd.rt)
} else {
if pd.rd > 0 {
pd.rt.f = netpollReadDeadline
pd.rt.when = pd.rd
pd.rt.arg = pd
pd.rt.seq = pd.seq
addtimer(&pd.rt)
}
if pd.wd > 0 {
pd.wt.f = netpollWriteDeadline
pd.wt.when = pd.wd
pd.wt.arg = pd
pd.wt.seq = pd.seq
addtimer(&pd.wt)
}
}
......
}
上面是 SetDeadline 核心部份代码,比较容易理解
- 生成 seq 号,这个序列号用来判断当前定时器是否过期
- 查看是否设置了 pd.rt.f 定时器回调函数,删除上一次的任务
- 设置定时时间
- 将读|写任务加入定时器,任务到期后回调函数 netpollDeadline
func netpolldeadlineimpl(pd *pollDesc, seq uintptr, read, write bool) {
lock(&pd.lock)
// Seq arg is seq when the timer was set.
// If it's stale, ignore the timer event.
if seq != pd.seq {
// The descriptor was reused or timers were reset.
unlock(&pd.lock)
return
}
var rg *g
if read {
if pd.rd <= 0 || pd.rt.f == nil {
throw("runtime: inconsistent read deadline")
}
pd.rd = -1
atomicstorep(unsafe.Pointer(&pd.rt.f), nil) // full memory barrier between store to rd and load of rg in netpollunblock
rg = netpollunblock(pd, 'r', false)
}
var wg *g
if write {
if pd.wd <= 0 || pd.wt.f == nil && !read {
throw("runtime: inconsistent write deadline")
}
pd.wd = -1
atomicstorep(unsafe.Pointer(&pd.wt.f), nil) // full memory barrier between store to wd and load of wg in netpollunblock
wg = netpollunblock(pd, 'w', false)
}
unlock(&pd.lock)
if rg != nil {
netpollgoready(rg, 0)
}
if wg != nil {
netpollgoready(wg, 0)
}
}
最终的定时任务到期,执行回调 netpollDeadline,执功能也很简单:
- 判断 seq 是否是最新的,对于长连接存在多次读写交互,正常情况网络 socket 不会超时,那么定时器触发后什么也不做
- 根据读|写事件,获取要唤醒的 goroutine
- netpollgoready 唤醒 goroutine, 所谓的唤醒只是标记成 可运行 状态,具体执行时间由 go runtime 决定
这是超时的情况,对于正常收到数据也很简单,findrunnable 调用 netpoll 获取收到事件的 goroutine, 标记成 runnable 可运行状态,具体执行时间由 go runtime 决定。代码参考 proc.go findrunnable 函数。
定时器
市面上流行的高效定时器有三种,go 使用的堆结构、linux kernel 使用的时间轮、nginx 红黑树。
go 在1.10前使用一个全局的四叉小顶堆结构,在面对大量连接时,定时器性能非常差,所以很多人实现了用户层的定时器库,很多公司还做过分享。但是 1.10 引入了 runtime 层的 64 个定时器,也就是 64 个四叉小顶堆定时器,性能提升不少。
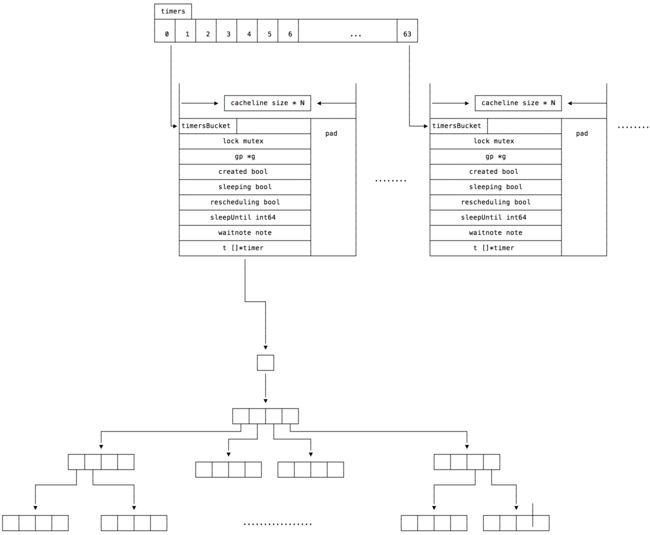
相比二叉,更遍平一些,增加删除都是 O(log4N) 级别,查询是O(1),但是为了维护堆结构也要额外操作 O(log4N)
时间轮有很多变种,内核使用了多级 time wheel, 没看过内核代码,举一个单轮的例子吧,图片来自csdn这篇文章
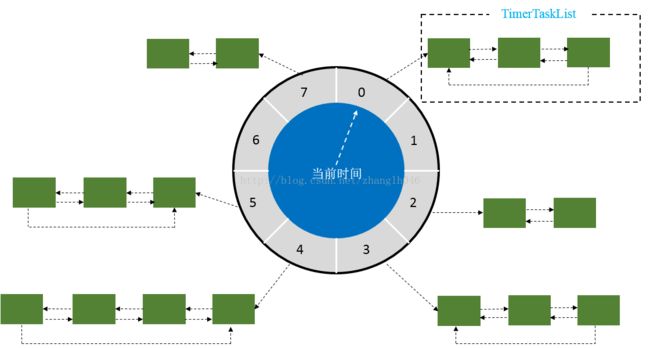
一个轮有 N 个刻度,每个刻度是一个 t 嘀嗒时间,假如 N = 60, t = 1s, 那么就是生活中的秒针。时间轮初始化 N 个槽,每个槽是一个链表,在某一时刻加入一个时间为 T 的超时事件,cycle = T / t, n = T % t, 其中 cycle 是轮数,n 代表当前事件插入 current 时刻后的第 n 个槽。当时间流逝,指针指向下一个时刻,遍历槽内链表,cycle - 1, 如果为 0 那么回调当前超时任务函数,否则继续检查下一个任务。插入删除超时任务时间复杂度 O(1),查询是 O(n),但由于己经分成多个槽,所以效率肯定好于 O(n),多级时间轮计算更复杂。
红黑树有两篇文章不错,nginx红黑树详解, nginx学习9-ngx_rbtree_t,整体感觉效率和小顶堆差不多。Nginx 使用红黑树做定时器,举一个最熟悉的场景,接收到连接后,如果长时间没收到 http header, 那么 Nginx 会关闭这个连接。
epoll 驱动
Nginx 启动 N 个 worker, 并将 worker 和 cpu 进行绑定,每个 worker 有自己的 epoll 和 定时器,由于没有进程、线程切换开销,性能非常好。最近在看 Nginx 也引入了线程池,用于处理文件并发处理的情况,不过线上并没有用。
Epoll 开发多注意触发模式,默认是 LT 即水平触发,只要有数据可读|写,epoll_wait 返回时就一直携带 FD。而大部分服务都使用 ET 边缘触发模式,即从无数据到有数据,从不可写到可写,状态变化才会触发 epoll, 如果一次没有读完,内核里还有待读数据,那么 epoll 是不会触发的。所以 ET 使用的正确姿势,抱住 FD,一直读|写,直到遇到 EAGAIN、EWOULDBLOCK 错误。
Nginx 在这里也做了优化,如果有大段数据要读取或是发送,他会分多次调用的,防止当前 worker 其它任务饿死。上周公司同事将 1.9G 文件写到一个 git, 恰巧这个工程是服务配置库,每次上线都要拉取配置库的压缩包,直接将 Nginx 压跨了。
小结
高并发的要点就是无阻塞 NonBlock, 看 openresty 文档,官方 lua 实现的都是无阻塞的,有时间读读。
前几天某个大牛又提起所谓的 tcp 粘包、拆包问题,明明就是用户协义解析问题,非要发明新名词。thrift protobuf 反序列化就是个好例子。