小概
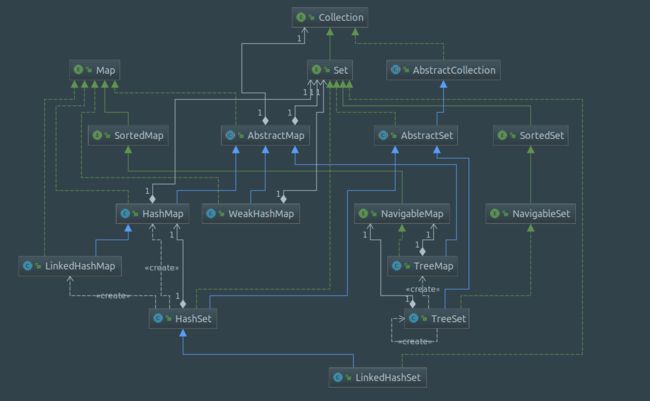
Map 主要定义以下行为规范
- put(key, value)
- get(key)
- keySet()
- values()
- entrySet()
通过往 Map 里放置一对一对 entry(键值对),查询时,我们可以通过 key 来快速找到 value,更可以一次性获取全部 key - keySet(),value - values() 或者 entry - entrySet()
在 Map 接口中,又定义 Entry 抽象概念,并将实现交给子类
/**
* A map entry (key-value pair). The Map.entrySet method returns
* a collection-view of the map, whose elements are of this class. The
* only way to obtain a reference to a map entry is from the
* iterator of this collection-view. These Map.Entry objects are
* valid only for the duration of the iteration; more formally,
* the behavior of a map entry is undefined if the backing map has been
* modified after the entry was returned by the iterator, except through
* the setValue operation on the map entry.
*
* @see Map#entrySet()
* @since 1.2
*/
interface Entry {
K getKey();
V getValue();
V setValue(V value);
boolean equals(Object o);
int hashCode();
}
Set 本身就代表集合,容器内元素唯一,完全继承自
Collection,只能通过 iterator 访问
SortedMap 和 SortedSet 需使用 Comparator 使 key 维持特定顺序,由此有序 key 将能够 定位首尾 和被 截取
- comparator()
- sub(K fromKey, K toKey)
- head(K toKey)
- tail(K fromKey)
- firstKey()
- lastKey()
NavigableMap 和 NavigableSet 具备 导航 功能,能够通过给定 key 定位邻居
- K lower(K k)
- K floor(K k)
- K ceiling(K k)
- K higher(K k)
HashMap
HashMap 作为 哈希表 [1],是使用最频繁的容器之一,总体特征如下
- 自扩容
- 数组构建槽
- 重哈希
- 链表、红黑树处理碰撞
- 插入元素无序
在其内部,维护一个 数组 作为整张哈希表的槽,对 Map 接口中 Entry 接口给出实现
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node[] table;
/**
* Holds cached entrySet(). Note that AbstractMap fields are used
* for keySet() and values().
*/
transient Set> entrySet;
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node implements Map.Entry {
final int hash;
final K key;
V value;
Node next;
// ...
}
映射与优化
我们现在考虑 余数法 来给入槽元素定位槽索引,Java 中可以利用对象的 hashCode() 方法,来很方便地设计映射函数
但计算机取余是一步很费性能的操作,HashMap 是如下简化的
当 n 为 2 的倍数 时,正好构成 低位掩码,(n - 1) 二进制i位以下全为 1, 以上全为 0,我们以 n = 16, key = 23 作如下例子

通过这个图例我们可以看出,这个操作就是取余,不仅简单,而且如此设计对后面还有帮助
根据上述映射方法,现在我们考虑如下情况,并讨论如何均匀映射
- 若设计成 bucketCapacity = 2^i,现在假设有一个数据序列,若它们低i位 全部相等,那么不管它们是什么数,都将映射入同一个槽产生很多碰撞
- key 对象封装者 hashCode() 写得不一定很有水平,映射得非常集中也不是没可能
因此 HashMap 很有必要对 key.hashCode() 进行 二次哈希,采取如下方式,key 对象 高半区和低半区做异或,混合原始哈希码的高位和低位,以此来加大低位的随机性,将二次哈希后的哈希值映射得非常均匀
/**
* Computes key.hashCode() and spreads (XORs) higher bits of hash
* to lower. Because the table uses power-of-two masking, sets of
* hashes that vary only in bits above the current mask will
* always collide. (Among known examples are sets of Float keys
* holding consecutive whole numbers in small tables.) So we
* apply a transform that spreads the impact of higher bits
* downward. There is a tradeoff between speed, utility, and
* quality of bit-spreading. Because many common sets of hashes
* are already reasonably distributed (so don't benefit from
* spreading), and because we use trees to handle large sets of
* collisions in bins, we just XOR some shifted bits in the
* cheapest possible way to reduce systematic lossage, as well as
* to incorporate impact of the highest bits that would otherwise
* never be used in index calculations because of table bounds.
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
值得注意的是,空键 将全被映射入 0 号槽
碰撞处理与优化
内接链表
内部封装类 Node 本身就是一种链表节点,也就是说
- 入槽:发现槽内已经有元素,那么顺着链表判断,直到检查到一个节点的 next 为 null,便在其 next 后接一个链表
- 搜索:找到映射槽,顺着链表用 equals 搜索
Treefy
不管映射得再均匀,扩容扩得再好,若是很多个元素仍然碰撞在同一个槽,我们会发现这个槽后面将接一串 非常长的链表,此时对元素的搜索代价将是十分惨痛的,因此当链表到达一定长度时,有理由替换成另一种数据结构,HashMap 中采用的是平衡搜索树的一种 - 红黑树 [2]
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
*/
static final int MIN_TREEIFY_CAPACITY = 64;
/**
* Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn
* extends Node) so can be used as extension of either regular or
* linked node.
*/
static final class TreeNode extends LinkedHashMap.Entry {
TreeNode parent; // red-black tree links
TreeNode left;
TreeNode right;
TreeNode prev; // needed to unlink next upon deletion
boolean red;
// ...
}
也就是说,当一个槽内如果有超过 8 根链表,会将该槽节点 树化,并用树根节点来替换,对树节点的操作与红黑树一致
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
扩容策略
就算映射得再均匀,bucketCapacity 太小也将会产生大量碰撞,因此扩容将变得十分有必要
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;
/**
* The next size value at which to resize (capacity * load factor).
*
* @serial
*/
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
int threshold;
考虑如下扩容算式
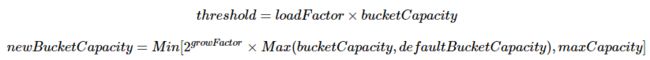
并如下扩容
if (bucketCapacity > threshold && bucket[bucketIndex] != null) {
newBucketCapacity = getNewCapacity();
}
在 HashMap 中,默认为 初始容量 16,扩容阈值因子 0.75,每次扩容 2 倍,最大容量 1 << 30
重哈希
但是,HashMap 每次扩容后,槽容量变为两倍,这也就意味着扩容前的映射全部失效,那么现在要考虑,将之前存储的元素 重新映射 到新槽中
现在 bucketCapacity = 2^i 又有了用武之地,我们考虑槽容量为 16,现在要为它扩容的情况

扩容两倍后

我们从图例中可以很明确的观察到,重哈希后,只需要关注第i+1位即可,所以重哈希有如下几种情况
- 无节点:不处理
- 单节点:要么还是在原位置,要么在原位置 +odlCapacity 位置
- 链表:遍历各个节点,每个节点的处理方式跟单节点一样
- 树:从树根节点开始处理
because we are using power-of-two expansion, the elements from each bin must either stay at same index, or move with a power of two offset in the new table.
LinkedHashMap
LinkedHashMap 具有以下特征
- 完全继承自 HashMap
- 内部维护一个 双端链表 记录插入顺序
- 迭代顺序与插入顺序有关
public class LinkedHashMap extends HashMap
implements Map {
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry tail;
/**
* HashMap.Node subclass for normal LinkedHashMap entries.
*/
static class Entry extends HashMap.Node {
Entry before, after;
// ...
}
}
为此 HashMap 中专门暴露出了几个方法,给子类 重写,并会在 non-tree Node 节点进行操作时 回调 这些方法
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node p) { }
对于 TreeNode 节点的操作,也全部被 LinkedHashMap 重写,节点改变时在双端链表中作出相应记录
TreeMap
TreeMap 具有以下特征
- 由 红黑树 支持搜索,key 顺序与其 Comparator 有关
- 迭代顺序和 key 顺序有关
public class TreeMap extends AbstractMap
implements NavigableMap, Cloneable, java.io.Serializable
{
/**
* The comparator used to maintain order in this tree map, or
* null if it uses the natural ordering of its keys.
*
* @serial
*/
private final Comparator comparator;
private transient Entry root;
/**
* Fields initialized to contain an instance of the entry set view
* the first time this view is requested. Views are stateless, so
* there's no reason to create more than one.
*/
private transient EntrySet entrySet;
private transient KeySet navigableKeySet;
private transient NavigableMap descendingMap;
/**
* Node in the Tree. Doubles as a means to pass key-value pairs back to
* user (see Map.Entry).
*/
static final class Entry implements Map.Entry {
K key;
V value;
Entry left;
Entry right;
Entry parent;
boolean color = BLACK;
}
// ...
}
其实只要理解了红黑树的实现原理,TreeMap 也不难,我们在这里就不细谈了
值得注意的是,与 Map 不同,NavigableMap 和 SortedMap 是有序的,具备对不同 key 之间的一些搜索功能,其中的截取功能和 ArrayList 中有点类似,获取的只是一份 引用地址,所以使用时需额外注意
/**
* This class exists solely for the sake of serialization
* compatibility with previous releases of TreeMap that did not
* support NavigableMap. It translates an old-version SubMap into
* a new-version AscendingSubMap. This class is never otherwise
* used.
*
* @serial include
*/
private class SubMap extends AbstractMap
implements SortedMap, java.io.Serializable {
private boolean fromStart = false, toEnd = false;
private K fromKey, toKey;
}
WeakHashMap
WeakHashMap 的 Entry 继承自 弱引用 WeakReference [3],并把 key 放入队列中,也就是说,每当 GC 时发现 key 只被弱引用所引用,那么它都会被回收,回收的对象被存储在内部维护的 ReferenceQueue 中
因此 WeakHashMap 具有以下特征
- 与 HashMap 实现大致相同
- GC 时会回收只被弱引用所引用的 key
值得注意的是,如果你存入 Integer 作为键,那么作为 缓存 的 -128 ~ 127 的 Entry 是永远不会被回收的,类似许多 String 也是一样,存在着许多你意想不到的比弱引用强的引用指向它
public class WeakHashMap extends AbstractMap
implements Map {
/**
* Reference queue for cleared WeakEntries
*/
private final ReferenceQueue 在这里不得不讨论一个事情,如果链中间的 key 消失了,链表由此 断开 ,我们将永远找不到链后的节点,所以必须将断开的两端重新接起来
在我们对该容器进行操作时,WeakHashMap 都会将节点与 ReferenceQueue 进行 同步
- 重链
- 清空 ReferenceQueue
回收节点时,消失的是 key,但是我们能从 ReferenceQueue 中拿到消失的 Entry,每个 Entry 都保留了 hash 值,我们通过这个值定位到消失的槽,顺着链表搜索该消失的节点,将消失的节点断开,并给两端 重新链接
但让我不太理解的时,同步时,作为非线程安全的 WeakHashMap 为什么要 加锁 ?
/**
* Expunges stale entries from the table.
*/
private void expungeStaleEntries() {
for (Object x; (x = queue.poll()) != null; ) {
synchronized (queue) {
// ...
}
}
}
Set
Jdk 中比较常用的有 HashSet,LinkedHashSet 和 TreeSet 其中的内部实现都调用了相对应的 Map,原理大致一样,这里我们就拿 HashSet 举例子
HashSet 具有以下特性
- 由 HashMap 实现
- 集合 元素去重
利用 HashMap 映射特性实现去重效果,Set 中的 元素被当作 key 插入 HashMap,然而 value 是什么并不关键,Jdk 中填入的是 Object,并且有一个全局常量 Object 对象 PRESENT,每次操作都与 PRESENT 相伴
private transient HashMap map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
可能造成的隐患
equals 和 hashCode
哈希容器在元素入槽和查询搜索时,都使用了这两种方法 [4],如果我们填入的 key 对象未实现这两种方法,或者实现不正确,将可能会导致 容器效率低下 甚至 数据不正确
因此,我们应该非常小心地处理 key 对象
内存泄露隐患
假设我们有一个哈希容器 Map,我们在某个时刻给这个容器加入一对键值对,暂且将 key 记为 k,然后在另一个时刻,我们又 改变 了 k 的某一个属性,这个属性又非常幸运地 和 hashCode 计算有关联
如果我们的操作是下面这种情况,那将是相当危险的
- 我需要靠这个 k 来找到我当时存的值,并且这个 k 是唯一的我无法再还原,由于 k 的 hashCode 已经改变,我将 永远找不到我当时存入的值
- 像上面所说,我通过这个 k 去找我当时存入的值,发现容器中并没有,那我又创建一个值,和 k 作为键值对存进去
- 恰巧我的这个 Map 是一个 全局量,并且永远不 clear(),那么 GC 永远不会回收这个 Map,由于那些错误的键值对的引用还在 Map 中,也就意味着 堆里的内存永远不会被释放
HashMap 扩容死链
非并发容器在多线程条件下是线程不安全的,但是 HashMap 不仅不安全,在扩容时还有一定几率发生 死循环,让你虚拟机趋近死亡,对为何会造成死链感兴趣可以参考这篇文章 并发的HashMap为什么会引起死循环?
如果需要支持多线程环境,千万不要用 HashMap,建议使用分段锁 ConcurrentHashMap 或者 Collections.synchronizedMap(Map) 将 Map 转化为 Collections 内部实现支持并发的 SynchronizedMap
参考
1. Jdk 源码 1.8
2. Jdk 官方文档
3.《深入理解 Java 虚拟机》
4. JDK 源码中 HashMap 的 hash 方法原理是什么?
-
几分钟理解 数据结构 - 哈希表及其优化 ↩
-
详解TreeMap 的红黑树实现 ↩
-
几分钟理解 Jdk - 引用 ↩
-
几分钟理解 Jdk - ==,hashCode 与 equals ↩