0、https://jsoneditoronline.org/
0.5、命令行装包:
(sudo) python3 -m pip install +包名称
pip --default-timeout=100 install -U +包名
1、program = os.path.basename(sys.argv[0]) ——当前py文件的名字
2、return len(result)!=len(set(result)) ——判断result里是否有重复的元素,有返回True,没有返回False
3、Python 16进制转10进制:
字符串转整数:
10进制字符串: int('10') ==> 10
16进制字符串: int('10', 16) ==> 16
16进制字符串: int('0x10', 16) ==> 16
整数之间的进制转换:
10进制转16进制: hex(16) ==> 0x10
16进制转10进制: int('0x10', 16) ==> 16
类似的还有oct(), bin()
4、list的for循环,是按顺序从头遍历的。下例加一个break就能找到value的上限了:
values_limits = [19, 49, 99, 299, 999] #--从小到大按顺序排,于是for循环遍历是也会从19-》999,只要小于就break,就能找到所在区间。
value =298
desc_data = {}
desc_data['key'] = guide_key_list[0]
if value ==0:
desc_data['val'] ='本区县暂无数据,敬请期待'
elif value > values_limits[-1]:
desc_data['val'] = map_color_level[-1]['deta']
else:
for i in range(len(values_limits)):
if value <= values_limits[i]:
desc_data['val'] = map_color_level[i]['deta']
break
5、os.path:
python中的os.path模块用法:
dirname() 用于去掉文件名,返回目录所在的路径
如:
>>> import os
>>> os.path.dirname('d:\\library\\book.txt')'d:\\library'
basename() 用于去掉目录的路径,只返回文件名
如:
>>> import os
>>> os.path.basename('d:\\library\\book.txt')'book.txt'
join() 用于将分离的各部分组合成一个路径名
如:
>>> import os
>>> os.path.join('d:\\library','book.txt')'d:\\library\\book.txt'
split() 用于返回目录路径和文件名的元组
如:
>>> import os
>>> os.path.split('d:\\library\\book.txt')('d:\\library', 'book.txt')
splitdrive() 用于返回盘符和路径字符元组
>>> import os
>>> os.path.splitdrive('d:\\library\\book.txt')('d:', '\\library\\book.txt')
splitext() 用于返回文件名和扩展名元组
如:
>>> os.path.splitext('d:\\library\\book.txt')('d:\\library\\book', '.txt')
>>> os.path.splitext('book.txt')('book', '.txt')
6、显示当前目录下的所有文件和文件夹:
用python实现:
import os
path = os.listdir(os.getcwd())
print (path)
或者这样写也一样:
import os
path = os.listdir('.')
print (path)
如果只输出当前文件夹下的所有文件夹:
import os
path = os.listdir(os.getcwd())
#print (path)
for p in path:
if os.path.isdir(p): #判断是否为文件夹,如果是输出所有文件就改成: os.path.isfile(p)
print(p)
7.
f.read() 每次读取整个文件,它通常用于将文件内容放到一个字符串变量中。
.readline() 和 .readlines() 非常相似。它们都在类似于以下的结构中使用:
file = open('c:\\autoexec.bat')
for line in file.readlines(): // 或者直接 for line in file:
print(line)
.readline() 和 .readlines() 之间的差异是后者一次读取整个文件,象 .read() 一样。
.readlines() 自动将文件内容分析成一个行的列表,该列表可以由 Python 的 for ... in ... 结构进行处理。
.readline() 每次只读取一行,通常比 .readlines() 慢得多,仅当没有足够内存可以一次读取整个文件时,才应该使用 .readline()。
8.筛掉csv中的空值:
datas = train_data.loc[row].values[1]
if isinstance(datas,str) or not math.isnan(datas):
9. word in word_dict 等价于 word in word_dict.keys()
10. pycharm代码格式化
ctrl+alt+L可以格式化,但是和锁屏快捷键冲突。
也可以,选中代码,使用快捷键 ctrl+alt+i
自己在开发的过程中代码太长了,看起来非常不方便
设置代码块的自动换行如下:
View--->Active Editor--->Use Soft Wraps
11. 加一发excel快速填充方法:
有三种快速方法:
方法一:在第一个单元格右下角双击;
方法二:按住第一个单元格右下角的黑色十字往下拖
方法三:Ctrl+D快捷键填充
具体如下:
方法一:把鼠标放到公式所在单元格右下角,当鼠标变成黑色十字时,双击就全部填充了,但这种方法要求你复制列的前一列不能断行,如:你在B列需要往下快速复制公式,总共100行,但是A列的第51行为空,用这种方法就只能复制公式到第50行,后面的需要你再操作一次。
方法二:把鼠标放到公式所在单元格的右下角,当鼠标变成黑色十字时,按住鼠标左键往下拖就可以了,想复制多少行都可以,没限制,但是效率较方法一低很多。
方法三:假设你的公式在B2单元格,需要复制公式到B3:B999,那么你先选择包含公式单元格的所有需要复制公式的单元格(B2:B999),然后按Ctrl+D即可全部填充,这种方法有方法一的高效性,又有方法二的通用性。很实用。
12、print('\r进度:%.2f%%'%percent, end="") ——每次输出都只出现在第一行,一直闪现
13、json串的合并:
1)合并成list形式:
json.dump([json.load(open(src_path+'part1.json', 'r', encoding='utf-8')),
json.load(open(src_path+'part2.json', 'r', encoding='utf-8'))], open(trg_path, 'w', encoding='utf-8'))
2)合并成dict形式:
datas = json.load(open(src_path+'part1.json', 'r', encoding='utf-8'))
datas.update(json.load(open(src_path +'part2.json', 'r', encoding='utf-8')))
json.dump(datas, open(trg_path, 'w', encoding='utf-8'))
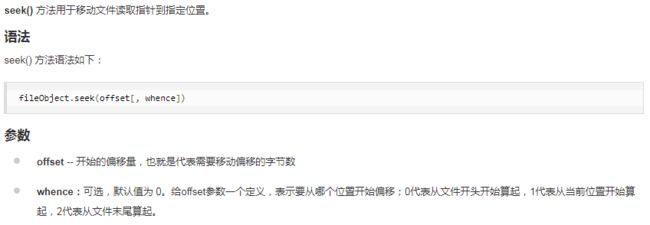
14、文件流
file.seek()方法标准格式是:seek(offset,whence=0)
offset:开始偏移量,也就是代表需要移动偏移的字节数。
whence:给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。
代码:
f= open('111.py','rb')
print(f.tell()) #0
f.seek(3) #默认为零,从文件开头
print(f.tell()) #3
f.seek(4,1) #1为从当前位置,移动4个字节
print(f.tell()) #7
f.seek(-4,2) #从文件末尾算,移动4个字节
print(f.tell()) #15
#f.tell()方法告知游标的位置
15、eval —— 把list/dict字符串转为list/dict
16、time.time() -- 返回的是一个浮点数,单位为秒
time.strftime("%Y-%m-%d %H:%M:%S") --直接返回当前时间, tuple
17、进度条: —— 记得加end=''!!!
print('\r进度:%.2f%% 运行时间:%.2f秒 剩余时间:%.2f秒' % ((count *100 / n), (time1 - time0), ((time1 - time0) * (n - count) / count)), end='') //写在for循环里面, end=''表示末尾不换行,加空字符串
print('\n加载完毕') //写在for循环外面
如果想把每次的内容输出的话:print('\r'+str(res_dict)+' 进度:%.2f%% 运行时间:%.2f秒 剩余时间:%.2f秒' % ((count *100 / n), (time1 - time0), ((time1 - time0) * (n - count) / count)), end='')
18、calendar
calendar.monthrange(year, month)
返回指定年和月的第一天是星期几,这个月总共有多少天。
例子:
#python 3.4
import calendar
print(calendar.monthrange(2015, 11))
结果输出如下:
(6, 30)
19、获取脚本名字:script_name = sys.argv[0].split('.')[0] (去掉.py)
20、记录异常
①把打印信息(异常信息)记录到log文件:
import sys
# make a copy of original stdout route
stdout_backup = sys.stdout
# define the log file that receives your log info
log_file =open("message.log", "a")
# redirect print output to log file
sys.stdout = log_file
print("Now all print info will be written to message.log")
# any command line that you will execute
...
log_file.close()
# restore the output to initial pattern
sys.stdout = stdout_backup
print("Now this will be presented on screen")
② 用traceback功能
if weibo_infos ==0:
script_name = sys.argv[0].split('.')[0]
f=open('%s_traceback_info.txt'%script_name, 'a', encoding='utf-8')
f.write(str(time.strftime("%Y-%m-%d %H:%M:%S"))+" gov_id=%d" % gov_id+'\n')
traceback.print_exc(file=f)
f.write('\n')
f.close()
return 0, 0
③logging??? —— 还不会,有机会研究一下
21、Python之list对应元素求和:
方法一:
利用numpy模块求解
importnumpy as np
a =np.array([1,2,3])
b =np.array([2,3,4])
c =np.array([3,4,5])
print(a+b+c)
需要注意的是,a+b+c后的类型为numpy.ndarray.
方法二:
利用numpy模块的sum()函数进行求解。
importnumpy as np
a =[1,2,3]
b =[2,3,4]
c =[3,4,5]
print(np.sum([a,b,c], axis =0))
其中的axis参数表示纵向求和。
22、locals() & globals() & attrs ???
>>>def runoob(arg): # 两个局部变量:arg、z
... z = 1
... print (locals())...
>>> runoob(4)
{'z': 1, 'arg': 4} # 返回一个名字/值对的字典
23、FTP匿名登录(ue)记得设置——user:anonymous;pwd:12345
24、set()去重后保持原list的顺序:
mailto = ['cc', 'bbbb', 'afa', 'sss', 'bbbb', 'cc', 'shafa']
addr_to = list(set(mailto))
addr_to.sort(key = mailto.index)
25、shutil.rmtree("E:\\test\\b")
可以发现b文件夹连同下面的文件都消失了。
26、for循环 迭代器
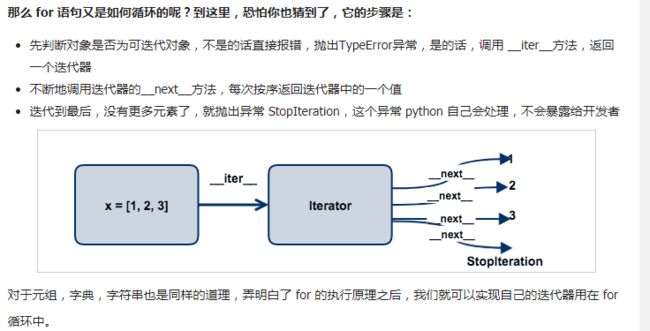
27、判断变量类型:isinstance(a,tuple) —— 判断变量a是否为元组类型
28、一句话迭代取值:
rows = [{'a': 1, 'b': 2, 'c': 0}, {'a': 2, 'b': 3, 'c': 0}]
写法一:[i['a'] for i in rows if i['b'] == 3] √
写法二:[i['a'] if i['b'] == 3 for i in rows] × —— for前面必须要有else !!!
神奇之处在于,if的位置不一样,值的取法要求也不一样~~~
29、

30、
31、Logging 多模块共用: —— Python代码的方式试过了,配置文件的方式之后了解一下。

32、sorted: —— 排序
points =sorted(points, key=lambda x:x[0], reverse=True)
33、Python自动打开网页

34、Python 模拟点击网页 / 清缓存 / 操作浏览器
https://blog.csdn.net/weixin_42551465/article/details/80817552
https://blog.csdn.net/zwq912318834/article/details/79215400?utm_source=blogxgwz8
https://blog.csdn.net/chengxuyuanyonghu/article/details/79154468
35、logging处理流程:【注意filter和setLevel的区别】
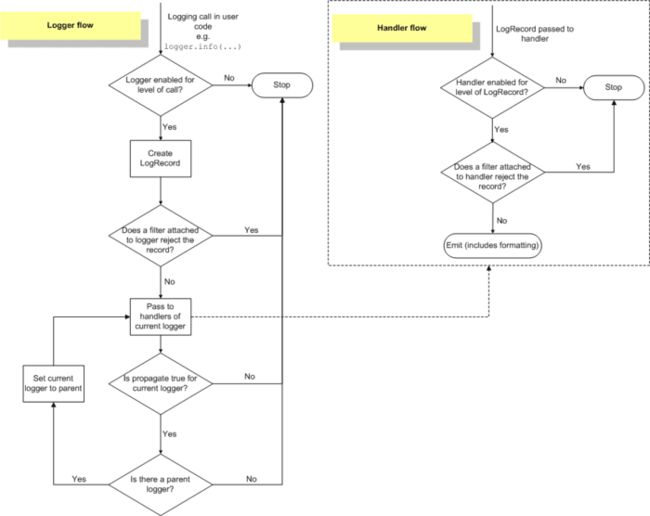
Filters can be used by Handlers and Loggers for
more sophisticated filtering than
is provided by levels. The base filter class only allows events which are
below a certain point in the logger hierarchy
. For example, a filter initialized with ‘A.B’ will allow events logged by loggers ‘A.B’, ‘A.B.C’, ‘A.B.C.D’, ‘A.B.D’ etc. but not ‘A.BB’, ‘B.A.B’ etc. If initialized with the empty string, all events are passed.
class logging.Filter(name='')
Returns an instance of the Filter class. If name is specified, it names
a logger which, together with its children, will have its events allowed through the filter
. If name is the empty string, allows every event.
filter(record)
Is the specified record to be logged? Returns zero for no, nonzero for yes. If deemed appropriate, the record may be modified in-place by this method.
Note that filters attached to handlers are consulted before an event is emitted by the handler, whereas filters attached to loggers are consulted whenever an event is logged (using debug(), info(), etc.), before sending an event to handlers. This means that events which have been generated by descendant loggers will not be filtered by a logger’s filter setting, unless the filter has also been applied to those descendant loggers.
You don’t actually need to subclass Filter: you can pass any instance which has a filter method with the same semantics.
Although filters are used primarily to filter records based on more sophisticated criteria than levels, they get to see every record which is processed by the handler or logger they’re attached to: this can be useful if you want to do things like counting how many records were processed by a particular logger or handler, or adding, changing or removing attributes in the LogRecord being processed. Obviously changing the LogRecord needs to be done with some care, but it does allow the injection of contextual information into logs
36、【logger的基本用法】:

37、dict按照values排序:
sorted(d.items(),key=lambda x:x[1])
38、求list中出现次数最多的元素:
a = [1,4,2,3,2,3,4,2]
from collections import Counter
print(Counter(a).most_common(1))
输出:[(2, 3)] —— 表示2出现了3次
39、numpy中有一些常用的用来产生随机数的函数,randn()和rand()就属于这其中。
numpy.random.randn(d0, d1, …, dn)是从标准正态分布中返回一个或多个样本值。
numpy.random.rand(d0, d1, …, dn)的随机样本位于[0, 1)中。

40、获取当前的函数名

41、通过函数名(字符串)来调用函数:https://blog.csdn.net/mrqingyu/article/details/84403924
【四种方法】:
法一:eval()

法二:locals()和globals()
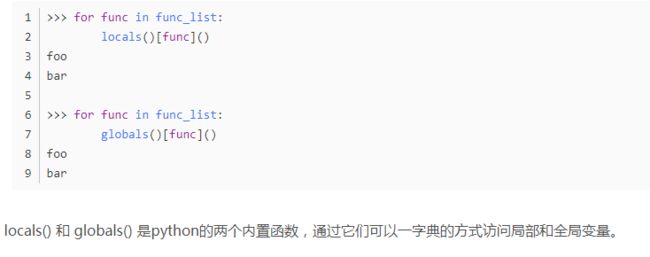
法三:getattr()

法四:标准库operator下的methodcaller函数

42、获取当前运行的函数名:http://www.cnblogs.com/paranoia/p/6196859.html
43、合并两个dict
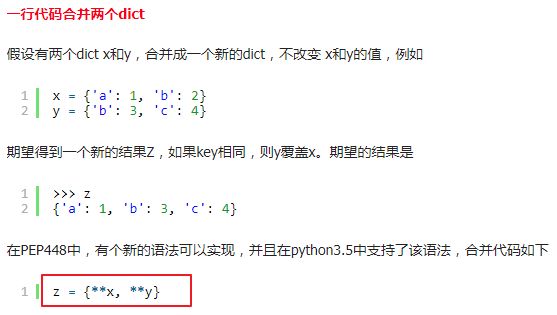
注:后面的dict会覆盖前一个dict中重复的键值
44、python .format() :它通过{}和:来代替传统%方式:https://www.cnblogs.com/benric/p/4965224.html
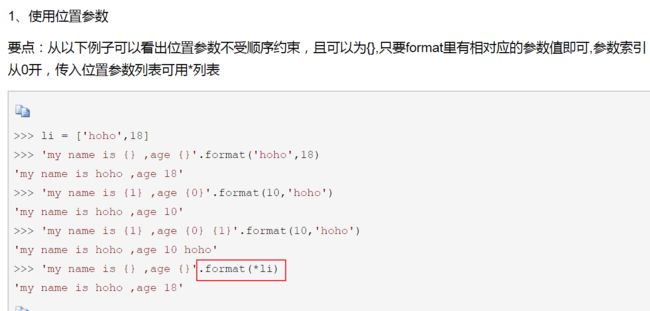
可以不用指定 %d 还是 %f 之类的
45、re.escape(pattern)
转义 pattern 中的特殊字符。如果你想对任意可能包含正则表达式元字符的文本字符串进行匹配,它就是有用的。