摘要:
1.RDD的五大属性
1.1 partitions(分区)
1.2 partitioner(分区方法)
1.3 dependencies(依赖关系)
1.4 compute(获取分区迭代列表)
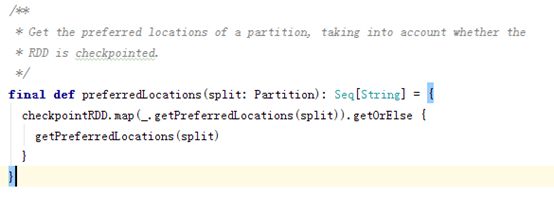
1.5 preferedLocations(优先分配节点列表)
2.RDD实现类举例
2.1 MapPartitionsRDD
2.2 ShuffledRDD
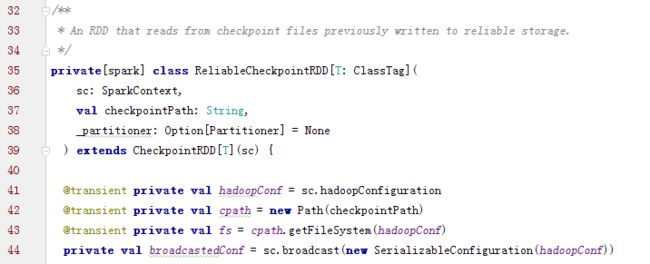
2.3 ReliableCheckpointRDD
3.RDD可以嵌套吗?
内容:
1.RDD的五大属性
1.1partitions(分区)
partitions : 分区属性: 每个RDD包括多个分区, 这既是RDD的数据单位, 也是计算粒度, 每个分区是由一个Task线程处理. 在RDD创建的时候可以指定分区的个数, 如果没有指定, 那么默认分区个数由参数spark.default.parallelism指定(如果未设置这个参数 ,则在yarn或者standalone模式下有如下推导:spark.default.parallelism = max(所有executor使用的core总数, 2)).
每一分区对应一个内存block, 由BlockManager分配.

子类可以通过调用下面的方法来获取分区列表,当处于检查点时,分区信息会被重写
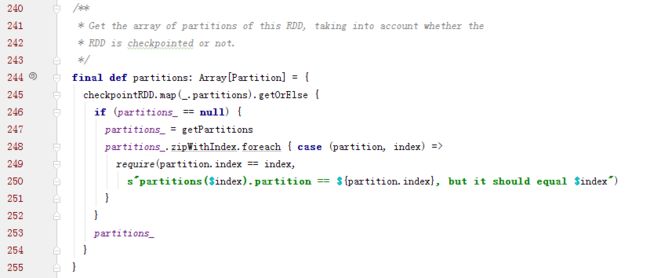
Partition实现:

partition ****与 iterator 方法
RDD 的 iterator(split: Partition, context: TaskContext): Iterator[T] 方法用来获取 split 指定的 Partition 对应的数据的迭代器,有了这个迭代器就能一条一条取出数据来按 compute chain 来执行一个个transform 操作。iterator 的实现如下:

其先判断 RDD 的 storageLevel 是否为 NONE,若不是,则尝试从缓存中读取,读取不到则通过计算来获取该Partition对应的数据的迭代器;若是,尝试从 checkpoint 中获取 Partition 对应数据的迭代器,若 checkpoint 不存在则通过计算(compute属性)
1.2partitioner(分区方法)
RDD的分区方式, 这个属性指的是RDD的partitioner函数(分片函数), 分区函数就是将数据分配到指定的分区, 这个目前实现了HashPartitioner和RangePartitioner, 只有key-value的RDD才会有分片函数, 否则为none. 分片函数不仅决定了当前分片的个数, 同时决定parent shuffle RDD的输出的分区个数.

HashPartitioner如何决定一个键对应的分区的:

其中nonNegativeMod方法考虑到了key的符号,如果key是负数,就返回key%numPartitions +numPartitions(补数);
HashPartitioner是基于Object的hashcode来分区的,所以不应该对集合类型进行哈希分区
RangePartitioner如何决定一个键对应的分区的:
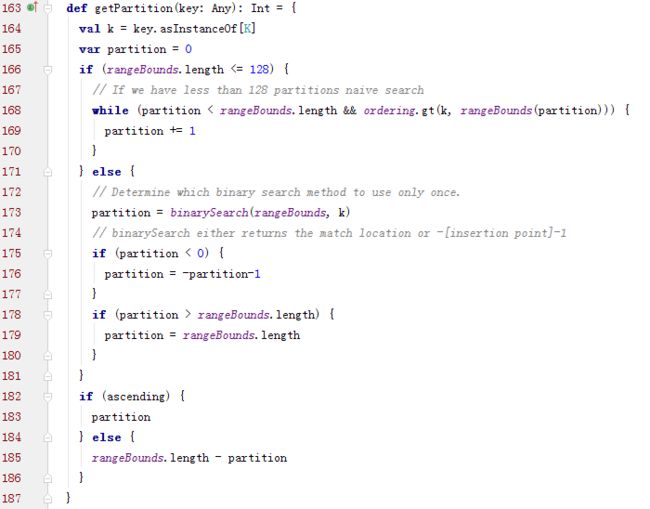
其中rangeBounds是各个分区的上边界的Array。而rangeBounds的具体计算是通过抽样进行估计的,具体代码可以参照RangePartitioner 实现简记
RangePartitioner是根据key值大小进行分区的,所以支持RDD的排序类算子
1.3dependencies(依赖关系)
Spark的运行过程就是RDD之间的转换, 因此, 必须记录RDD之间的生成关系(新RDD是由哪个或哪几个父RDD生成), 这就是所谓的依赖关系, 这样既有助于阶段和任务的划分, 也有助于在某个分区出错的时候, 只需要重新计算与当前出错的分区有关的分区,而不需要计算所有的分区.
dependencies_是一个记录Dependency关系的序列(Seq):
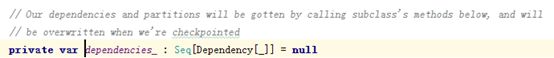
RDD是如何记录依赖关系的:
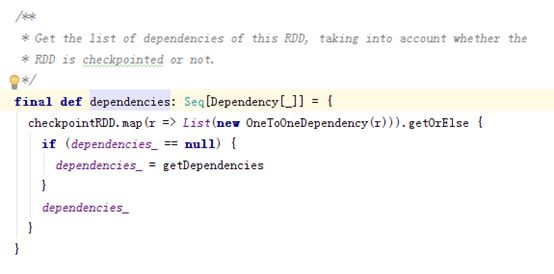
、
依赖类型:
-
- 窄依赖:父 RDD 的 partition 至多被一个子 RDD partition 依赖(OneToOneDependency,RangeDependency)
- 宽依赖:父 RDD 的 partition 被多个子 RDD partitions 依赖(ShuffleDependency)
图示:
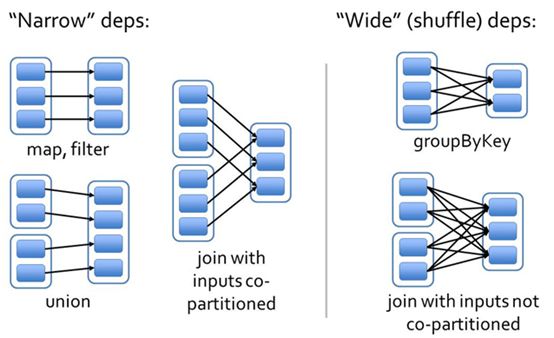
窄依赖是一对一的关系,所以可以直接从父分区中获取;宽依赖则不行。以下是宽依赖(实现是ShuffleDependency)的几个重要属性。更加具体的shuffle原理可以查看Spark Shuffle原理、Shuffle操作问题解决和参数调优

1.4compute(获取分区迭代列表)
计算属性: 当调用 RDD#iterator 方法无法从缓存或 checkpoint 中获取指定 partition 的迭代器时,就需要调用 compute 方法来获取
RDD不仅包含有数据, 还有在数据上的计算, 每个RDD以分区为计算粒度, 每个RDD会实现compute函数, compute函数会和迭代器(RDD之间转换的迭代器)进行复合, 这样就不需要保存每次compute运行的结果.
代码:

下面举几个算子操作:
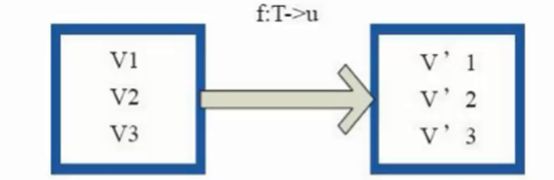
map
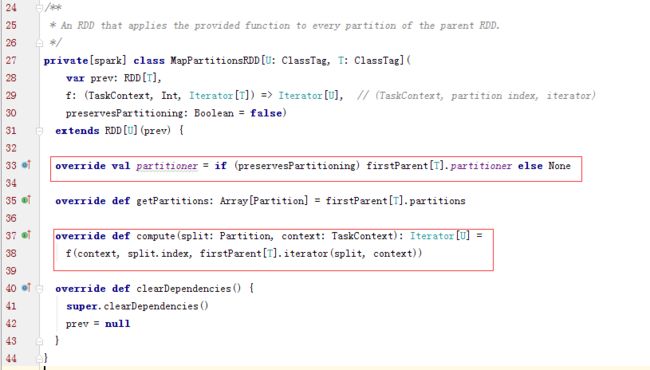

上面代码中的 firstParent 是指本 RDD 的依赖 dependencies: Seq[Dependency[_]] 中的第一个,MapPartitionsRDD 的依赖中只有一个父 RDD。而 MapPartitionsRDD 的 partition 与其唯一的父 RDD partition 是一一对应的,所以其 compute 方法可以描述为:对父 RDD partition 中的每一个元素执行传入 map (代码中的f(context,split.index,iterator)函数)的方法得到自身的 partition 及迭代器
图示:
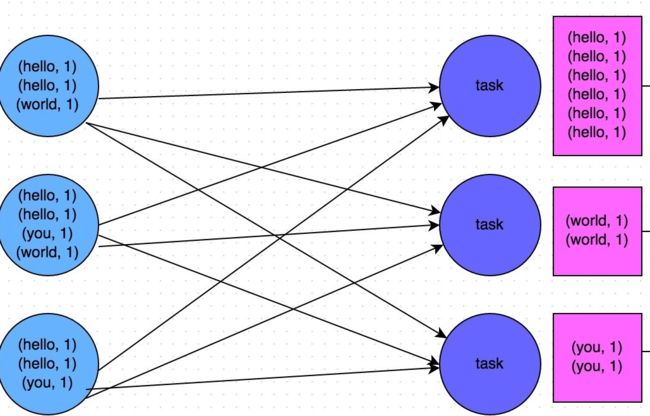
groupByKey
与 map、union 不同,groupByKey 是一个会产生宽依赖(ShuffleDependency)的 transform,其最终生成的 RDD 是 ShuffledRDD,来看看其 compute 实现:

可以看到,ShuffledRDD 的 compute 使用 ShuffleManager 来获取一个 reader,该 reader 将从本地或远程 BlockManager 拉取 map output 的 file 数据
图示:
1.5preferedLocations(优先分配节点列表)
对于分区而言返回数据本地化计算的节点列表
也就是说, 每个RDD会报出一个列表(Seq), 而这个列表保存着分片优先分配给哪个Worker节点计算, spark坚持移动计算而非移动数据的原则. 也就是尽量在存储数据的节点上进行计算.
要注意的是,并不是每个 RDD 都有 preferedLocation,比如从 Scala 集合中创建的 RDD 就没有,而从 HDFS 读取的 RDD 就有
spark 本地化级别:PROCESS_LOCAL => NODE_LOCAL => NO_PREF => RACK_LOCAL => ANY
PROCESS_LOCAL 进程本地化:task要计算的数据在同一个Executor中
**NODE_LOCAL **节点本地化:速度比 PROCESS_LOCAL 稍慢,因为数据需要在不同进程之间传递或从文件中读取
**NODE_PREF **没有最佳位置这一说,数据从哪里访问都一样快,不需要位置优先。比如说SparkSQL读取MySql中的数据
RACK_LOCAL 机架本地化,数据在同一机架的不同节点上。需要通过网络传输数据及文件 IO,比 NODE_LOCAL 慢
ANY 跨机架,数据在非同一机架的网络上,速度最慢
参考自:Spark数据本地化-->如何达到性能调优的目的
2.RDD实现类举例
2.1 MapPartitionsRDD
2.2 ShuffledRDD
2.3 ReliableCheckpointRDD
ReliableCheckpointRDD将RDD写入到HDFS中
checkpointRDD的功能就是切断所有的之前RDD的依赖和迭代关系,所以compute方法只返回对应HDFS的文件反序列化流的一个迭代器就可以了
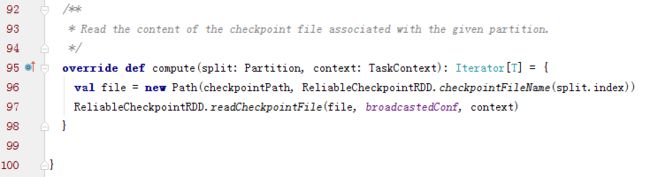
而且在ReliableCheckpointRDD中dependencies_属性是空的,也就没有实现getDependencies
另外多研究下RDD中的checkpoint方法:private def checkpointRDD: Option[CheckpointRDD[T]] = checkpointData.flatMap(_.checkpointRDD)
2.4 CoGroupedRDD (待补充)
3.RDD可以嵌套吗?
RDD嵌套是不被支持的,也即不能在一个RDD操作的内部再使用RDD。
在spark中trasaction是不能嵌套的,这是因为并行式函数将以闭包的形式发送至各个worker。若并行式函数使用了rdd的引用,spark将会把当前rdd对象闭包给worker.然而,对rdd对象的执行只能由driver进行,worker并不能执行,所以会导致错误。
标签: spark, RDD