【论文笔记系列】AutoML:A Survey of State-of-the-art (上)

上一篇文章介绍了Data preparation,Feature Engineering,Model Selection,这篇文章会继续介绍后面的内容。
4. Model Generation
4.2 Hyperparameters optimization
4.2.1 Grid&Random Search
下图很直观地展示了网格搜索(grid search)和随机搜索(random search)的区别,可以看到参数可以分为重要参数(蓝色区域)和非重要参数(黄色区域),同样是9次试验,随机搜索能测试更多种重要参数。

为了解决网格搜索的缺点,Hsu【1】等人提出我们可以先用比较粗犷的grid来搜索出一个表现较好的区域,然后在这个区域继续用细腻度的网格搜索,这样提高搜索效率。 Hesterman等人【2】提出contracting-grid search算法,大概的思路就是先计算出网格里每个店的似然估计值,然后我们在以最大值的点为中心生成一个新的网格,新网格中每个点之间的间距是之前网格的一半,然后重复上述步骤直到收敛。
当然随机搜索也有人提出改进算法,其中比较经典的就是Hyperband【3】,这个算法主要贡献是在计算资源和表现结果之间做了权衡,因为我们知道你搜索的时间越长,当然越有可能找到最佳的参数,但是这不现实,因为时间和计算资源有限,具体的细节可以阅读这篇文章机器学习超参数优化算法-Hyperband。还有人进一步提出了BOHB,即把贝叶斯和hyperband做了结合,这里不做展开。
4.2.2 进化算法
进化算法的步骤如下图示(涉及到的细节比较多,感兴趣的可以看看论文):
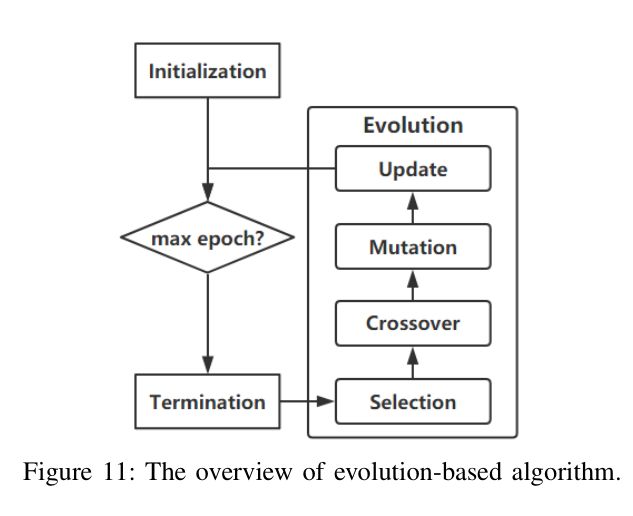
1)Selection
假设我们初始时候一共有10个,我们第一步就是selection,即选择一部分(比如50%)网络作为父网络来生成子网络,选择的方式主要有三种:
- fitness selection
- rank selection
- tournament selection
2)Crossover
这一步就是parent网络两两配对,类似于染色体结合,双方各自提供一部分结构用于生成后代。但是网络模型如何crossover呢?这就需要对模型编码,编码方式大体有两种:
- 一种就是binary encoding,即0100101..., 每一位代表什么意思可以自己定,这种编码做crossover很好理解,比如说可以设置为二进制运算,异或运算等等,这个可以自己设置。
- 还有一种编码方式是cellular encoding,这其实是一种tree结构,所以这种结构做crossover就是对sub-tree做替换。
3)mutation
这个就是我们常说的 (基因)突变,这也是为了让模型结构更加丰富,binary encoding很简单,就是0变1,1变0,当然突变是有一定概率的,这个也需要我们设置。当然除了point mutation,我们也可以设置一段序列突变等等,方式很多种,具体详见论文。不过总的来说无非就是变了两种结构:一是不同层之间的连接做了变化,另一种就是对某一层的具体运算操作做了突变。
4)update
因为计算资源有限,我们如果无限制地生成新的网络而不把旧的网络去掉,那么内存会爆炸啊,不过也有特例,按照这篇论文【4】介绍的,他们就没有删除任何模型。所以总结起来更新一共有三种策略:
- 去掉表现最差的若干个模型
- 去掉最久远的若干个模型
- 定期丢掉所有模型(这个也是蛮极端的。。。)
4.2.3 Bayesian optimization
前面几种优化算法都是靠运气,贝叶斯优化呢则是对之前实验结果建模来预测下一次优化方向,大致的算法思路如下:

更多的可以阅读原文或者阅读这篇文章贝叶斯优化(Bayesian Optimization)深入理解。
4.2.4 Reinforcement learning
最开始提出NAS的文章【5】就是用了强化学习思想,后续基于强化学习的算法也大都遵循下图的计算逻辑,即一个agent来生成新的网络结构,这个agent通常是一个RNN网络;之后生成的模型在训练集上训练一段时间,之后在验证集上进行测试得到reward(例如准确率),这个reward就会被拿来更新agent。

大致上的区别就是使用的强化学习算法不同:
- 【5】使用的是policy gradient algorithm
- 【6】使用PPO算法
- 【7】MetaQNN使用Q-learning算法
但是上述算法效率都不太高,而ENAS的提出极大地提高了强化学习算法的效率,按ENAS【8】的说法是它比【4】提高了将近1000倍,具体算法介绍可以阅读论文笔记系列-Efficient Neural Architecture Search via Parameter Sharing。
4.2.5 Gradient descent
前面算法都是在离散空间中搜索和优化,而DARTS【9】的提出将连续优化成为可能,后面很多连续优化也是基于这个算法,更多细节可以阅读原论文和论文笔记系列-DARTS: Differentiable Architecture Search。

当然DARTS也有缺点,其一是每次计算会把所有操作都纳入计算图中,这会使得显存占用爆照,所以很难搜索较大的模型,ProxylessNAS用BinaryConnect来解决内存占用大的问题,SNAS的思想很接近,是用one-hot方式来选择概率最高的一个操作进行计算。另一个问题就是DARTS在搜索后期会倾向于Skip-connection这个操作,这个操作一旦过多会导致模型参数变深,但是参数变少,反而会使得模型性能降低,所以 DARTS+ 提出了earl-stopping来解决这个问题,P-DARTS也是用类似的方法来抑制skip-connection数量。
5. Model Estimation
模型生成好了,就得评估它的好坏。比较简单粗暴的方式就是生成一个模型后,把这个模型训练至收敛,然后在验证集上评估,但是这种方式耗时耗力,所以有不少方法来加速评估。
5.1 Low-fidelity
一种就是降低fidelity,比如FABOLAS【10】使用训练集的子集来训练和评估模型,还有的降低输入图像的分辨率来加速。这篇文章【11】则是通过将多个low-fidelity做ensemble,这样既保证了评估的准确性,又提高了效率。还有其他方法可以详见论文。
5.2 Weight-sharing
前面提到的ENAS就是通过weight sharing来提高了模型训练和评估的速度,Single-path NAS【12】也是类似的思路。
5.3 Surrogate
这个简单理解就是用另外一个模型来预测生成的模型的好坏,比如PNAS【13】就是这个方法的代表。
5.4 Early-stopping
前面提到的 DARTS+ 是使用早停机制来控制skip-connection的数量,早停机制也可以用来加速评估,避免浪费时间和过拟合。比如【14】则通过学习拟合出learning curve来判断什么时候停止。
5.5 Resource-aware
之前不少NAS算法只关注找到表现好的模型,而忽略了模型大小,因为说到底我们找模型是为了应用到实际,而很多情况是希望能移植到移动设备上,所以也有很多方法把resource纳入了考虑,比较受关注的方法是MnasNet,这是Google提出的,它的设计思路也成了后面很多方法的范式。那么如何设计resource-aware的模型呢?一种就是想MnasNet一样,它借鉴了MobileNet的设计思路,指定operation为MBConv,这种设计方式使得参数量少,而且效果还不错。另一种就是在loss函数中加入约束项。这个约束项的值可以是1)模型参数大小;2)Multiply-ACcumulate (MAC) 计算数量;3)FLOPs数量;4)模型在真实设备上的延迟。比如MONAS【15】是一个基于强化学习的算法,所以它直接MAC加入到reward function中来控制模型大小。而对于基于梯度更新的算法,显然不能直接在loss中加上这个常数,因为你求导等于0,并没有什么贡献。MnasNet则是通过设计了一种自定义的loss函数来使得可求导,公式为:
\[ \underset{m}{\operatorname{maximize}} \quad A C C(m) \times\left[\frac{L A T(m)}{T}\right]^{w} \]
where \(w\) is the weight factor defined as:
\[ w=\left\{\begin{array}{ll} {\alpha,} & {\text { if } L A T(m) \leq T} \\ {\beta,} & {\text { otherwise }} \end{array}\right. \]
FBNet是通过查表的方式来获得每个操作的延迟时间,SNAS中延迟与网络结构线性相关,这样便可以求导了。
6. NAS Performance Summary
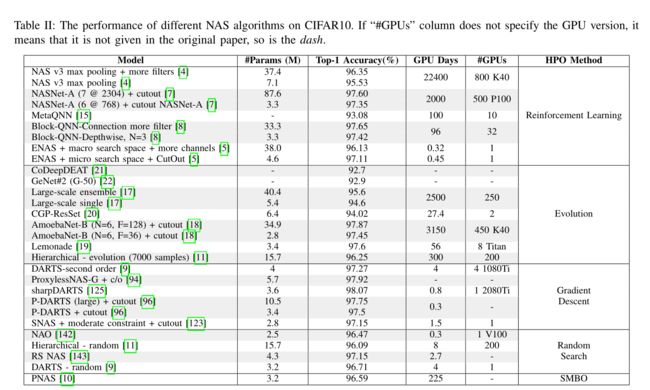
这一章是对NAS算法在CIFAR10上做比较,结果如下:
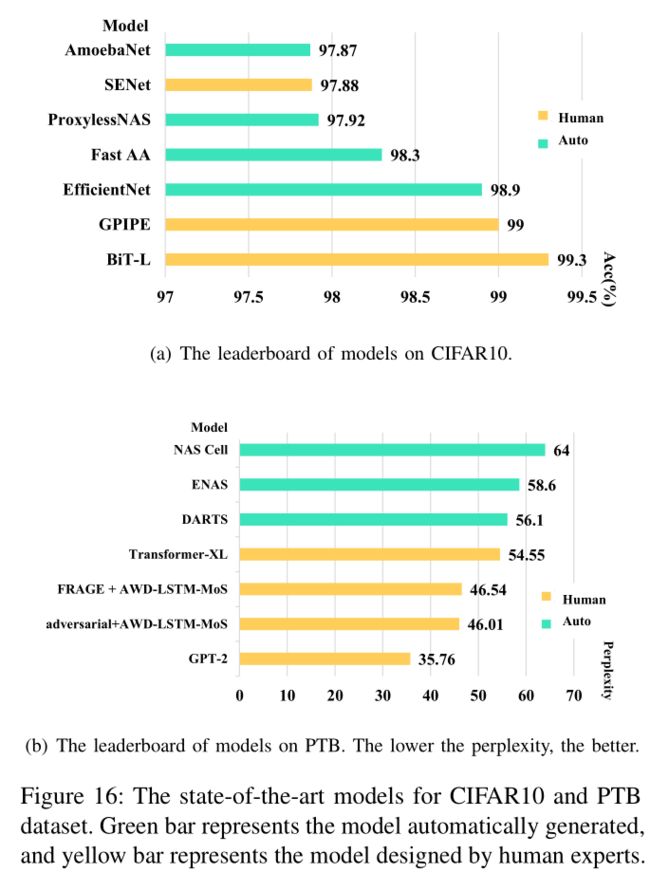
在CIFAR10和PTB上与人类设计SOTA模型比较:
7. Open Problems and Future Work
- 完整的pipeline系统
即真正地实现端到端的AutoML Pipeline系统,这个应该终极目标。
- 可解释性
- 可复现性
- 编码方式
现在很多NAS算法对网络模型的编码都是基于人类的经验设计的,有没有一种更广泛通用的编码方式找到跳脱与人类思维的结构呢?比如说Transformer这种复杂的结构用现如今的NAS技术肯定是找不出来的。
- 应用到更多领域
目前NAS更多的是应用在计算机视觉上,在其他领域还有待开发
- lifelong learning
结语
通过博文的方式来介绍论文总会丢失一些细节,因此对某个部分感兴趣的还是推荐自己去阅读一下原文。也希望论文和这两篇博文能够帮助大家对AutoML有一个比较全面的了解,当然如果文章中有任何问题也欢迎指出,如果你在AutoML中也发表了一些成果也欢迎留言或者私戳我,我们在审核后也会更新的论文里去,谢谢!
参考
- 【1】C.-W. Hsu, C.-C. Chang, C.-J. Lin et al., “A practical guide to support vector classification,” 2003
- 【2】J. Y. Hesterman, L. Caucci, M. A. Kupinski, H. H. Barrett, and L. R. Furenlid, “Maximum-likelihood estimation with a contracting-grid search algorithm,” IEEE transactions on nuclear science, vol. 57, no. 3, pp. 1077–1084, 2010.
- 【3】L. Li, K. Jamieson, G. DeSalvo, A. Rostamizadeh, and A. Talwalkar, “Hyperband: A novel bandit-based approach to hyperparameter optimization.”
- 【4】H. Liu, K. Simonyan, O. Vinyals, C. Fernando, and K. Kavukcuoglu, “Hierarchical representations for efficient architecture search,” in ICLR, p. 13.
- 【5】Neural Architecture Search with Reinforcement Learning
- 【6】B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, “Learning transferable architectures for scalable image recognition.
- 【7】B. Baker, O. Gupta, N. Naik, and R. Raskar, “Designing neural network architectures using reinforcement learning,” vol. ICLR
- 【8】H. Pham, M. Y. Guan, B. Zoph, Q. V. Le, and J. Dean, “Efficient neural architecture search via parameter sharing,” vol. ICML.
- 【9】H. Liu, K. Simonyan, and Y. Yang, “DARTS: Differentiable architecture search.”
- 【10】A. Klein, S. Falkner, S. Bartels, P. Hennig, and F. Hutter, “Fast bayesian optimization of machine learning hyperparameters on large datasets.”
- 【11】Y.-q. Hu, Y. Yu, W.-w. Tu, Q. Yang, Y. Chen, and W. Dai, “Multi-Fidelity Automatic Hyper-Parameter Tuning via Transfer Series Expansion ,” p. 8, 2019.
- 【12】D. Stamoulis, R. Ding, D. Wang, D. Lymberopoulos, B. Priyantha, J. Liu, and D. Marculescu, “Single-path nas: Designing hardware-efficient convnets in less than 4 hours,”.
- 【13】C. Liu, B. Zoph, M. Neumann, J. Shlens, W. Hua, L.-J. Li, L. Fei-Fei, A. Yuille, J. Huang, and K. Murphy, “Progressive neural architecture search.”
- 【14】T. Domhan, J. T. Springenberg, and F. Hutter, “Speeding up automatic hyperparameter optimization of deep neural networks by extrapolation of learning curves,” in Twenty-Fourth International Joint Conference on Artificial Intelligence, 2015.
- 【15】C.-H. Hsu, S.-H. Chang, J.-H. Liang, H.-P. Chou, C.-H. Liu, S.-C. Chang, J.-Y. Pan, Y.-T. Chen, W. Wei, and D.-C. Juan, “Monas: Multi-objective neural architecture search using reinforcement learning,” arXiv preprint arXiv:1806.10332, 2018.