一、前言
虽然我们大多数人都学习过SQL,但是经常忽略它。总是会自以为学到的已经足够用了,从而导致我们在实际开发的过程中遇到复杂的问题后只能在检索数据后通过传统的代码来完成,但是其中很多的功能利用SQL就可以轻松的办到,所以我们开始重视SQL,它的地位不亚于C#,javascript。
二、目录
1.多行插入
2.将其他表数据插入
3.子查询
4.通用表表达式(CTE)
5.MERGE指令
6.窗口化函数
7.查询分页
三、正文
1.多行插入
大家都学习过INSERT,但是每次我们都只插入一条数据,如果我们需要插入多条数据呢,那么情况就会和图1.1一样。
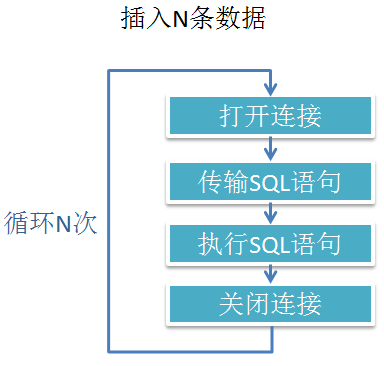
图1.1
上面是最简单的示例,我们还可以进行一定的优化,避免循环建立和关闭连接的次数,比如下图(图1.2)

图1.2
即使我们采用了图1.2所示的方式,既然会长时间的占据带框,并且Web服务器和数据库服务器既然要进行多次连接,如果使用本节的知识我们就可以做到图1.3所示的效果。
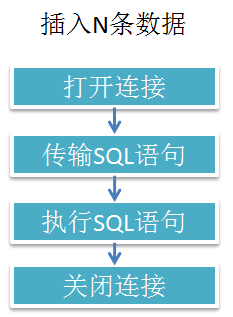
图1.3
首先我们先来看看普通的插入语句:
1 INSERT INTO Cou_Course(CourseID,TeacherID,SemesterID,CourseName,CourseType,CourseState) 2 VALUES('235648651235423512','12312421421','12124214124','awefweagwaeg','123','124124')
每次插入一条新的数据都要重新一次,如果是批量的添加就可想而知了,而如果我们直接通过一条插入语句插入多条数据就可以这样做:
1 INSERT INTO Cou_Course(CourseID,TeacherID,SemesterID,CourseName,CourseType,CourseState) 2 VALUES('235648651235423515','12312421421','12124214124','awefweagwaeg','123','124124'), 3 ('235648651235423514','12312421421','12124214124','awefweagwaeg','123','124124'), 4 ('235648651235423517','12312421421','12124214124','awefweagwaeg','123','124124')
当然语法也很简单,只要用逗号来分割就可以了。虽然仅仅只是一个简单的技巧,但是又有多少人会使用呢?
2.将其他表数据插入
解决了批量插入的问题,我们还会遇到将其他表的数据插入到另一个表中的需求,特别是在编写存储过程中我们可能会对数据进行处理,并把处理的结果存放在临时表中,最后才将临时表中的数据全部添加到实际的表中,如果利用传统的做法会非常麻烦,而通过本节介绍的知识将可以很轻松的实现。
首先我们需要做一些简单的准备工作,这里我们需要创建两个表,A表(id为自增),B表跟A表一样,然后我们在A表中随意写一些内容:
![]()
然后利用 INSERT INTO … SELECT … 来实现将A表的数据添加到B表中去:
INSERT INTO B(Name) SELECT Name FROM A
当然读者看过之后会觉得非常简单,因为我们现在仅仅只是学习这个知识点,重点在于我们能够记住它,并能够在后面使用它(实际开发中会比这更复杂,但是基本的东西还是不变的)
3.子查询
在正常的使用中我们经常会遇到无法使用链接的情况,但是我们需要根据另一个表的情况来决定当前的SELECT,这个时候我们就需要子查询。笔者在这里只能例举简单的示例,实际的需求会出现非常复杂的子查询。这里我们还是借助上面的A、B表,首先实现的功能是检索A表,但是条件是A表的Name要在B表中存在:
SELECT id,Name FROM A WHERE EXISTS( SELECT Name FROM B WHERE B.Name = A.Name )
上面的语句中我们在WHERE中就使用了子查询负责去B表中查询是否存在记录,而EXISTS的作用就是EXISTS括号中的语句只要返回了一个或一个以上的结果则成立。所以最后我们可以看到所有的数据都呈现了。当然子查询不仅仅可以用于条件中,我们还可以用于SELECT后,比如我们根据A表的Name去B表中查询Name跟它一样的id号:
SELECT (SELECT TOP 1 B.id FROM B WHERE B.Name = A.Name) FROM A
子查询的用处非常多,也非常强大,远不止笔者这里介绍的这么一点。
4.通用表表达式(CTE)
虽然这个名字很专业,但是实际用起来是非常简单的,当然简单的同时也帮助我们解决了很多的问题,最终的效果跟临时表一样,但是使用起来比临时表更方便。比如下面的代码我们将创建一个名为MyCTE的临时表:
WITH MyCTE AS( SELECT * FROM A ) SELECT * FROM MyCTE
是不是非常简单,当然还可以同时定义多个通用表,比如下面的代码所示:
1 WITH MyCTE AS( 2 SELECT * FROM A 3 ), MyCTE2 AS( 4 SELECT * FROM B 5 ) 6 SELECT * FROM MyCTE,MyCTE2
多个通用表只需要用逗号分割即可,当然我们这里还涉及了一个知识点,相信有人会发觉出来。
5.MERGE指令
这个指令是SQL SERVER 2008中新增的,相比前面几个来说比较难懂,但是作用却非常强大,利用这个指令我们可以同时进行添加、修改和删除,并且是由条件的。具体的实现方式就是根据源表与目标表进行对比,如果匹配则执行对应的更新操作,如果源表中存在,但是目标表不存在则执行添加操作,如果相反则执行删除操作。下面我们将通过循序渐进的方式来介绍如何使用MERGE,首先我们需要确定目标表,因为后面的更新,添加和删除操作都是针对目标表的,所以目标表只能是一个表不能是检索后的数据,比如下面的代码我们将前面我们示例中使用的A表作为目标表:
1 MERGE A AS itarget
有了目标表还不足够,我们还要需要一个源表,用来形成对比,而源表则可以是检索语句,因为笔者这里只是简单的示例,所以直接检索了B表中的数据:
1 USING( 2 SELECT * FROM B 3 ) AS isource
这样我们就有了目标表和源表,最后合并:
1 MERGE A AS itarget 2 USING( 3 SELECT * FROM B 4 ) AS isource
接着我们需要指定对应的条件,从而根据是否符合这个条件而决定对目标表进行什么操作,比如下面的语句将判断两表中是否存在相同id的数据:
ON (itarget.id = isource.id)
有了条件后,我们就可以根据这个条件进行对应的操作了,笔者将在满足这个条件后修改目标表的Name,在后面追加change字符串:
1 WHEN MATCHED THEN 2 UPDATE SET itarget.Name = itarget.Name + 'change'
最后的语句如下所示:
1 MERGE A AS itarget 2 USING( 3 SELECT * FROM B 4 ) AS isource 5 ON (itarget.id = isource.id) 6 WHEN MATCHED THEN 7 UPDATE SET itarget.Name = itarget.Name + 'change';
最后我们查看A表,发现数据都改变了:
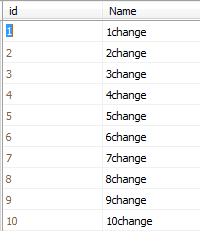
这个时候我们在A表新添加一条数据,以满足源表不匹配的情况,然后在原本的语句后面添加如下的语句:
WHEN NOT MATCHED BY SOURCE THEN DELETE;
我们可以猜测出,当目标表中存在源表中不存在的数据后将会删除这条数据,所以执行后我们将看到A表新添加的数据已经被删除了,完整的语句如下所示:
1 MERGE A AS itarget 2 USING( 3 SELECT * FROM B 4 ) AS isource 5 ON (itarget.id = isource.id) 6 WHEN MATCHED THEN 7 UPDATE SET itarget.Name = itarget.Name 8 WHEN NOT MATCHED BY SOURCE THEN 9 DELETE;
最后就是源表中存在,但是目标表中不存在的情况了,我们只需要将上面的BY SOURCE改成BY TARGET即可,通过下面这条语句我们将把源表与目标表不匹配的数据添加到目标表中去(当然我们需要提前在源表中新增一条数据):
WHEN NOT MATCHED BY TARGET THEN INSERT (Name) VALUES(isource.Name);
执行完成后我们将看到A表多了几条数据。下面是完整的语句:
1 MERGE A AS itarget 2 USING( 3 SELECT * FROM B 4 ) AS isource 5 ON (itarget.id = isource.id) 6 WHEN MATCHED THEN 7 UPDATE SET itarget.Name = itarget.Name 8 WHEN NOT MATCHED BY SOURCE THEN 9 DELETE 10 WHEN NOT MATCHED BY TARGET THEN 11 INSERT (Name) VALUES(isource.Name);
6.窗口化函数
首先是ROW_NUMBER,顾名思义,就是给我们检索出来的数据加上序号,旧的分页都是采用这种方式,但是往往我们仅仅只是使用了它的一点,他还可以分块进行标序号,比如我们将上面的A表改成如下形式:

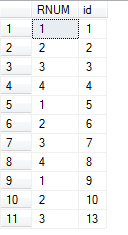
然后采用如下所示的SQL语句,就可以按照Name进行标序号:
SELECT ROW_NUMBER() OVER(PARTITION BY A.Name ORDER BY A.id) AS 'RNUM',id FROM A
结果如下所示:
下面我们通过一段SQL以及对应的结果呈现其他的窗口化函数:
SELECT ROW_NUMBER() OVER(PARTITION BY A.Name ORDER BY A.id) AS 'RNUM', RANK() OVER(ORDER BY A.Name) AS 'RANK', DENSE_RANK() OVER(ORDER BY A.Name) AS 'DENSE RANK', NTILE(4) OVER(ORDER BY A.id) AS 'NTILE' FROM A
结果如下所示:
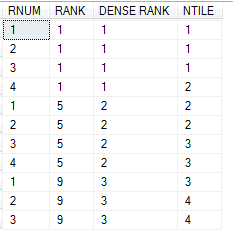
其中简单介绍下NTILE,我们传了一个4那么它会将前面1/4标记为1,然后接着标记1/4为2,以此类推。关于RANK和DENSE_RANK比较好理解,看看最后的结果就可以得出结论了。
7.分页查询
这是最后一节了,但是相关的语句却很简单,我们只要记住以下关键字就可以了:
OFFSET…FETCH NEXT…
比如下面的SQL语句,我们将跳过前面5条数据,获取3条数据:
1 SELECT * FROM A 2 ORDER BY A.id 3 OFFSET 5 ROWS 4 FETCH NEXT 3 ROWS ONLY