一、为什么要学习大数据?
我们对数据的存储以及处理大致可以划分为以下几个阶段:
1.单纯靠人脑记忆:远古时期的智人,买东西的时候不会记录下来自己这次花了多少钱,买了多少东西,只是单纯的记录在自己的大脑里,很快就会忘记,记都记不住更不用说去分析处理一下数据了。
2.记录在纸上:有了造纸术之后,我们就把数据记录到了纸上,数据就不那么容易丢失,而且我们还可以对数据做一些简单的处理,比如说记个账,算算自己这一个月总共花了多少钱。这个时期数据已经可以存储下来了,并且还可以做一些简单的计算,但是,纸容易腐烂导致数据易丢失,可靠性不是很高。
3.记录在磁盘/U盘中:有了计算机之后,有了磁盘,后来又有了U盘,我们就可以把原来写在纸上的东西以文件的形式放到磁盘中,磁盘不容易坏,这大大提高了数据的可靠性。
4.分布式的存储:对于少量数据的存储和处理,我们只需要用一个磁盘就可以解决,但是随着数据量的增加,任何单一的磁盘都不足以容纳海量的数据。当一头牛拉不动的时候,不要试图用一头更强壮的牛,用两头牛。所以我们就会使用两块磁盘来存储,就有了分布式存储这一概念。数据的存储在多台机器上,自然,数据的处理也发生在多台机器上。对于存储在多台机器上的数据,其数据存储方式和处理方式自然有别于在单台机器上存取和处理数据。因此,大家学习大数据技术的目的就是为了解决在多台机器上存取和处理海量数据这两个问题的。
【大数据开发学习资料领取方式】:加入大数据技术学习交流群458345782,点击加入群聊,私信管理员即可免费领取
啥叫分布式存储?就是分开存储,分开管理呗;那啥叫分布式计算?就是你算 50%,我算 50%,咱俩合起来 100%呗。大家在学习大数据的时候会遇到很多或许你从未听过的名词,不要被那些专业术语吓到,说白了都是学术界搞的装13的词。
就像你学习 Spring 的时候有人就会这样跟你说:先学习 IOC 和 AOP 思想。博主当初学的时候上网上到处找关于 IOC 和 AOP 思想的文章看,看了很多还是看不懂。最后找了个 Spring 的视频,跟着视频敲了几天代码就搞懂了,在类上加个@Service,@Repository,@Component注解,在需要这些类实例的成员变量上加上@Autowired注解,这样在 Spring 启动的时候就会自动创建被@Service,@Repository,@Component注解的类的对象,并且会把对象的引用赋值给被@Autowired注解的成员变量上,然后你写代码的时候就不用手动 new 对象了,这就把对象的控制权从你的手上转移到 Spring 上了,这就 IOC(控制反转) 了;再比如@Transactional注解,大家在做事务性操作(增删改)的时候经常使用,它内部其实就是先把向数据库自动提交 SQL 语句的操作关上,然后等你的所有 SQL 全部执行完毕,在把自动提交开开,然后你对数据库的操作就要么全部执行成功,要么全部执行失败了,你只要是想实现事务,在方法上加上@Transactional注解就可以了,也不用在业务代码里面去改自动开关连接了,就不会污染你的代码了,这就 AOP(面向切面编程)了。就这么回事。
二、如何学习大数据?
知道了为什么要学习大数据,那么该如何学习大数据呢?该学习哪些东西呢?从哪里开始呢?
1. 分布式存储
首先是解决海量数据的存储,大家学习大数据第一步就是要学习 HDFS(Hadoop Distributed File System),HDFS 是在 Linux 之上的一套分布式的文件系统。
大家首先要学会熟练安装 hadoop(因为 hadoop 中包含了 hdfs)(大家也不要对安装这个词过于畏惧,其实就是解压个 jar 包,配置个环境变量,非常轻量的,在电脑上安装个虚拟机,反复练就完了,弄坏了,重新新建个虚拟机就行了),然后要熟练掌握 HDFS 的基本命令(其实,你使用 hdfs 的命令和使用 linux 的命令差不多,比方说,我们在 linux 中创建目录的命令是:mkdir temp,使用 hdfs 创建目录的命令是:hdfs dfs -mkdir /temp),熟练使用 hdfs 是大数据的基本功,就像你要在 linux 上做开发,一些基本的 linux 命令你就必须掌握;你要在 HDFS 上做大数据开发,那么一些基本的 hdfs 命令你就必须掌握。
同时,HDFS 也是后续分布式计算数据的主要来源,它的重要性就好比我们做 J2EE 开发时的数据库一样。做 Java 开发我们主要是操作 MySql 数据库中的数据,对数据库中的数据进行增删改查;而做大数据开发我们操作的数据大部分都是 HDFS 上的,对 HDFS 上的数据进行复杂查询。
注意:HDFS 上的数据是不会修改和删除的,因为大数据开发的主要目的是针对已有的海量数据做分析,而不是做事务性操作。比方说:我们经常会分析网站某天的流量变化情况,而用户访问网站这个行为属于历史行为,是不可以修改的,如果修改了,那么后续的数据分析工作都毫无意义了;或许会有人问:那如果有一些错误的数据怎么办呢?我们在分析数据之前会有一步操作,叫数据清洗,在这步操作中,会把一些错误的不准确的数据过滤掉。
学完了 HDFS 大家其实就可以学习一个基于 HDFS 的 NoSQL => HBASE。

HBase 是以 HDFS 为基础的,HDFS 的数据是存在磁盘上的,那它为什么叫 NoSql 呢?
HBase 的数据存储的格式不同于传统的关系型数据库,关系型数据库是以行为单位进行存储,而 HBase 是以列为单位进行存储,也是以 key-value 对的方式来存储数据的,存储的数据会先放在内存中,内存满了再持久化到 HDFS。
2. 分布式计算
学会了如何存取 HDFS 上的数据,接下来我们就需要学习如何对 HDFS 上的数据进行计算。因为 HDFS 属于分布式文件系统,在分布式文件系统上对数据的计算,自然也就叫分布式计算。分布式计算又分两种:离线计算,实时计算;还可以称这两种计算方式分别为批处理,流计算。对于这两种计算,我们首先要先学习离线计算,然后再学习实时计算。
2.1. 离线计算/批处理
大家在做 JavaEE 开发时,比如:电商后台统计所有订单的签收情况,订单签收情况来源于订单的物流轨迹,而查询订单的物流轨迹又需要调用对应物流公司提供的API,而物流公司为了防止频繁调用API发生 DDOS,常常对接口 API 进行调用的限制(例如:1秒只允许查询一次)。所以,对于大量的订单没有办法立即获得统计结果;因此,对于这样耗时比较长的计算,就会写成一个定时任务,每天晚上执行一次计算,第二天看结果。
大数据领域的离线计算和上面的例子类似,我们写完了一个离线计算程序(MapReduce 程序或 Spark程序)之后,提交到服务器集群上,然后它就开始运行,几个小时之后或者第二天获取运行结果。与 JavaEE 的定时任务不同的是:大数据领域计算的数据量是巨大的,通常是 PB 级别的,只用单机的定时任务来处理数据那猴年马月也计算不完,而大数据领域使用分布式的离线计算则可以大大地减少时间。
2.1.1. MapReduce
离线计算首先要学习的就是开发 MapReduce 程序。
开发 MapReduce 程序的步骤如下:
•创建 Maven 工程•导入 Hadoop 所需的 pom 依赖•继承相关的类,实现相关的方法•编写主程序,含 main 方法的那个类•打成 jar 包•上传到 linux 服务器上•执行 hadoop 命令将 mapreduce 程序提交到 yarn 上运行
看了上面的步骤之后,大家对 mapreduce 程序应该不是那么的畏惧了,就像开发我们的 JavaEE 项目一样简单。
上面出现了一个大家不熟悉的词:yarn。yarn相当于一个运行 mapreduce 程序的容器;它就好比大家在 J2EE 开发的时候使用的 Tomcat,Weblogic。yarn 没有什么好说的就是一个资源分配运行 mapreduce 程序的容器。
2.1.2. Hive

学习完了开发 mapreduce 程序,再学习 Hive。
为什么要按照这个顺序?
hive是啥?
在网上一搜,有人说它是数据仓库,有人说它是数据分析引擎,那它到底是啥?有没有说人话的来解释一下?---- 博主当时百度的时候就是这么想的。
1.学 hive 首先也要先学会安装(其实也是官网下载压缩包,解压,配置环境变量,修改配置文件,执行命令初始化),这里暂不讨论。
2.之后再在 linux 上执行命令hive,就启动了 hive,启动过程就类似 mysql 的 CMD 窗口的启动过程。
3.然后大家就可以在 hive 里面输入 SQL 语句,像show tables;,select * from bigtable;,就像操作 mysql 一样去操作 hive。所以,有人称 hive 为数据仓库。那么 hive 里面的数据存储在哪里呢?相信大家已经猜到了,就是一开始提到的 HDFS 中。
4.那么,为什么又有人称 hive 为数据分析引擎呢?大家在 hive 中执行 SQL 语句时有想过 hive 对这条语句做了什么吗?其实,hive 是把这条查询语句转化成了一个 mapreduce 程序,我们在 hive 中执行的复杂查询其实都是转换成了一个 mapreduce 程序,而 mapreduce 程序它是用来做分布式计算的,所以就有人称 hive 为数据分析引擎。
学习 hive 其实就是在学习 hive 的查询语句(Hive Query Language),建表语句,就和操作 mysql 查询数据类似。
2.1.3. Pig
另一个和 Hive 类似的数据分析引擎叫 Pig,它使用一种叫 Piglatin 的查询语句来查询数据,企业中用的不多,大部分用的都是 Hive,感兴趣的同学可以自行百度。
2.1.4. Sqoop
无论是手动编写 mapreduce 程序还是直接使用 hive 来处理数据,操作的都是 hdfs 上的数据,那 hdfs 上的数据又是哪里来的呢?难道是手动输入的?
拿电商来举例,我们的订单数据都是存在关系型数据库 MySql,Oracle 中的,而我们需要操作 HDFS 上的数据,就需要把我们关系型数据库中的数据导入到 HDFS 上;对于处理完的数据,又需要导出到关系型数据库中(因为前端界面展示的数据主要都是去查的数据库)。Sqoop 的功能就是在关系型数据库和 HDFS 之间导入和导出数据。
其实学 sqoop 也很简单,首先是安装(和 hive 类似,其实整个大数据中大部分框架的安装过程都是类似的:官网下载压缩包,解压,改配置文件,执行命令初始化),然后是执行 sqoop 命令,学习 sqoop 其实就是学习 sqoop 命令。
例:将 mysql 中的数据导入到 HDFS 上:sqoop import --connect jdbc:mysql://localhost:3306/dbname --username root --password 123 --table cate --target-dir /data
2.1.5. Flume
学完了 sqoop,我们已经可以把 mysql,oracle 上的数据导入到 HDFS 上了,那么对于一些访问日志,像 Ngnix 的访问日志,怎么将这些日志文件导入到 HDFS 上呢?
所以,接下来我们就要学习 Flume 这个日志采集引擎(当然,你也可以先学 FLume),它的主要作用就是采集日志文件,监控文件或目录,当文件或目录的内容发生变化后实时的将数据发送到指定目的。
先官网下载压缩包,解压,修改环境变量,修改配置文件,然后执行命令启动 flume,flume会根据你配置文件中的参数,去监控指定的文件或目录,当文件或目录内容发生变化的时候就会将数据发送到 HDFS 或者其他的目的。
PS:大数据的大部分框架(99%)的安装过程都类似,后面就不再啰嗦了。
2.1.6. Spark
其实学完上面的部分,离线计算的部分已经差不多了,已经可以解决一些需求了。但是,人类的欲望总是永无止境的,总是渴望更高,更快,更强。mapreduce 计算框架在计算的时候,每一步的计算结果都是持久化到磁盘上的,在进行下一步操作的时候就需要进行磁盘IO,效率就比较低。
因此,Spark 横空出世。Spark 把中间过程的计算结果放在内存中,因此大大提高了离线计算的计算效率。Spark 也是企业中使用最广的大数据计算框架,因为它还提供了一个可以进行实时计算的子模块 SparkStreaming,后面会提到(就像 Spring 有 SpringMVC 这个子模块一样)。Spark 既可以进行离线计算也可以使用 SparkStreaming 进行实时计算,所以大部分企业都会选择使用 Spark 来作为核心的计算框架(因为统一了嘛,实现需求的时候就不用这个功能用A框架实现,另一个功能用B框架实现,不好维护),而 Hadoop 中的 mapreduce 框架只是起一个辅助作用。
2.1.7. Scala

大家在学习 Spark 之前需要先学一门语言:Scala。Scala 是一个语法比较杂的编程语言,你学 Scala 的时候会觉得它和 JS,Java,C++ 都有点像;而且它兼容 Java,也运行在 JVM 上,你用 Java 写的工具类和方法可以直接被 Scala 类方法调用,反之亦然。
虽然 Spark 程序也可以使用 Java 来编写,但是,用 Scala 编写会更加简洁一些,一般企业中编写 Spark 程序也是用的 Scala,很多大数据的招聘也要求你得会使用 Scala。
2.2. 实时计算/流计算
像统计过去一年订单中某件商品的销售总额这类需求,对实时性要求不高,一般会使用离线计算程序(mapreduce)来计算。但是,像网站访问的PV,UV,每天各小时的流量这种类型的需求,hadoop 的 mapreduce 框架或者叫编程模型的计算效率就有点低。所以为了应对实时性较高的需求就需要学习一些实时计算框架。
2.2.1. Storm
Storm 属于老牌经典的实时计算框架,大部分公司内部都有使用,编程模式和 mapreduce 极其相似,导 jar 包,实现接口,main 方法,打 jar 包,向集群提交,运行。
在本地编写 Storm 程序也是相当的方便,环境都不需要配,建立 maven 工程导入依赖,写代码,右击运行就 OK。
2.2.2. JStorm
Jstorm 是阿里在 Strom 的基础上对其性能进行了改良和优化后的产物,用法和 Strom 类似,你用 storm 写的代码都不需要做太大的修改就可以直接运行在 JStorm 集群上。
2.2.3. SparkStreaming
在上面讲离线计算的时候已经提到了 SparkStreaming,它是 Spark 的一个子模块,用于进行实时计算,那它和 Strom 有什么不同呢?
Strom 是真正的实时,来一个数据就处理一个;而 SparkStreaming 是以时间段的方式,是个伪实时,比如每过 5 秒才集中处理一下过去5秒内的发送过来的数据。
Storm 和 SparkStreaming 在企业中可以说是平分秋色,用的都比较多。
2.2.4. Kafka

Storm,JStorm,SparkStreaming 它们接收的都是实时发送过来的数据,那这个数据是从哪里来的呢?
在介绍离线计算的时候,我们知道了 Flume 可以实时的监控文件目录,当文件内容增多或目录中的文件发生变化时可以发送数据到指定目的,这里的目的就可以是 Storm,JStorm,SparkStreaming。但是,数据发送速度非常快的时候,有的数据可能来不及接收,然后数据就丢失了,针对这种情况我们一般会使用消息中间件来做缓存,暂时的将发送过来的数据缓存到中间件里。Kafka 就是大数据常用的一种消息中间件。
在企业中一般的做法是:Flume 实时监控目录或文件末尾,数据发生变化后送到 Kafka 缓存,Kafka 再将数据送到 SparkStreaming,Storm等实时计算组件中。
所以,大家在学实时计算框架的时候也需要学一下 Kafka 这个缓存组件。
2.2.5. Zookeeper
最后,大数据技术要真正应用于企业的开发,需要保证它的 HA(High Availaibility) 高可用性,大家在搭建 Hadoop 集群,Spark 集群,Storm 集群的时候都会用上 Zookeeper,将 Hadoop,Spark,Storm 的元信息存储到 Zookeeper 上,防止因为某个节点宕机而造成数据计算失败。
其实,根据名字和图片大家就可以猜出来 Zookeeper 在整个大数据体系中的作用:动物园管理者。Hadoop 是一头大象,Hive 是个小蜜蜂,HBase 是小鲸鱼,Pig 是一头猪...,zookeeper 就是用来确保这些 "小动物" 的稳定性可用性。
三、大数据整体架构
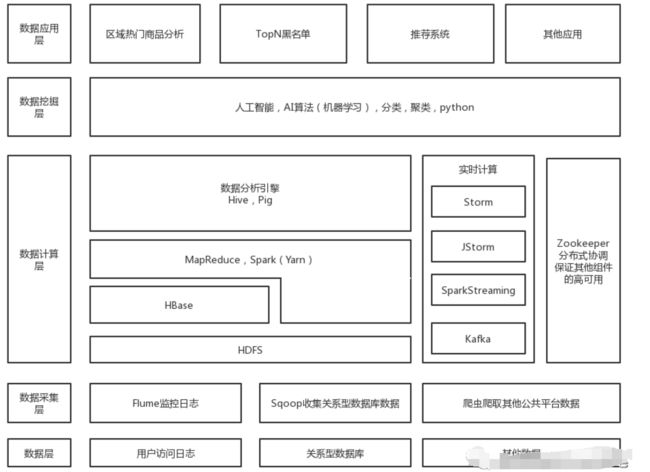
最后上一幅博主手绘的大数据架构图。企业中的大数据平台整体架构和上面的类似。
•最底层是数据源,可以来自关系型数据库,用户访问日志等。•网上就是数据采集层,就需要我们使用 Sqoop / Flume 采集关系型数据库,日志中的数据,当然,我们也可以使用爬虫去爬取其他公共网站的数据。•再往上,我们采集完了数据就要把它存储到 HDFS 上,实时的就送到 Kafka。离线计算就用 Hive,MapReduce 调 HDFS 的数据,实时的就通过 Storm,JStorm,SparkStreaming 取 Kafka 中的数据再进行计算。•再向上,就是数据挖掘层,就是一直炒的火热的人工智能,机器学习,深度学习云云。其实就是一系列复杂的算法,而这都是在拥有海量数据的基础之上才能开始做的,没有数据做支撑,算法就是个空壳,就好像你买了个榨汁机,但是却没有水果。所以,就有人说:大数据是人工智能的血液。•再向上,就是大家最熟悉的一层,产品经理就住在这一层。【大数据开发学习资料领取方式】:加入大数据技术学习交流qq群522189307,点击加入群聊,私信管理员即可免费领取
相信看到这里大家对大数据已经没有那么陌生了。
最后,祝大家顺利入门大数据,找到一份好工作。