模块数据
很多Odoo模型中的定义,例如用户视图界面,安全规则,实际上都是储存在特殊的数据库表中。我们在模块中编写的XML,CSV文件并不是在Odoo运行时使用的,这些文件的意义是在Odoo运行前把我们定义好的那些视图,规则全部加在到数据库表中。
因为这个原因,所有Odoo中很重要的一个部分就是数据表示(序列化)那些文件中的数据以便Odoo加载它们到数据库中。
模块可以拥有作为默认或者用来示范展示的数据,数据表示允许添加那些数据到我们的模块中。另外,理解Odoo的数据表示格式对于导入或者导出业务环境中的数据是非常重要的
首先,让我们来了解下Odoo数据展示中最为关键的部分——外部id的概念
理解外部id
人们用自己可以理解的字符串标识符来表示的Odoo中的记录,这个标识符确保了记录的唯一性.这个字符串标识符就是外部id(external identifier)或者称为XML ID.
这么做的原因主要是:
- 当我们更新我们的模块时,会重新加载定义在其中的XML,CSV数据文件,为了避免在数据库中创建新的重复数据,我们使用外部id来进行监测,若原来的数据库中已有这个外部id,就只对其做更新。
- 另一个原因是为了支持那些互相关联的数据,数据记录必须能被另外的数据记录关联到。当一个模块被安装时,底层的实际操作是用自动连续生成的数字id来标识不同的数据库,这些数字id不方便我们记忆。通过外部id,我们可以直接与数据库中的记录关联起来,不需要事先知道那些记录的具体id值。可以把外部id理解为一个中间表
-
ir.model.data就是这张中间表,它记录了外部id与实际数据库id之间的映射关系 - Setting | Technical | External Identifiers 这里面就存放了
ir.model.data这个表。里面存放着已经存在的映射关系。通过在里面搜索我们的'todo_app'
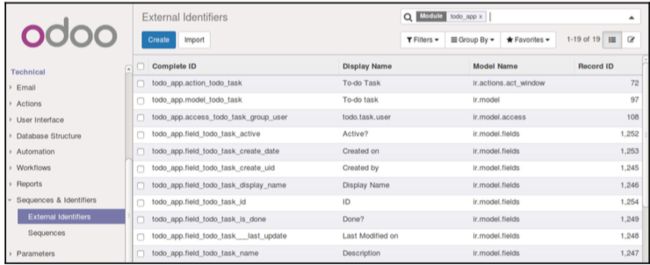
- 我们发现图中有外部id的完整id(Complete ID)的存在,它的生成策略:使用
'.'作为分隔符,以模块的包名为开头。后面为我们定义的id的值。例:todo_app.action_todo_task
所以只要在单独模块中保持外部id的唯一性即可,不同模块因为包名不同是不会有重复风险的。 - 在数据文件中使用外部id来调用记录时,我们
能够选择完整外部id跟普通外部id。同一个模块的记录我们只需要使用普通外部id,当使用不同模块的记录时就需要使用网站外部id。
查看外部id
当我们准备模块的默认及演示数据时,通常需要知道它们的外部id来进行关联。我们可以通过启动开发者模式开更加快速的查看它们的外部id
作为演示:
我们打开Setting | Users 点击‘Demo’用户,在新出来的表单右上角点击开发者菜单(一个小爬虫样子).选择View Metadata.就可以看到'Demo'用户的外部id信息.

如果是tree,form等view视图,可以先选择 Edit

导出导入数据
我们下面来详细的说下如何在用户界面导出导入数据。
导出数据
在列表(list)视图中,导出数据是一个基本功能。

- 从Odoo9开始,我们可以导出符合当前过滤条件的所有数据而不是只是当前显示的数据,这十分有利于导出无法全部现在在当屏幕庞大的记录集合。
点击Export 选项会跳出一个对话表单,我们可以在表单中选择需要导出的数据字段。Import-Compatible Export 选项让我们能够重新利用数据文件导入数据到Odoo。

导出数据的格式可以是CSV或者Excel文件,我们选择CSV,这更利于理解导出数据的格式。接下来,选择我们需要导出的字段,点击 Export To File 就可以进行导出数据的下载。
打开下载下来的CSV文件,里面的记录如下:
"id","name","user_id/id","date_deadline","is_done"
"todo_user.todo_task_a","install Odoo","base.user_root","2017-02-01","False"
"todo_user.todo_task_b","Create dev database","base.user_root","","False"
- 注意到Odoo导出时会自动添加一个’id‘列。这个id列就是每条记录的外部id。如果外部id为None。会生成一个
__export__来代替实际的模块名。
导入数据
首先我们要确保导入数据功能开启,在Odoo9之后,这个功能是默认开启的。开启方法 Settings |General Settings| Import / Export 勾选Allow users to import data from CSV/XLS/XLSX/ODS files即可。
-
这个功能的实际提供是由 Initial Setup Tools(技术名称为
base_setup)包实现的.
所以上面勾选的 Allow users..的实际就是安装了base_setup。
我们首先编辑我们需要导入的CSV文件的数据格式。还是使用刚才下载的CSV文件,我们添加一些新的数据,保持‘id’这一列为空。
csv文件中:-
id作为外部ID是用来检测记录是否已经在Odoo中存在,避免添加重复的记录.在我们的例子中,保持空白即可
-
添加两条数据到我们刚下载的csv文件中.
,"test1","base.user_root","","False"
,"test2","base.user_root","2017-9-28","False"
点击 Import 按钮。选择我们的csv文件。会显示出我们新添加的记录,点击 Validate 按钮进行数据验证,无误后点击 Import 即可导入。

csv文件中的关联记录
在前面的例子中,我们发现每个task的负责人user_id/id都是选用base.user_root的用户,即管理员‘administrator'。这个字段其实是个多对一的关系(外键)。base.user_root代表了管理员的外部id.
- 使用数据库id只在导入/导出同一个数据库时可以使用,通常来说,我们都是使用外部id来定义关联记录的
关联列使用/ id 表示添加外部id标识符,使用/.id表示数据库id标识符. (这里也可以使用:来代替/)
相似的,多对多关系也是被支持的,一个很好的例子就是用户跟用户组:
- 每个用户能够在多个用户组中,一个用户组也能包含多个用户,这里的列就需要使用
/id来添加,说明字段接受外部id作为标识符来引用对应的记录. - example: 在我们的to-do task 关注者中,有一个’to-do tasks‘跟‘partner’的多对多关系,我们的列名应该定义为
follower_ids/id,添加字段值时如下
"__export__.res_partner_1,__export__.res_partner_2"
- 最后,对于一对多关系,可以看做是多对一关系的反转.我们可以从公司(company)模型中找到这样的例子:每个公司有多个银行账户(one2many),相对而言,多个银行账户只属于同一个公司(many2one).
在我们导入公司数据时,就可以通过额外的csv文件来添加多个银行账户- 下面就是一个公司拥有三个银行账户的例子:
id,name,bank_ids/id,bank_ids/acc_number,bank_ids/state
base.main_company,YourCompany,__export__.res_partner_bank_4,123456789,bank
,,__export__.res_partner_bank_5,135792468,bank
,,__export__.res_partner_bank_6,1122334455,bank
- 从上面的代码中,首先前面2列,‘id’跟‘name’指定了我们的公司(记录头),后面的3列都以
bank_ids/为前缀。我们的3条新增记录都有各自的数据.第一条记录有公司和第一家银行的记录,后面2条记录只有额外的公司跟银行的记录.
从GUI界面导入导出数据是非常有必要的。在新创建的Odoo实例设置数据或者为Odoo模块准备数据文件十分有用。接下来,我们要学习跟多的关于数据文件在模块中的使用。
模块数据
模块的参数设置功能通常通过加载默认数据跟演示数据来实现。我们通常使用CSV跟XML文件来进行这样的操作,其实YAML文件也是能够被Odoo所使用的,但是我们很少用。
CSV文件在模块数据中的使用跟我们以前引入新功能的操作是一样的。唯一的限制就是csv的文件名必须与模型的名字一样。
一个很常见的方法就是使用csv文件来设置访问安全定义,通过把csv加载到'ir.model.access'这个模型中.因此,我们通常把这样的csv文件名字定义为
'ir.model.access.csv'.
演示数据
演示数据对于模块案例展示,模块数据库测试来说是十分有用的。
我们通常需要把演示数据声明在__manifest__.py中的demo属性里.就像data属性,这是一个放置演示数据文件路径的列表.
为我们的todo_user模块添加演示数据。我们把需要添加的演示数据放在data子文件夹中.创建data/todo.task.csv.代码如下
id,name,user_id/id,date_deadline
todo_task_a,"install Odoo","base.user_root","2017-02-01"
todo_task_b,"Create dev database","base.user_root",""
然后添加该csv文件路径到__manifest__.py的demo属性中
'demo':['data/todo.task.csv'],
下次我们更新模块时,csv文件中的数据就作为演示数据被添加到我们的模块中.
XML文件也可以从来加载模块数据.接下来我们来学习一些CSV数据文件无法实现而XML数据文件可以做到的事.
XML数据文件
XML比CSV在加载数据的过程中具有更加有力的控制。xml的命名不需要专门匹配模型名称因为xml的格式更加丰富,数据信息都是保存在xml元素中的。
我们在前面的章节已经使用过xml数据文件。用户界面组件,像视图跟菜单名称,实际上都是存储在系统模型中的记录。xml文件在模块中的作用就是用来加载这些记录到服务器中。
我们在‘todo_user'中添加第二个数据文件,'data/todo_data.xml'.加入下面的内容:
Reinstall Odoo
2017-08-05
这个xml文件与前面的csv文件的作用是一样的。添加一条名为’Reinstall Odoo‘的task记录。
- XML数据文件以
为顶部元素,在 中可以有多个 元素用来添加数据记录。 元素有2个必要的属性: model:关联的模型
id:记录的外部id
中我无法使用"user_id/id"这样的格式,而是通过"ref"这个属性来写入关联记录的外部id.
数据的noupdate属性
当数据被重复加载时,记录会被后一次的加载数据所覆盖,这就意味着每次更新模块,我们以前在数据库中进行的手工设置都可能被覆盖掉。尤其当我们自己定制了视图后,一次模块更新可能会丢失所有定制数据。正确的方法应该是通过继承来扩展我们的视图。
这个重新导入的操作是默认的,但是我们可以对它进行改变,我们可以在数据文件中对
或者元素加入noupdate="1"这个属性.这个属性意味着我们数据文件中的记录只在模块安装时被创建,当模块更新时不会对这些记录产生任何影响.
在xml中定义记录
每个
'id':代表了记录的外部id
'model':代表了我们需要创建记录的目标模型
'
设置字段的值
name属性定义了需要被赋值的字段.要根据具体的字段类型来赋值.如果字段是日期,可以使用"YYYY-mm-dd"这样的格式,如果是布尔类型,任何非空的都会被认为是True。而"0"跟"False"则会被转换为False
通过表达式设置字段值
可以使用eval这个属性定义Python表达式来进行赋值.
对于日期处理来说,下面的模块是可以被使用的:time, datetime,timedelta,relativedelta.它们允许你计算日期的值,它们在演示或者测试数据时被频繁的使用。举例来说,把日期改为昨天,我们可以这样写代码:
在eval表达式中,ref()函数是同样可以被使用的,这通常被用来把一个外部id转换为关联的数据库id.这在为关系型字段设置值时是非常有用的.举例来说,我们可以为user_id赋值:
为关系型字段赋值
在上面的代码中我们通过ref()函数来为'many2one'的关系型字段赋值,其实我们在
对于‘one2many’和‘many2many’字段,有时候我们需要一个外部id的list列表。所以Odoo提供给我们一个特殊的表达式来进行这种类型字段的赋值。
我们来看下一个来自Odoo官方的app实例,为tag_ids字段提供了一个关系型记录的list列表
为了填入一个一对多字段,我们使用了一个有3个元组的list列表。下面是刚才代码中每个元组命令的使用解释:
- (0, _, { 'field' : value}):创建了一个新的记录,并与其关联
- (1, id, { 'field' : value}):更新一个已经关联的记录
- (2, id,_): 解除并删除一条相关记录
- (3, id, _):解除但不删除一条相关记录
- (4, id, _): 关联一个已经存在的记录
- (5, _, _): 解除但不删除所有已经关联的记录
- (6,_,[ids]): 使用提供的数据list列表来代替已经关联的数据
上面的元组命令中的下划线可以用0或者False来填充。
常用模型的缩写形式
在我们的第二章中,会发现在xml 文件中有很多于
: 窗口动作模型,ir.actions.act_window : 报告动作模型,ir.actions.report.xml - : Qweb模板储存模型,ir.ui.view
:URL动作模型,ir.actions.act_url
其他xml数据文件动作
删除记录
直接使用外部id:
触发方法跟工作流
一个xml文件还能够执行方法当它加载
- 上面的代码用来执行’crm.lead‘模型只不过的’action_set_lost'方法。通过eval属性传入2个参数,第一个参数是需要起作用的IDs列表,另一个是我们要用的上下文环境。
另一个xml数据文件执行动作的方法是通过
这个模型中,‘ref’属性标识了我们需要执行工作流实例,‘action’是一个传入工作流实例的信号。