本文第一部分将讲解如何在计算机上实现通用的矩阵乘法(General matrix multiply, GEMM),第二部分讲解神经网络加速包NNPACK基于NEON指令实现的矩阵乘法。
这是文章的第一部分。阅读后读者应能了解计算机算矩阵乘法与我们自己笔算有何不同,如何根据这些不同来设计最基本的矩阵乘法算法,并扩展成具有标准接口的函数,以及设计算法时值得注意之处。错漏之处欢迎指正。
1. 在计算机上实现矩阵乘法

首先回忆一下我们怎么笔算两个矩阵相乘。假设我们有一个8x12的A矩阵,一个12x16的矩阵B,他俩相乘,得到8x16的矩阵C。我们会遍历C矩阵的每一个位置,比如当我们想求C(3,4)这个位置的值,如上图所示,应该取A矩阵的第3行和B矩阵的第4列,求这两个向量的内积,也就是把他俩各自的12个元素两两相乘然后相加:
C[2][3] = 0;
for (int k = 0; k < 12; k++) {
C[2][3] += A[2][k] * B[k][3]
}
整个矩阵相乘即是:
memset(C, 0, 8 * 16 * sizeof(float));
for (int i = 0; i < 8; i++) {
for (int j = 0; j < 16; j++) {
for (int k = 0; k < 12; k++) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
这就是我们熟知的最普通但也最万能的公式了。如果这活交给计算机来做,跟我们笔算有什么不一样?
1.1 SIMD指令
现在不少CPU采用了单指令多数据技术(SIMD),一次可以对128位二进制数据做一个相同操作。这就是说,过去我们的代码,比如C[i][j] += A[i][k] * B[k][j];,每次运算只操作一个32位的数据(float);但现在用上SIMD技术,比如ARM芯片的NEON指令:
float32x4_t v1 = (float32x4_t) { 0.0f, 1.0f, 2.0f, 3.0f};
float32x4_t v2 = (float32x4_t) {-0.0f, -1.0f, -2.0f, -3.0f};
float32x4_t v3 = vaddq_f32(v1, v2); // v3 = { 0.0f, 0.0f, 0.0f, 0.0f}
float32x4_t v4 = vmulq_f32(v1, v2); // v4 = { 0.0f, -1.0f, -4.0f, -9.0f}
float32x4_t就是一个由4个32位的float组成的数据类型,对它做一次操作,4个float都被用到。vaddq_f32函数让CPU只需要1次运算,就能算出v1和v2的4个对应元素相加的结果,然后存到v3里;vmulq_f32函数同样只需要1次运算,就能得到v1和v2对应元素相乘的结果。
1.2 多线程并行计算
矩阵乘法有一个特点:对于8x16的C矩阵,假设我们有8x16个人,他们每个人负责算C矩阵一个元素的值,那么他们的任务将是相互独立、互不影响的,因为他们只需要在同一块内存上取数据,然后各自算各自的,算完了再写到不同位置上去。有些人算得快,有些算得慢;有些马上开始算,有些睡了一天才开始。但这些都不会影响最终结果的正确性,毕竟有独立性。
现在把人换成CPU的核。假设它有8x16个核,每个核各跑1个线程,就可以让每个线程负责算C矩阵的一个元素;假设它只有2个核、2个线程,那么每个线程负责算4x16个元素,或者让一个线程只算1个元素、另一个线程算8x16-1个元素,最后的结果都是对的。至于算得快不快,就看线程池任务调度合理不合理了。
总之,计算机可以并行地算矩阵乘法。于CPU而言,可以在它的每一个核上创建一个线程,哪个线程闲着就给它派个独立的小任务,所有小任务做完了矩阵乘法也就算好了。如果是GPU,它可能有成百上千个核,那更得把任务拆散了派发下去。
1.3 算法怎么实现
请牢记,当我们在计算机上做矩阵乘法的时候,一是可以用SIMD指令(比如ARM芯片的NEON),在同样的时间内多算几个数;二是可以在多核心的CPU上用多个线程并行计算,当然用GPU就更棒了。接下来就看算法怎么写。
因为NEON指令集其他函数没有那么顾名思义,后文中我们将沿用其数据类型float32x4_t,但不再直接用其函数名。现在定义以下顾名思义的函数:
float32x4_t vget(float *src);
float32x4_t vdup(float num);
void write(float *dst, float32x4_t vec);
float32x4_t vadd(float32x4_t v1, float32x4_t v2);
float32x4_t vmul(float32x4_t v1, float32x4_t v2);
void svv_mul_add(float32x4_t v0, float32x4_t v1, float32x4_t v2, float s1);
void vvv_mul_add(float32x4_t v0, float32x4_t v1, float32x4_t v2, float32x4_t v3);
-
vget函数:从地址src那里取4个float,组成一个float32x4_t并返回 -
vdup函数:直接输入一个float,把它复制粘贴4次,组成一个float32x4_t并返回 -
write函数:把一个float32x4_t写到地址dst去,相当于一次写入4个float -
vadd和vmul函数:两个函数分别返回v1、v2对应元素相加、相乘的结果 -
svv_mul_add函数:取float32x4_t型的v1、v2和float型的s1,然后让v1的每一个元素都乘上s1,将其结果与v2对应位置的元素相加,写到同为float32x4_t 型的v0 -
vvv_mul_add函数:取float32x4_t型的v1、v2和v3,然后让v1和v2每一个对应元素相乘,再与v3的每一个对应元素相加,写到同为float32x4_t 型的v0
(以上函数对应的NEON指令分别是vld1q_f32、vdupq_n_f32、vst1q_f32、vaddq_f32、vmulq_f32、vfmaq_lane_f32和vfmaq_f32;在其他指令集中应该也有对应的函数)

如上图所示,如果我们要求C(1,5)到C(1,8)这4个点的值,就不再需要4x12个循环,而只需要12个。第一种写法如下:
float32x4_t ret = vdup(0.0f);
for (int k = 0; k < 12; k++) {
svv_mul_add(ret, A[0][k], vget(&B[k][4]), ret);
}
write(ret, &C[0][4]);
同样也可以用vvv_mul_add函数:
float32x4_t ret = vdup(0.0f);
for (int k = 0; k < 12; k++) {
vvv_mul_add(ret, vdup(A[0][k]), vget(&B[k][4]), ret);
}
write(ret, &C[0][4]);
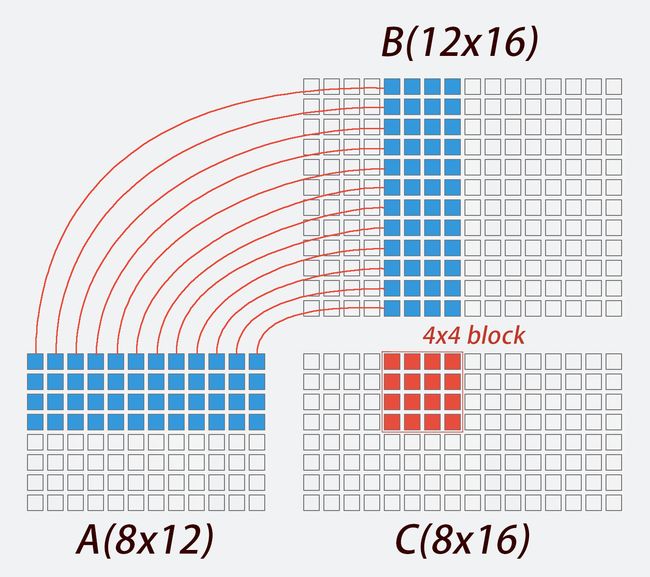
这样我们需要for循环执行的次数就变成原来的1/4。不过,试想接下来如果我们要求C(2,5)到C(2,8)这4个点的值,就又需要一个for循环,重新取一遍B矩阵第5到第8列的所有值,与A矩阵第二列相乘。这个取值也是有时间成本的,应当尽量避免。那我们不妨这样:
float32x4_t vc0 = vdup(0.0f);
float32x4_t vc1 = vdup(0.0f);
float32x4_t vc2 = vdup(0.0f);
float32x4_t vc3 = vdup(0.0f);
for (int k = 0; k < 12; k++) {
float32x4_t vb = vget(&B[k][4]);
vvv_mul_add(vc0, vdup(A[0][k]), vb, vc0);
vvv_mul_add(vc1, vdup(A[1][k]), vb, vc1);
vvv_mul_add(vc2, vdup(A[2][k]), vb, vc2);
vvv_mul_add(vc3, vdup(A[3][k]), vb, vc3);
}
write(vc0, &C[0][4]);
write(vc1, &C[1][4]);
write(vc2, &C[2][4]);
write(vc3, &C[3][4]);
改写后的代码,for循环会取遍A矩阵第1到第4行、B矩阵第5到第8列的所有值,算出C矩阵红色区域内的16的元素。后文中我会把这样的情况叫做每次算出C矩阵一个4x4的块(block)。这样改写并不会减少乘法和加法的计算次数,但能把对B矩阵取值的次数减少到原来的1/4,因为每次取出来的值都被用了4次。
是不是取A矩阵取得越多列越好呢?如果每次取8列,对B矩阵的取值次数不就只有原来的1/8了吗?每次取10000列不就……同样地,如果B矩阵每次取8列,不就可以把对A矩阵取值的次数减到原来的1/2了吗?每次取10000……
这样想确实没什么大毛病。我也试过,每次算一个8x8的块确实比算4x4更快。不过我们现在举的例子都是比较简单的情况,即A矩阵的行数、B矩阵的列数都是4或者8的整数倍,如果是更一般的情况,即不是整数倍、存在余数,或者干脆小于4或8,这些部分处理起来是很麻烦的,需要大量的判断语句(if...else, switch...case),这也是会耗时间的,可能得不偿失。
如果块取得太大,比如取到了16x16,那么A矩阵的行数、B矩阵的列数就各有15/16的几率不是16的整数倍。如果计算两个17x17的方阵相乘,C矩阵将被划分成4个块(尺寸分别是16x16,16x1,1x16和1x1);只有其中1个块满16x16,可以用类似上面的很简洁的代码算出来;计算另外3个块(占75%)都需要大量的判断语句,确保取值和赋值不会过界,这就造成大量时间浪费。但如果取的是4x4的块,C矩阵被划分成25个块,只有其中9个块不满4x4(占36%)需要判断语句。
还有一种处理方式就是补0。如果使用了16x16的块,就用0来把A矩阵的行数、B矩阵的列数补成16的整数倍。最后算出来的C矩阵周围有半圈的0,保证其行数、列数都是16的倍数,于是还需要去掉这些0。这样倒是不需要大量的判断语句了,但这来回来去的倒腾也是很耗时间的。
所以最合适的块的大小究竟是多少,应该通过测试来找,还要参考实际的业务需求。
1.4 扩展成标准接口
至此,算法的轮廓已经隐约可见了:
- 确定每次算C矩阵一个多大的块
- 把计算每一块作为一个小任务,通过线程池分发任务
- 等待所有小任务执行完毕即可
需要注意的一个是选择多大的块,一个是处理边缘上那些不满的块,取值、赋值的时候都要判断是否超出范围。这样就可以完成一个最基本的C = A * B的算法。
很多矩阵运算库定义的矩阵乘法是这样的:
gemm(const CBLAS_TRANSPOSE TransA,
const CBLAS_TRANSPOSE TransB,
const int M,
const int N,
const int K,
const float alpha,
const float *A,
const float *B,
const float beta,
float *C);
它们计算的是这样的式子:
C = alpha * op(A) * op(B) + beta * C
op的意思是相乘之前可以要求先对这个矩阵转置,也就是调用gemm函数时前两个参数可以是trans或者noTrans;alpha和beta是两个常数,也就是要求矩阵的每个元素都要乘上一个常数。
再看我们的算法,如果要求考虑A、B矩阵事先转置的情况,就得修改取值的代码。比如原来对B矩阵的取值是连续取4个值:
float32x4_t vb = vget(&B[k][4]);
当要求B矩阵转置的时候,就得这样:
float32x4_t vb = (float32x4_t) {B[k+0][4], B[k+1][4], B[k+2][4], B[k+3][4]};
不连续取值可能会降低效率,或许在某些情况下还不如用别的代码,比如iOS可以用vDsp_mTrans,先把B矩阵转置一下,再像从前一样连续取值。
另外我们原来的赋值语句是这样写的:
write(vc0, &C[0][4]);
write(vc1, &C[1][4]);
write(vc2, &C[2][4]);
write(vc3, &C[3][4]);
考虑alpha和beta时,需要改写成:
float32x4_t valpha = vdup(alpha);
float32x4_t vbeta = vdup(beta);
write(vadd(vmul(vc0, valpha), vmul(vget(&C[0][4]), vbeta)), &C[0][4]);
write(vadd(vmul(vc1, valpha), vmul(vget(&C[1][4]), vbeta)), &C[1][4]);
write(vadd(vmul(vc2, valpha), vmul(vget(&C[2][4]), vbeta)), &C[2][4]);
write(vadd(vmul(vc3, valpha), vmul(vget(&C[3][4]), vbeta)), &C[3][4]);
经过这些修改,即可获得一个具有标准接口的gemm函数。