Double DQN原理
DQN本质上仍然是Q-learning,只是利用了神经网络表示动作值函数,并利用了经验回放和单独设立目标网络这两个技巧。DQN无法克服Q-learning 本身所固有的缺点——过估计。过估计是指估计的值函数比真实值函数要大。一般来说,Q-learning之所以存在过估计的问题,根源在于Q-learning中的最大化操作。
Max操作使得估计的值函数比值函数的真实值大。如果值函数每一点的值都被过估计了相同的幅度,即过估计量是均匀的,那么由于最优策略是贪婪策略,即找到最大的值函数所对应的动作,这时候最优策略是保持不变的。也就是说,在这种情况下,即使值函数被过估计了,也不影响最优的策略。强化学习的目标是找到最优的策略,而不是要得到值函数,所以这时候就算是值函数被过估计了,最终也不影响我们解决问题。然而,在实际情况中,过估计量并非是均匀的,因此值函数的过估计会影响最终的策略决策,从而导致最终的策略并非最优,而只是次优。
为了解决值函数过估计的问题,Double Q-learning 将动作的选择和动作的评估分别用不同的值函数来实现。
Paper:
DDQN:Deep Reinforcement Learning with Double Q-learning
Github:https://github.com/xiaochus/Deep-Reinforcement-Learning-Practice
环境
- Python 3.6
- Tensorflow-gpu 1.8.0
- Keras 2.2.2
- Gym 0.10.8
算法实现
Double DQN和Nature DQN的区别仅仅在于目标Q值的计算。
在之前的文章中,Nature DQN中的target_Q是这样计算的:
y = self.model.predict(states)
q = self.target_model.predict(next_states)
for i, (_, action, reward, _, done) in enumerate(data):
target = reward
if not done:
target += self.gamma * np.amax(q[i])
y[i][action] = target
在Double DQN中,target_Q是这样计算的:
y = self.model.predict(states)
q = self.target_model.predict(next_states)
next_action = np.argmax(self.model.predict(next_states), axis=1)
for i, (_, action, reward, _, done) in enumerate(data):
target = reward
if not done:
target += self.gamma * q[i][next_action[i]]
y[i][action] = target
两者的区别在于,在对next时刻的Q值进行选取时,不在使用最大值,而是使用主网络预测出来的next_action进行选取,除此之外算法其余部分完全一样。
完整代码:
# -*- coding: utf-8 -*-
import os
import random
import numpy as np
from DQN import DQN
class DDQN(DQN):
"""Nature Deep Q-Learning.
"""
def __init__(self):
super(DDQN, self).__init__()
self.model = self.build_model()
self.target_model = self.build_model()
self.update_target_model()
if os.path.exists('model/ddqn.h5'):
self.model.load_weights('model/ddqn.h5')
def update_target_model(self):
"""update target_model
"""
self.target_model.set_weights(self.model.get_weights())
def process_batch(self, batch):
"""process batch data
Arguments:
batch: batch size
Returns:
X: states
y: [Q_value1, Q_value2]
"""
# ranchom choice batch data from experience replay.
data = random.sample(self.memory_buffer, batch)
# Q_target。
states = np.array([d[0] for d in data])
next_states = np.array([d[3] for d in data])
y = self.model.predict(states)
q = self.target_model.predict(next_states)
next_action = np.argmax(self.model.predict(next_states), axis=1)
for i, (_, action, reward, _, done) in enumerate(data):
target = reward
if not done:
target += self.gamma * q[i][next_action[i]]
y[i][action] = target
return states, y
def train(self, episode, batch):
"""training
Arguments:
episode: game episode
batch: batch size
Returns:
history: training history
"""
history = {'episode': [], 'Episode_reward': [], 'Loss': []}
count = 0
for i in range(episode):
observation = self.env.reset()
reward_sum = 0
loss = np.infty
done = False
while not done:
# chocie action from ε-greedy.
x = observation.reshape(-1, 4)
action = self.egreedy_action(x)
observation, reward, done, _ = self.env.step(action)
# add data to experience replay.
reward_sum += reward
self.remember(x[0], action, reward, observation, done)
if len(self.memory_buffer) > batch:
X, y = self.process_batch(batch)
loss = self.model.train_on_batch(X, y)
count += 1
# reduce epsilon pure batch.
self.update_epsilon()
# update target_model every 20 episode
if count != 0 and count % 20 == 0:
self.update_target_model()
if i % 5 == 0:
history['episode'].append(i)
history['Episode_reward'].append(reward_sum)
history['Loss'].append(loss)
print('Episode: {} | Episode reward: {} | loss: {:.3f} | e:{:.2f}'.format(i, reward_sum, loss, self.epsilon))
self.model.save_weights('model/ddqn.h5')
return history
if __name__ == '__main__':
model = DDQN()
history = model.train(600, 32)
model.save_history(history, 'ddqn.csv')
model.play('dqn')
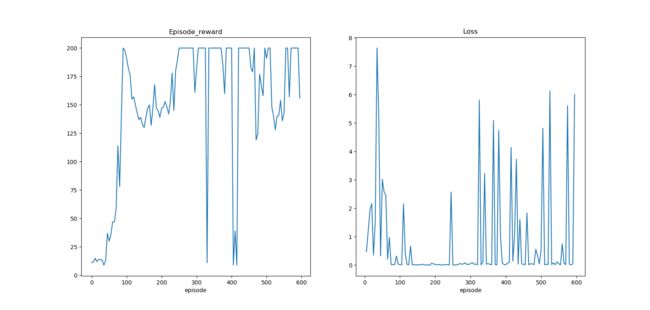
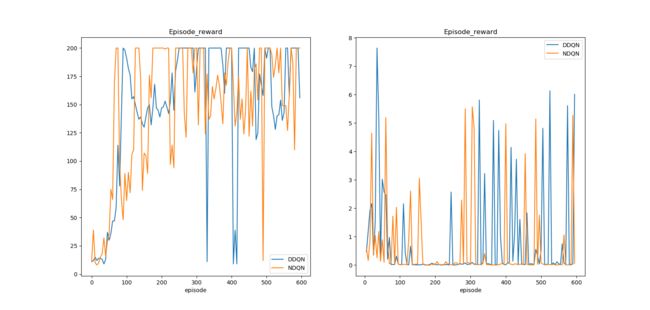
训练与测试结果如下,在使用与DQN同样的参数的情况下,可以看出Double DQN收敛的更好,在每次测试中都能够拿到200的分数。
Episode: 550 | Episode reward: 143.0 | loss: 0.052 | e:0.01
Episode: 555 | Episode reward: 200.0 | loss: 0.010 | e:0.01
Episode: 560 | Episode reward: 200.0 | loss: 0.750 | e:0.01
Episode: 565 | Episode reward: 157.0 | loss: 0.067 | e:0.01
Episode: 570 | Episode reward: 200.0 | loss: 0.018 | e:0.01
Episode: 575 | Episode reward: 200.0 | loss: 5.615 | e:0.01
Episode: 580 | Episode reward: 200.0 | loss: 0.035 | e:0.01
Episode: 585 | Episode reward: 200.0 | loss: 0.011 | e:0.01
Episode: 590 | Episode reward: 200.0 | loss: 0.041 | e:0.01
Episode: 595 | Episode reward: 156.0 | loss: 6.012 | e:0.01
play...
Reward for this episode was: 200.0
Reward for this episode was: 200.0
Reward for this episode was: 200.0
Reward for this episode was: 200.0
Reward for this episode was: 200.0
Reward for this episode was: 200.0
Reward for this episode was: 200.0
Reward for this episode was: 200.0
Reward for this episode was: 200.0
Reward for this episode was: 200.0