Flink容错机制以及Chandy-Lamport算法
流式计算分为有状态和无状态两种情况,所谓状态就是计算过程中的中间值;
对于无状态计算,会独立观察每个独立事件,并根据最后一个事件输出结果:对于一个流式系统接收到一系列的数字,当数字大于N则输出,这时候在此之前的数字的值、和等情况,压根不关心,只和最后这个大于N的数字相关就行;
有状态计算:想求过去一分钟所有数字的和或者平均数等,这种就需要保存中间结果的情况有状态的计算;当分布式计算系统中引入状态计算时,就无可避免一致性问题:若是计算过程中出现流故障,中间数据怎么办?若是不保存,那就只能重新从头计算,不然怎么保证计算结果的正确性;这就需要要求系统具有容错性
一致性
所谓一致性就是,成功处理故障并恢复之后得到的结果与没有发生任何故障得到的结果相比,前者的正确性(故障的发生是否影响得到的结果),分为三个级别:
- at-most-once:至多一次;故障发生之后,计算结果可能丢失,就是无法保证结果的正确性;
- at-least-once:至少一次;计算结果可能大于正确值,但绝不会小于正确值,就是计算程序发生故障后可能多算,但是绝不可能少算;
- exactly-once:有且仅有一次;系统保证发生故障后得到的计算结果和值和正确值一致;
(最重要的分布式一致性问题:拜占庭将军问题,也是当下很火的区块链的核心问题及优化方向)
Flink的容错机制保证流exactly-once,也可以选择at-least-once;Flink的容错机制是通过对数据流不停的做快照(snapshot)实现的;
Chandy-Lamport算法(Flink容错的基石)
- 论文地址 http://lamport.azurewebsites.net/pubs/chandy.pdf
Flink使用了分布式快照算法来保证Exactly-once,而Flink的算法是基于Chandy和Lamport在1985年提出的分布式快照算法(称为Chandy-lamport算法)改进而来的;
Lamport也是著名的拜占庭将军问题的提出者,在分布式计算领域有诸多重要贡献;
Chandy-Lamport算法可以说是Flink实现Exactly-once的重要基石(Spark中的容错机制也是基于Chandy-Lamport)

上图所示的是Chandy与Lamport发布的论文 -> 分布式快照:确定分布式系统的全局状态
全局快照(Global Snapshot):
Global Snapshot我们也可以理解为Global State---全局状态,在系统做Failure Recovery的时候非常有用,也是广泛应用在分布式系统,更多是分布式计算系统中的一种容错处理理论基础;
在Chandy-Lamport算法中,为了定义分布式系统中的全局状态,我们先将分布式系统简化成有限个进程和进程之间的channel组成,也就是一个有向图,节点是进程,边是channel;一个分布式系统的全局状态就是有进程的状态和channel中的message组成,这个也是分布式快照算法需要记录的;
因为是有向图,所以每个进程对应着两个类channel:input channel,output channel;同时假设Channel是一个容量无限大的FIFO队列,收到的message都是有序且无重复的,Chandy-Lamport分布式快照算法通过记录每个进程的local state和它的input channel中有序的message,我们可以认为这是一个局部快照,那么全局快照就是通过将所有的进程的局部快照合并起来得到的;
Chandy-Lamport算法的流程
在论文中分布式系统被简化为两个进程(porcess)上进行的论证

- 进程p与进程q,它们之间数据的交互通过socket channel:c与c';p发送消息通过c到达q,q发送消息通过c'到达p;
- 然后采用了single-token conservation 的模型,在此模型中进程中只有一个token,当进程拥有token状态记为sl,进程未拥有token状态记为s0;

- 首先进程p和q启动,token in p[p:s1 q:s0]
- p发送token去q进程,此时正在socket channel中传输,token in channel[p:s0 q:s0]
- q收到token,token in q[p:s0 q:s1]
- 这个时候q ack回复p,token in channel[p:s0 q:s0]
- p收到回复token in p [p:s1 q:s0]
通过上面的流程,在任意时刻都可以记录下两进程中token的状态,此时再推广到多个进程,多个token基本都是一样
Chandy-Lamport算法具体的流程主要包括下面三个部分
- Initating a snapshot:也就是开始创建snapshot,可以由系统中的任意一个进程发起
- propagating a snapshot:系统中其他进程开始逐个创建snapshot的过程;
- Terminating a snapshot:算法结束条件;
Initating a snapshot:
- 进程Pj发起:记录自己的进程状态,同时生产一个标识信息marker,marker和进程通信的message不同;
- 将marker信息通过output channel发送给系统里面的其他进程;
- 开始记录所有input channel接收到的message;
Propagating a snapshot
- 对于进程Pj从input channel Ckj接收到marker信息;
- 如果Pj还没有记录自己的进程状态,则
- Pj记录自己的进程状态;同时将channel Ckj置为空;
- 向output channel发送marker信息;
- 否则
- 记录其他channel在收到marker之前的channel中收到所有message;
这里的marker其实就充当一个分隔符,分隔进程做local snapshot(记录进程状态)的message;
Terminating a snapshot:
- 所有的进程都收到marker信息并且记录下自己的状态和channel的状态(包含的message)
Chandy-Lamport特点:
- 任何节点的snapshot由本地状态snapshot和节点的input channel snapshot组成;
- 任何src可以任意时间决定take本地状态snapshot,take完本地snapshot,广播一个marker给所有下游;
- 任意没有take本地snapshot的节点,收到第一个marker的时候,take本地状态snapshot,然后给所有output channel广播这个marker;
- 从收到第一个marker并take完本地snapshot之后,记录所有input channel的msg到log里,直到从所有的input channel 都收到这个marker,作为这些input channel的channel snapshot;
Flink 的 Exactly-once一次语义:
Flink实现Exactly-once 采用的是checkpoint,使用的是Asynchronous barrier snapshots算法(ABS算法),该算法正是由Chandy-Lamport Algorithm进行一些轻微的变种而来;
Checkpoint
Flink容错机制的核心就是持续不断的创建分布式数据流和操作算子状态的snapshot,这些快照(snapshot)充当检查点(Checkpoint),系统可以在程序出错失败时将其回滚;受分布式快照的标准Chandy-Lamport算法启发,并针对Flink执行量身定制;
Barriers(栅栏)
Flink分布式快照的核心是stream barriers;这些barriers被插入到数据流中,并作为数据流的一部分和记录一起向下游;Barriers永远不会超过正常数据,数据流严格有序,一个barrier将数据流中的记录分割为进入当前快照的一组记录和进入下一个快照的记录,每个barrier都带有快照ID,并且barrier之前的记录都进入了此快照,Barriers不会中断数据流,所以非常的轻量;多个不同快照的多个barriers可以同时在stream中出现,即多个快照可能同时创建;
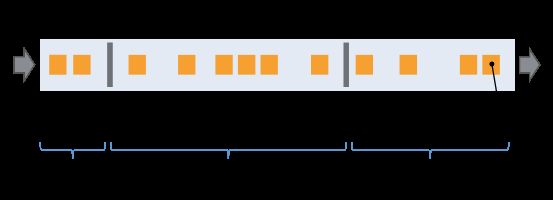
如上图所示,Barriers在Source stream的并行数据流中插入,当snapshot n的barriers 被插入(记作Sn),
Sn点是Source中snapshot覆盖数据的位置,例如在Kafka中,此位置表示某个分区中最后一条数据的偏移量(offset);Sn点被发送给checkpoint coordinator[位于Flink JobManager中];
然后barrier继续移动,当中间算子所在其所有的输入流(input stream)中收到snapshot n的barrier时,会向其所有输出流(outgoing stream)插入snapshot n的barrier;一旦Sink operator(流式DAG的末端)从其所有输入流中接受到barrier n,向check pint coordinator确认snapshot n已经完成,在所有sinks确认之后,该snapshot被认为已完成;
当快照n完成后,由于数据源中先于Sn的数据已经通过了整个拓扑图,我们可以确定不再需要这些数据了---作业将永远不会再向source请求source请求Sn之前的记录;

接收超过输入流的operator需要基于snapshot barrier对齐(align)输入;
当算子从输入流接收到snapshot的barrier n,就不能继续处理此数据流的后续数据,知道其接收到其余流的barrier n为止,否则会将属于snapshot n 和 snapshot n+1的数据混淆;
接收到barrier n的流的数据会被放在一个input buffer中,暂时不会处理;
当从最后一个流中接收到barrier n 时,算子会emit所有暂存在buffer中的数据,然后自己向下游发送Snapshot n;
最后算子恢复所有输入流数据的处理,优先处理缓存中的数据
恢复
Flink恢复机制十分直接:在系统失效时,Flink选择最近的已经完成的检查点,系统接下来重部署整个数据流图,然后给每个Operator在检查点k时的相应状态,数据源则被设置为从数据流的Sk位置开始读取;例如,在Kafka执行恢复时,系统会通知消费者从偏移量开始获取数据;
先决条件:
- 持续的数据源,比如消息队列或文件系统;
- 状态存储的持久化,通常是分布式文件系统(如HDFS,S3,GFS)
State Backends:
流计算中以下场景中需要保存状态;
- 窗口操作;
- 使用了KV操作;
- 继承了C和CheckpointedFunction的函数;
当检查点(checkpoint)机制启动时,状态将在checkpoint中持久化来应对数据丢失以及恢复;
而状态在内部是如何表示的,状态是如何持久化到检查点中以及持久化到哪里都取决于选定的State Backend;
Flink在保存状态时,支持3种存储方式:
- MemoryStateBackend(如果没有配置其他内容,系统默认将使用MemoryStateBackend)
- FsStateBackend
- RocksDBStateBackend
Savepoint 保存点
Flink的Savepoints与Checkpoints的不同之处在于备份与传统数据库中的恢复日志不同;checkpoint的主要目的是在job意外失败时提供恢复机制;checkpoint的生命周期由Flink管理;即Flink创建,拥有发布Checkpoint----无需用户交互;
Checkpoint:
- 轻量级;
- 尽可能快地恢复;
与此相反,Savepoints由用户创建,拥有和删除;他们一般是有计划的进行手动备份和恢复;他们一般是有计划的进行手动备份和恢复;例如,Flink版本需要更新的时候,或者更改你的流处理逻辑,更改并行性等等;在这种情况下,我们往往关闭一下流,这就需要我们将流中的状态进行存储,后面重新部署job的时候进行恢复;
从概念上讲,Savepoints的生成和恢复成本可能更高;并且更多地关注可移植性和对前面提到的作业更改的支持;
参考文献
[1]. Distributed Snapshots: Determining Global States of Distributed Systems.
[2]. Apache Flink Documentation
[3]. 分布式快照算法: Chandy-Lamport 算法