作者:药丸
成文于2018年11月29日
写在前面
本文内容为SLAM的一篇经典综述文章「Simultaneous Localization and Mapping(SLAM) : Part 1」的学习笔记。这篇综述著于2006年,是SLAM领域的经典入门综述。该笔记是博主对这篇文章的个人理解。由于博主水平有限,估计文中有不少错误,希望高手能够指出。笔者的主要目的是对SLAM的很多基础概念做一入门的了解。限于笔者自身水平有限,很多地方可能理解的不对,想学习的同学建议大家还是直接去看原文。
概念
loop closure: 确定飞行器已返回之前访问过的位置的的问题。
joint posterior distribution:联合后验分布
conditionally independent:在概率论中,如果R的出现和B的出现在给定Y的条件概率分布中是独立事件,则两个事件R和B在给定第三事件Y的情况下是条件独立的。
landmarks:顾名思义就是标志物,即场景中比较有辨识度的物体或者区域。
consistent map:完全地图,是指不受障碍行进到房间可进入的每个角落的地图。
Data Association:数据关联,也被称为一致性问题(Correspondence Problem),数据关联是指建立在不同时间、不同地点获得的数据之间的对应关系,以确定它们是否源于环境中同一物理实体的过程。
SLAM问题的历史
SLAM问题是这样的:一个在未知位置和未知环境中移动的机器人能否在建立环境地图的同时确定他自身的位置。
从概念以及理论上来看,现在SLAM问题已经解决了,然而在实现更加普遍的SLAM问题以及建立更丰富的地图时,仍然有很多亟待解决的问题。
probabilistic SLAM问题第一次在1986年提出,这是一个概率学方法刚刚开始被引入到机器人学和人工智能学的年代,有很多的研究者想要将估计理论方法应用到SLAM问题中。
一年后,Smith and Cheesman and Durrant-Whyte将统计贝叶斯用在了描述 landmarks 和 几何不确定性之间的关系上。这项工作的一个核心是显示了对不同的Landmarks位置的估计之间必然存在高度的相关性,并且这种相关性会随着观测的增加而增加。
在同一时期,Ayache and Faugeras进行了早期的视觉导航的研究。而Crowley and Chatila and Laumond用卡尔曼滤波完成了基于声呐的移动机器人导航。这两个研究有很多的相同之处,并启发Smith完成了一篇关于landmarks的文章,这篇文章揭示了当一个在陌生环境中移动的机器人对landmarks进行相对的估计时,这些landmarks一定都是互相相关的,这是因为在估计机器人的位置时的误差都是相似的。这项研究揭示了一个深刻的道理:一个对SLAM问题的完全解需要一对组合量:机器人的姿态以及每个landmarks的位置。而这就意味着我们需要估计一个巨长的状态向量(大概和地图中的landmarks数量一样多),并且还要进行landmarks数量的平方()数量级的运算。
很重要的一点是,这项工作不关注整个地图绘制过程的收敛特性或其稳态行为。因为当时大家都假设地图估计的误差不会收敛,并且会无限地增长。相比于给定mapping问题的计算复杂度而不知道整个mapping收不收敛的问题,研究者们将重心更多地放在了对完全地图问题的一系列估计上。在研究过程中,大家为了避免对整个系统进行滤波,假设Landmarks之间的相关性是很小的来对landmarks之间进行解耦。也因为这个原因,大家将mapping问题和定位问题割裂开来了,SLAM问题的理论工作进入了瓶颈。
随着人们对SLAM问题理解的逐渐加深,一个突破性的进展出现了。人们逐渐认识到如果他们将SLAM问题看做一个估计问题,那么误差将是收敛的。最重要的是,研究者们意识到了他们曾敬而远之的Landmarks之间的相关性是解决SLAM问题的关键,并且这种相关性越强,得到的效果越好。SLAM问题的结构以及「SLAM」这个提法在1995年时在一家移动机器人论文杂志上提出。基本的收敛理论以及最初的结果是Csorba做出来的。
事实上这时候还有一些团队也在研究这个问题,他们管这个问题叫做CML(concurrent mapping and localization),他们在室内、室外和海底都做了相关的研究。
在这一时期,大家主要做一些提高计算效率的研究,并解决在数据相关性和 loop closure 方面的问题。1999年机器人国际国际机器人研究会议是一次重要的会议,在这场会议上,大家第一次进行了针对SLAM问题的讨论,大家讨论了基于卡尔曼滤波的方法和基于概率学方法下SLAM问题的收敛性。
在接下来的日子里,SLAM逐渐吸引了越来越多的实验室投入其中,2000年时ICRA会议有15位研究者搞这个,2002年时已经有了150位研究者,
SLAM问题的结构和表述
SLAM是这样一个过程:一个机器人在建立环境地图的同时也确定自身的位置。在这个问题中,机器人的移动轨迹和所有landmarks的位置都是「在线估计」,即不需要给出任何的边界条件或者初始条件。
SLAM问题表述-图1
下图为最基础的SLAM问题,我们需要机器人和landmark的位置,真实的位置无法被直接测量,观察是相对于机器人和landmarks之间的。
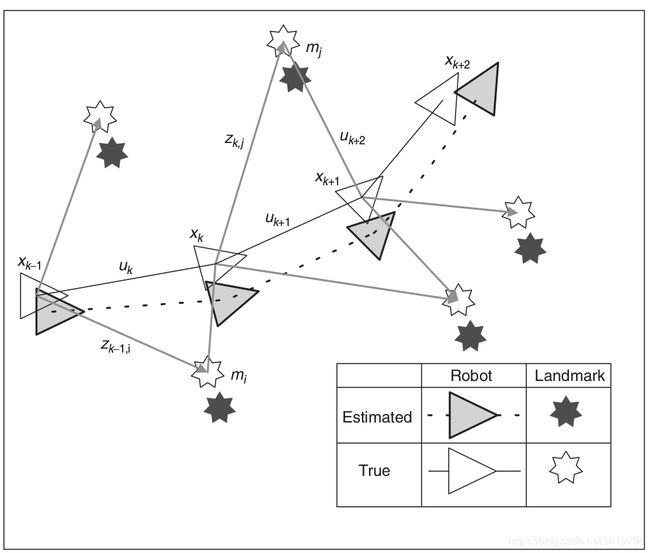
共用的定义
如上图所示,一个小三角在空间中不断地移动,他所搭载的传感器能够测出它和landmarks之间的相对位置关系,在时间点k有如下定义
- :描述飞行器姿态和位置的向量。
- :在k-1时刻施加的控制变量,该控制变量能使得飞行器到达k-1时刻的。
- :一个表示第i个landmark位置的向量,在这里,假设landmark的真实位置不变。
- :在时间点k从飞行器的位置观察landmarks的位置,这些观察将被写为。
- 是飞行器的位置轨迹,是控制输入量的历史量,是所有的landmarks,是所有观察到的landmarks的集合。
基于概率学的SLAM
数学描述
在概率学的形式中,SLAM问题需要所有时刻的下述概率分布:
该概率分布描述了在给定的观察和控制输入情况下,landmark的位置和飞行器在k时刻的状态的联合后验分布密度。通常我们要用递归来解决这个问题。我们从时间k-1时的联合后验分布密度 开始考虑,我们可以通过贝叶斯理论算出控制量和观察量,进而算出这个密度。这种计算需要一个状态转移膜性和一个观察模型来描述控制输入和观察量的影响。
其中观察模型描述了当飞行器的位置和landmarks的位置都已知时,做出观察的概率,我们通常把这个概率写作:
一旦飞行器的位置和地图定义好了,我们很容易就能假设不同时刻的观察之间是条件独立的。。
而一个飞行器的运动模型则可以被描述为状态转换的概率分布。
状态转换在这里被假设为了一个马尔科夫链,这个过程中,下一时刻的状态决定且只决定上一时刻和控制量,并且状态的转换独立于观察和测绘的过程。
SLAM算法现在就可以通过一个标准的两步递归预测相关度(按时间顺序更新,按测量更新)更新的形式:
Time-update:按时间更新
Measurement Update :按测量更新
方程4和方程5提供了计算联合后验分布密度的迭代步骤。值得一提的是地图构建问题可以等效为计算概率密度,这种等效假设飞行器的位置在所有时刻都是已知的,这样我们就可以通过融合不同位置的地图m。反过来看,定位问题也可以被等效为计算概率密度,同样的,为了计算飞行器的位置,这种等效要假设landmark的位置是已知的。
结构描述
从图示中可以看出,在估计位置和landmarks的真实位置之间误差常常会有一些误差。造成这些误差的原因大同小异:他们都来自在观测landmarks时的误差。这也说明了任何两个Landmark之间的位置估计都是高度相关的。特别的,这意味着即使每个landmarks的位置都不太精确,任意两个Landmarks之间的相对位置也可以被估计得很精确。从概率学的角度来讲,这意味着在分布很平坦的情况下,的分布却可能会很尖。
在SLAM领域最重要的洞察之一就是发现了Landmarks估计之间的相关性会随着观察的增加而单调增加。这个结论只在高斯分布下已经被证明了,在其他的概率分布下的证明仍是一个开放性的问题。特别地,这也意味着尽管机器人一直在运动,我们对landmarks之间的相对位置的估计却只会越来越精确,并且这种估计不会发散。这也意味着landmarks的分布密度函数会随着观察的进行越来越尖。
由于机器人所做的每次观察都可以近似为对 landmarks 相对位置的相互独立的估计,考虑有一个机器人正在观察两个 landmarks 和 。所观察到的landmarks之间的相对位置是独立于机器人的体坐标系的,并且从不同的定点观察会得到相互独立的对于landmarks相对关系的估计。随着机器人移动到位置,它再次观察到了,这让对机器人和landmarks的估计能够相对于之前的点进行更新。而这也反过来更新了landmark——即使在k+1时刻我们已经看不到了,但我们仍能对它的位置进行估计。这是因为两个landmarks有很强的相关性(他们之间的相对位置已经被很好地估计了),更进一步地讲,用相同的测量数据来更新landmarks的位置也进一步地增强了他们之间的相关性。
这种准独立的估计方法是很合理的,因为观测误差会随着机器人的运动而被修正,假设在点时,机器人看到了两个新的landmarks,仍在他的视野之内,而已经不在了。这些新的landmarks就会被新的观测互相被联系起来,被构建进整张地图之中。在之后的更新中,如果更新了这两个新的点,那么也会被更新。再进一步去想,由于和之间的相关性,也会反过来被更新。也就是说所有的landmarks在最终会形成一张相互连接的网络,这张网络由各个landmarks的相对位置决定,而网络的准确率会随着观察的进行而不断上升。
SLAM问题图示-图2

如上图所示,这个估计过程可以被可视化为上图——一个弹簧系统,各个节点由不同的弹簧相连接。这些节点是robot和landmarks,而这些弹簧的刚度则是landmarks之间的相关性。对临节点的观察就像对弹簧系统施加一个位移(其实我觉得这更像桁架系统)。
随着机器人在环境中的移动和观察,这个弹簧系统的刚度会单调增加。在极限情况下,我们可以估计出一个刚性的landmarks的地图,也就是说精确的地图。在理论极限中,我们可以让机器人的相对位置精度达到100%。