Hadoop是我们在解决海量数据存储和处理等问题时常用的解决方案,我们利用Hadoop的HDFS对海量数据进行存储,通过开发MapReduce类型的程序对数据进行处理。但是现在我们一提到Hadoop并不是单纯的指这一个项目,而是指整个的Hadoop的生态圈。因为像Hadoop这么刁的还有十几个。比如数据仓库工具Hive,列式数据库HBase,集群构建工具Ambari,基于内存的分布式计算工具Spark,数据同步工具Sqoop等等。
今天我们就来说说HBase。HBase是apache的顶级项目,基于Hadoop的HDFS文件系统进行数据存储,这点呢类似于Hive。我们知道Hive是基于hadoop的一个数据仓库工具,适合用来对一段时间内的数据进行分析查询。不应该用来进行实时的数据查询,(当然Hive的设计目的也不是为了支持实时查询)。而HBase就非常适合用来进行大数据的实时查询。所以HBase在大数据生态圈是作为解决大数据的实时查询的重要工具。在我们的日常工作当中也是最常使用到的工具。
而且通过Phoenix还可以让我们通过SQL语句或者通过JDBC编程就能很简单的使用HBase,降低了学习的门槛,很容易应用到我们的业务当中去。今天我们现在看看怎么部署HBase伪分布式集群
那么HBase伪分布式环境部署要分几步呢?我们现在梳理一下。
Linux基础环境及相关工具
Hadoop环境
Zookeeper集群
HBase集群的部署和配置
首先大家可以下载Zookeeper和HBase的安装包。本次教程选择zookeeper的版本为3.4.9 hbase的版本为1.2.4。
Linux基础环境及相关工具
想往大数据方向发展Linux的基础知识还是需要了解一些。
Hadoop 环境配置
因为HBase依赖HDFS作为存储,两者经常搭配使用,所以我们要安装Hadoop环境
Zookeeper环境部署
注:如果大家为了简单的话,可以选择不安装Zookeeper集群,HBase默认配置自己提供zookeeper的支持
当我们下载完Zookeeper的安装包之后,我们将Zookeeper安装到/usr/local/zookeeper 这个目录。
cd zookeeper-download-dir # 跳转到zookeeper安装包下载目录
tar zxvf zookeeper-tar-gz # 解压缩安装包
mv zookeeper-dir /usr/local/zookeeper # 移动到我们指定目录
接下来就是对zookeeper进行配置了,我们需要跳转到zookeeper的conf目录,将zoo_sample.cfg copy一份。然后更改其中的配置就可以了。如下图所示:

cd /usr/local/zookeeper/conf # 跳转到配置目录
cp zoo_sample.cfg zoo.cfg # 拷贝配置文件
vi zoo.cfg # 编辑配置文件
# zoo.cfg默认配置信息如下
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to 0 to disable auto purge feature
#autopurge.purgeInterval=1
如果我们配置单机版的zookeeper,我们无需做任何更改。
如果我们需要配置成集群模式的,我们需要在zoo.cfg内按如下格式进行配置:
server.id=host:port:port
id 被称为 Server ID, 用来标识服务器在集群中的序号。同时每台 ZooKeeper 服务器上, 都需要在数据目录(即 dataDir 指定的目录) 下创建一个 myid 文件, 该文件只有一行内容, 即对应于每台服务器的Server ID。
我们将我们单机配置成集群模式,我们的配置文件如下:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to 0 to disable auto purge feature
#autopurge.purgeInterval=1
server.1=localhost:2888:3888
所以在我们的主机就是server.1 ,它的 myid 文件内容就是 1。
注:如果是集群模式,在我们启动zookeeper服务之前,我们需要在它的dataDir下创建myid文件,内容为它的id。所以我们配置的是集群模式,我们需要先创建myid文件。
mkdir /tmp/zookeeper # 我们配置的dataDir,大家需要改成自己的
echo 1 /tmp/zookeeper/myid # 创建myid文件
接下来我们就是启动Zookeeper了。
cd /usr/local/zookeeper/bin/
./zkServer.sh start # 启动zookeeper
./zkServer.sh status # 查看zookeeper状态
启动结果如图所示:
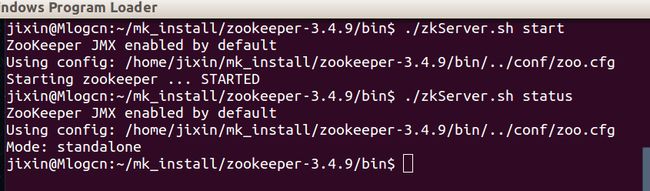
那么zookeeper的配置文件的内容都是什么意思呢,我们应该怎样设置它呢。这部分大家还是要自行搜索一下。相关配置说明在本文最后面有介绍。
HBase安装配置
当我们下载完HBase的安装包之后,我们将HBase安装到/usr/local/hbase 这个目录。
cd hbase-download-dir # 跳转到hbase安装包下载目录
tar zxvf hbase-tar-gz # 解压缩安装包
mv hbase-dir /usr/local/hbase # 移动到我们指定目录
接下来就是对hbase进行配置了,首先我们将hadoop的配置文件hdfs-site.xml 和 core-site.xml 拷贝到hbase的conf目录。
cp /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hbase/conf
cp /usr/local/hadoop/etc/hadoop/core-site.xml /usr/local/hbase/conf
1. 不需要配置zookeeper的HBase集群安装
我们需要更改hbase-env.sh 和 hbase-site.xml
对于hbase-env.sh 我们首先需要更改起JAVA_HOME。如下图所示:

如果我们这里使用的是HBase自带的zookeeper。我们的hbase-env.sh就配置完成了。关于zookeeper的配置在hbase-env.sh内有这么一行默认配置,如图所示:

这里默认使用hbase自己管理的zookeeper。
我们将hbase-site.xml内容配置如下:

hbase.rootdir:该参数制定了HReion服务器的位置,即数据存放的位置。主要端口号要和Hadoop相应配置一致。
hbase.cluster.distributed:HBase的运行模式。false是单机模式,true是分布式模式。若为false, HBase和Zookeeper会运行在同一个JVM里面。默认为false.
2. 需要安装zookeeper的HBase集群安装
我们需要更改hbase-env.sh 和 hbase-site.xml
对于hbase-env.sh 我们首先需要更改起JAVA_HOME。如下图所示:
如果我们这里使用的是我们安装的zookeeper。我们的hbase-env.sh还需要更改HBASE_MANAGES_ZK的配置,如图所示:
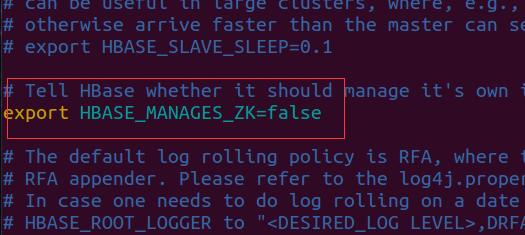
然后我们配置hbase-site.xml,我们将它配置为:

hbase.zookeeper.property.dataDir:hbase zookeeper数据存储地址
hbase.zookeeper.quorum:zookeeper集群的地址
hbase.zookeeper.property.clientPort:zookeeper集群的端口
当我们将HBase的相关配置都配置完成之后,我们就可以执行相关脚本启动我们的HBase了(在启动之前需要先启动zookeeper和Hadoop),然后我们通过jps可以查看相关的进程。
cd /usr/local/hbase/bin
./start-hbase.sh
执行结果如图所示:
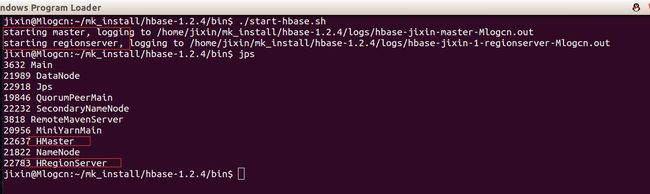
好了,我们的伪分布式HBase集群就配置完成了,如果大家无法启动或者有其他问题,可以通过查看启动日志来定位问题。
作为Hadoop生态圈重要的一员,我们经常会用HBase来存储一些非机构化的数据。HBase作为一个列式数据库,可以节省存储空间,自动切分数据,提供高并发的读写操作的支持,本身存储又基于HDFS保证数据的可靠性。在很多业务场景都是我们首选的方案。大家对于HBase是不是更加有兴趣了呢?
如果大家想了解更多的HBase相关的基础知识,基本操作以及如何通过java程序使用HBase,如何对HBase进行调优,如何将HBase快速应用到业务应用中。
Zookeeper 配置简介
tickTime: ZooKeeper 中使用的基本时间单元, 以毫秒为单位, 默认值是 2000。它用来调节心跳和超时。
initLimit: 默认值是 10。它用于配置允许 followers 连接并同步到 leader 的最大时间(为initLimit*tickTime)。如果 ZooKeeper 管理的数据量很大的话可以增加这个值。
syncLimit: 默认值是 5。它用于配置leader 和 followers 间进行心跳检测的最大延迟时间(为syncLimit*tickTime)。如果在设置的时间内 followers 无法与 leader 进行通信, 那么 followers 将会被丢弃。
dataDir: ZooKeeper 用来存储内存数据库快照的目录, 并且除非指定其它目录, 否则数据库更新的事务日志也将会存储在该目录下。建议配置 logDir 参数来指定 ZooKeeper 事务日志的存储目录。
clientPort: 服务器监听客户端连接的端口, 也即客户端尝试连接的端口, 默认值是 2181。
maxClientCnxns: 在 socket 级别限制单个客户端与单台服务器之前的并发连接数量, 可以通过 IP 地址来区分不同的客户端。它用来防止某种类型的 DoS ***, 包括文件描述符耗尽。默认值是 60。将其设置为 0 将完全移除并发连接数的限制。
autopurge.snapRetainCount: 配置 ZooKeeper 在自动清理的时候需要保留的数据文件快照的数量和对应的事务日志文件, 默认值是 3。
autopurge.purgeInterval: 和参数 autopurge.snapRetainCount 配套使用, 用于配置 ZooKeeper 自动清理文件的频率, 默认值是 1, 即默认开启自动清理功能, 设置为 0 则表示禁用自动清理功能。