最近几天被这个知识弄得晕头转向,查资料都是递归查找法,一环接一环的(:з」∠),通过和舍友激烈的讨论,现在总结了一篇文章出来,希望能帮助后面的人更好地理解内存方面的知识。
在这篇文章中,我将会对自己在探索过程中产生的一些疑惑进行解答:
- 内存是怎么样管理的?(什么区域放置了什么?)
- 为什么会有栈内存和堆内存?
- 线程、函数和内存又有什么关联呢?
- 对于特定的一段代码,在内存视角的实现过程?
零.写在前面
这篇文章属于归纳和总结,所以都是参考了别人的文章来写的,这里只是对这些文章压缩成一篇文章,并尝试用更易理解的语言来帮助自己和读者理解,感谢这些可爱的博主:
- iOS开发中的内存分配(堆和栈)
- 为什么c++中要分为heap(堆)和stack(栈)?
- 栈、堆内存到底是如何申请的,方法是如何入栈出栈的——内存结构理解学习
- 多线程 - 你知道线程栈吗
以上文章将会一一对应我所产生的疑惑。
一.内存模型
每个面向对象编程的语言都会有对象,有了对象就难免会提及到这些对象的管理。
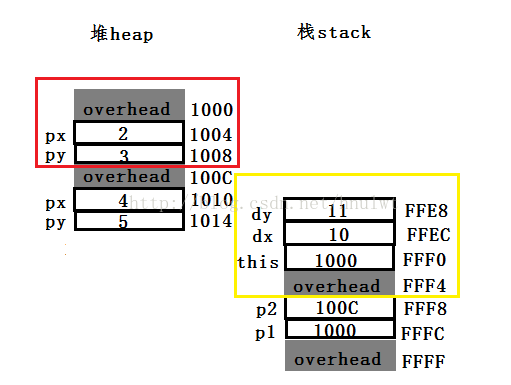
在计算机组成原理中,内存会被分成很多个区域,每个区域都会有自己的功能,而我们访问这个区域的对象的方法是通过用指针访问这个区域的对象的内存地址,从而达到增删查改的目的,一个内存模型是长这样的:
每个区域的用途,在这篇博客里面已经总结得很好了,在这里我就照抄了:
代码区:代码段是用来存放可执行文件的操作指令(存放函数的二进制代码),也就是说是它是可执行程序在内存种的镜像。代码段需要防止在运行时被非法修改,所以只准许读取操作,而不允许写入(修改)操作——它是不可写的。
全局(静态)区包含下面两个分区:
数据区:数据段用来存放可执行文件中已初始化全局变量,换句话说就是存放程序静态分配的变量和全局变量。
BSS区:BSS段包含了程序中未初始化全局变量。
常量区:常量存储区,这是一块比较特殊的存储区,他们里面存放的是常量,
堆(heap)区:堆是由程序员分配和释放,用于存放进程运行中被动态分配的内存段,它大小并不固定,可动态扩张或缩减。当进程调用alloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用realse释放内存时,被释放的内存从堆中被剔除(堆被缩减),因为我们现在iOS基本都使用ARC来管理对象,所以不用我们程序员来管理,但是我们要知道这个对象存储的位置。
栈(stack)区:栈是由编译器自动分配并释放,在一个作用域内,用户存放程序临时创建的局部变量,存放函数的参数值,局部变量等。也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味这在数据段中存放变量)。除此以外在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也回被存放回栈中。由于栈的先进后出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上将我们可以把栈看成一个临时数据寄存、交换的内存区。
上述几种内存区域中数据段、BSS和堆通常是被连续存储的——内存位置上是连续的,而代码段和栈往往会被独立存放。
栈是向低地址扩展的数据结构,是一块连续的内存的区域。
堆是向高地址扩展的数据结构,是不连续的内存区域。
有人会问堆和栈会不会碰到一起,他们之间间隔很大,绝少有机会能碰到一起,况且堆是链表方式存储!
下面来写一个例子,帮助大家理解各个对象存放的区域:
#import "HobenViewController.h"
@interface HobenViewController ()
@end
@implementation HobenViewController
int num = 1; //数据区(全局区/静态区)
NSString *str; //BSS区(全局区/静态区)
static NSString *str2 = @"string"; //静态区(静态初始化区/全局区)
- (void)viewDidLoad {
[super viewDidLoad];
int age; //栈
NSString *name = @"Hoben"; //栈
NSString *number = @"123"; //123在常量区,number在栈上
//分配而来的8字节的区域就在堆中(相当于alloc分配内存),array在栈中,指向堆区的地址
NSMutableArray *array = [NSMutableArray arrayWithCapacity:1];
}
/* 方法中的num1和num2都在栈中,返回值num也暂存在栈中 */
- (int)changenum:(int)num1 num2:(int)num2{
int num = num1 + num2;
return num;
}
@end
二.堆内存和栈内存
内存学到这里,有人就会产生疑问了:既然栈内存这么方便,系统可以自动进行管理,那么我们还何必弄出一个堆内存呢?这不是麻烦了程序员吗?
一开始我觉得这个问题很有道理,但是我想了一下,栈内存之所以方便,肯定是有他独特的机制的,脱离了这个机制,一切的方便就会变得不方便!(想想手动挡和自动挡,自动挡一脚油门能踩到底,但是性能肯定没手动挡好,你看看那些跑车哪个不是手动挡的)
首先让我们看看到底为什么栈内存可以由系统自动管理?
1.栈内存的秘密
先看看栈内存里面存的是什么东西:
- 在
一个作用域内,用户存放程序临时创建的局部变量,存放函数的参数值,局部变量等。
大家都知道栈的特点是后进先出,没错,这就是系统能够自动管理内存的秘密!上面有一个关键词,很好地表达了栈适用的环境:一个作用域内。
如果大家以作用域为单位去考察这个栈内存的话,相信很快就能理解为什么系统能够自动管理这个栈内存了,这是因为在我们的程序中,后调用的函数必定会先结束,很好地符合了栈的特性:后进先出。
这也很好解释了为什么递归的时候没有加终止条件的话,会隔一段时间之后报错崩溃:这是因为系统不断地往栈内存塞东西,当塞的东西超过了栈内存的容量之后,栈内存就会爆掉,系统就会崩溃了!
如果递归成功的话,那么栈内存将会有条不紊地进行压栈、出栈操作,达到终止条件之后,最后递归的先出栈,最先递归的后出栈。
2.堆内存的存在意义
堆内存放的是什么呢?
- 当进程调用alloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用realse释放内存时,被释放的内存从堆中被剔除(堆被缩减)。
也就是说,堆内存里面都是一些调用了分配内存函数的东西:
//C++
int *p = new int[10];
//OC
Class *class = [[Class alloc] init];
以上代码中,new定义了一个堆空间,存放了int数组,放在了堆内存,而p则是一个指向堆内存的指针,存放着数组首地址,放在了栈内存。
如果我们把堆内存舍弃掉,一切由栈内存管理会怎么样呢?
int *p1 = new int[10];
int *p2 = new int[10];
delete p1;
delete p2;
就看看上面的代码,不难发现,如果使用栈内存管理的话,当我们需要delete p1指向的内存的时候,发现p2在栈顶,这时候就不好办咯。这时候,使用栈内存管理就会受限于他的后进先出特性,自动化管理也因此失效了!
堆内存虽然看上去笨重,但是他有得天独厚的链式结构,这个结构的优势在于:它的插入和删除都显得非常的简单,O(1)的时间复杂度让人感到非常舒服!程序员需要管理堆内存,但是管理起来无非也就两行代码的事情:
new A
delete a
所以说,全自动化的东西有时候也不是特别好用,手动化的东西并不是一无是处,一定要依照它所处的环境来分类讨论!
- 回到之前提到的问题:既然栈内存这么灵巧自动化,为什么还要有堆内存?相信大家心里面应该有自己的答案了:
在我看来,栈内存之所以管不了堆内存里面的东西,是因为不知道堆内存的内容什么时候应该释放掉(这得由程序员写的代码决定),栈内存的内容,释放起来是有个先后顺序的,才能够被自动管理。
所以,我的答案就两个字:内容
3.堆内存的自动管理
当自己是个小萌新的时候,根本就没有写过释放函数,还以为是这些放进堆内存的对象也是可以被系统自动回收的呢,还是太天真。。
实际上,无论是Java的GC还是objective-C的ARC,都是编译器自动帮我们进行了堆内存的管理,以ARC为例,XCode会在编译阶段自动添加内存管理代码,使得堆内存的回收无须再由程序员手动添加,大大提高了我们的效率。
但这一切都是苹果开发者的功劳,而不是系统自身的功劳。也就是说,堆内存的自动管理,还是另一群程序员帮我们做的,别想太多了,圣诞节的礼物是父母偷偷放进袜子里面的,哪有真正的圣诞老人。
三.线程与内存
我们知道,栈内存的压栈和出栈是通过移动栈指针来实现的。
先看看下面的函数:
void func3(){
int a;
int b;
}
void func4(){
int c;
int d;
}
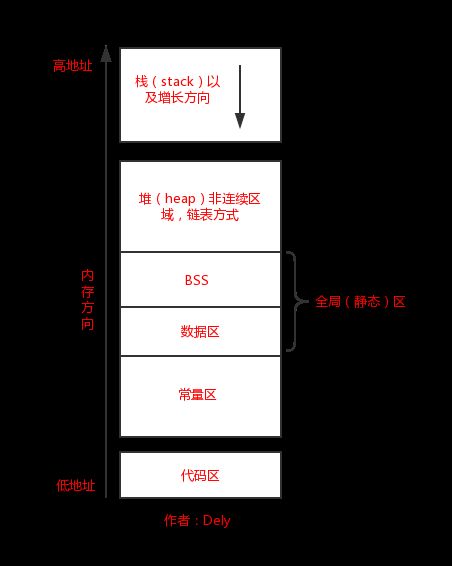
假设,func3和func4分别被两个线程调用,并且func3先于func4执行,并且4个变量压栈的顺序分别是a、b、c、d。按照上面第1个说明,这个时候栈顶指针指向d。
如果,这个时候func3先执行完,那么这个时候,系统要回收b和a,但是b并不在栈顶,所以,无法移动栈顶指针,所以,b和a无法回收。最复杂的情况可能如下,压栈的顺序是a、c、d、b,这个时候b可以正常回收。当要回收a时,会不会误把d当作a给回收了?应该怎么解释这个问题呢?
显然,事实上并非上面所述,因为线程里有一个很重要的属性stacksize,它让我们隐约感觉到,线程是拥有私有的栈空间的,如果这样,abcd的压栈出栈就不会有问题了,因为他们并不保存在一起。也就是说,每个线程都有自己的独立栈空间!
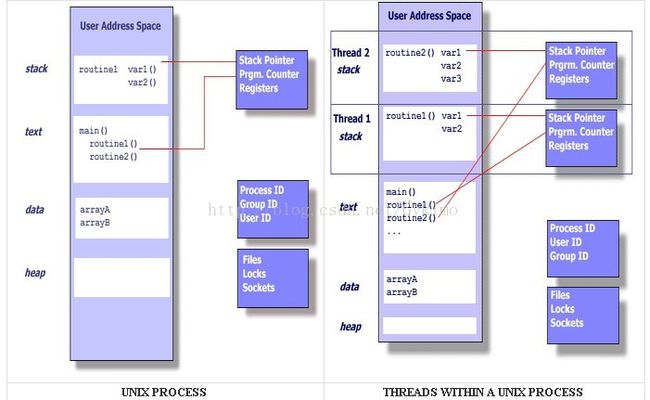
我们从图上可以看出,两个线程之间的栈是独立的,其他是共享的,所以,在操作共享区域的时候才有可能出现同步需要,操作栈不需要同步。
四.内存操作实例
下面来用一段详细的代码和对应的内存来讲解一下内存的工作实例:
class Point {
private int px;
private int py;
public Point(int x, int y) {
px = x;
py = y;
}
public void move(int dx, int dy) {
px += dx;
py += dy;
}
}
public class Test {
public void test() {
Point p1 = new Point(2, 3);
Point p2 = new Point(4, 5);
p1.move(10, 11);
}
}
程序在运行到test方法第一行时,由于有new,在堆上,我们申请了内存,在1004位置上存了2,在1008位置上存了3,overhead部分是一些额外的内存开销,在此我们不关注。在栈上,我们FFFC位置上存储了刚才在堆上创建的对象的首地址。同理,test第二句也是这样执行。如下图所以,该图就是test方法前两句执行完毕后,在堆、栈的样子。
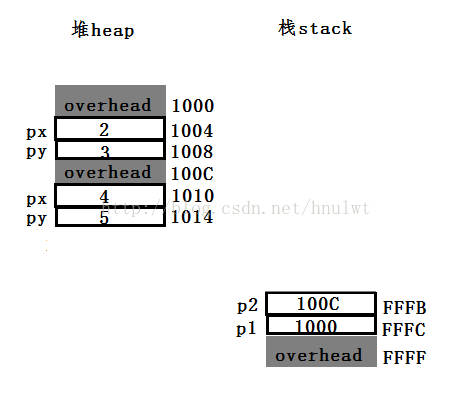
接着,调用了p1.move(10, 11),从上图看,这时我们要调用他,首先在栈上创建的是对象指位器,也叫this指位器。这个this是用来做什么的呢?this用来指示对象本身,他是如何指向本身的,下图中可以明了的看出,this右边就是指向当前对象的地址,也就是下图中的红色区域。
接着,我们可以得到dx,dy,注意栈是向上分配的,也就有了下图中的表示,他们的值分别是10,11。这时候我们才真正进行move动作,也就是加数值操作,先move方法第一行,我们把dx的值加到px上。第二行同理。
该方法执行完毕了,我们知道,当栈上的变量停止访问,也就是他不在用了,操作系统就会对这段内存进行回收。即出栈操作,执行完出栈操作后,下图中黄色的部分也就消失了。假如接着还有其他方法执行,这时候就在FFF8地址之前,也就上面继续进行。