前言
在深度学习中,模型的保存和加载很重要,当我们辛辛苦苦训练好的一个网络模型,自然需要将训练好的模型保存为文件。在测试使用时候,又需要将保存在磁盘的模型文件加载调用。
在pytorch中网络模型定义为torch.nn.Module的子类的对象。因此模型的保存与加载涉及到2个重要概念——对象的序列化和反序列化。
目的
- 理解并掌握对象的序列化,反序列化
- 实现pytorch模型的保存与加载
开发/测试环境
- Ubuntu 18.04
- pycharm
- Anaconda3
- pytorch
- IntellJIDEA ,JDK10
对象的序列化与反序列化
序列化和反序列化听起来感觉高大上,其实是很常见的操作,下面举一个JAVA对象序列化和反序列化的例子,帮助理解。
序列化: 把对象转换为字节序列的过程称为对象的序列化。
序列化的目的:
在很多应用中,需要对某些对象进行序列化,让它们离开内存空间,入住物理硬盘,以便长期保存。比如最常见的是Web服务器中的Session对象,当有 10万用户并发访问,就有可能出现10万个Session对象,内存可能吃不消,于是Web容器就会把一些seesion先序列化到硬盘中,等要用了,再把保存在硬盘中的对象还原到内存中。
反序列化: 把字节序列恢复为对象的过程称为对象的反序列化。
当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象。 当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象。
首先,定义一个Person类,实现Serializable接口
package com.sty;
import java.io.Serializable;
/*
Java对象的序列化
实现Serializable接口
*/
public class Person implements Serializable {
private static final long serialVersionUID = -5809782578272943999L;
private int age;
private String name;
private String sex;
public int getAge() {
return age;
}
public String getName() {
return name;
}
public String getSex() {
return sex;
}
public void setAge(int age) {
this.age = age;
}
public void setSex(String sex) {
this.sex = sex;
}
public void setName(String name) {
this.name = name;
}
}
- 序列化
- 反序列化
package com.sty;
import java.io.*;
//http://www.cnblogs.com/xdp-gacl/p/3777987.html
public class Main {
public static void main(String[] args) throws IOException, ClassNotFoundException {
serializePerson();
Person person = deserializePerson();
System.out.println(person);
}
/*
对象的序列化
*/
private static void serializePerson() throws IOException {
Person person = new Person();
person.setAge(25);
person.setName("LiMing");
person.setSex("male");
/*
ObjectOutputStream 对象输出流
*/
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(new File("/home/weipenghui/Person.txt")));
objectOutputStream.writeObject(person);
System.out.println("对象序列化成功");
objectOutputStream.close();
}
/*
对象的反序列化
*/
private static Person deserializePerson() throws IOException, ClassNotFoundException {
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("/home/weipenghui/Person.txt"));
Person person = (Person) objectInputStream.readObject();
System.out.println("Person对象序列化成功");
return person;
}
}
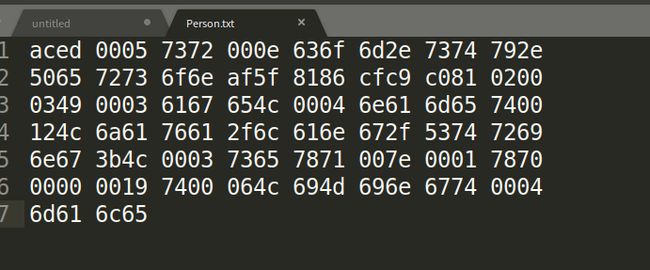
通过实现Serializable接口, 调用ObjectOutputStream 实现了对象的序列化。Java对象序列化的结果:
使用python序列化、反序列化对象
python中提供了pickle包进行对象的序列化和反序列化。
简单例子,首先定义一个简单的类Student, 分别进行序列化和反序列化。
-
pickle.dump()对象序列化 -
pickle.load()对象反序列化
import pickle
class Student:
def __init__(self):
self.name = 'aa'
self.age = 10
self.gender = 'male'
def set_name(self, name):
self.name = name
def set_age(self, age):
self.age = age
def set_gender(self, gender):
self.gender = gender
def __str__(self):
return 'Student: name:{}, age:{}, gender:{}'.format(self.name, self.age, self.gender)
stu1 = Student()
stu1.set_age(22)
stu1.set_name('xiaotiantian')
stu1.set_gender('female')
print(stu1)
# 使用pickle序列化对象
# pickle.dump()
pickle_file = open('./data/student1.pkl', 'wb')
pickle.dump(stu1, pickle_file)
pickle_file.close()
# pickle反序列化对象
# pickle.load()
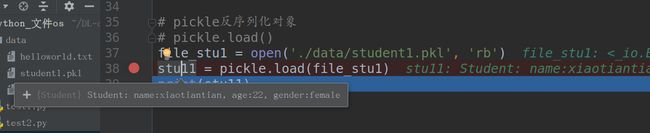
file_stu1 = open('./data/student1.pkl', 'rb')
stu11 = pickle.load(file_stu1)
print(stu11)
直接用文本打开序列化的文件,发现是乱码的,没事,代码解析又不是人去解析。

反序列化的结果,从文件恢复出一个对象。
pytroch模型的保存与加载
有了上面序列化, 反序列化的基础,很容易理解模型的保存就是序列化过程, 模型加载则是反序列化过程。
When it comes to saving and loading models, there are three core functions to be familiar with:
- torch.save: Saves a serialized object to disk. This function uses Python’s pickle utility for serialization. Models, tensors, and dictionaries of all kinds of objects can be saved using this function.
- torch.load: Uses pickle’s unpickling facilities to deserialize pickled object files to memory. This function also facilitates the device to load the data into (see Saving & Loading Model Across Devices).
- torch.nn.Module.load_state_dict: Loads a model’s parameter dictionary using a deserialized state_dict. For more information on state_dict, see What is a state_dict?.
模型保存与加载
pytorch中分为2种方法:
- 保存整个模型(包括网络结构)
- 只保存网络的训练参数
state_dict
与之对应,模型加载也是2中方法。
保存,加载整个模型
保存
torch.save(model, PATH)
加载
Model class must be defined somewhere
model = torch.load(PATH)
model.eval()
只保存网络的训练参数
save
torch.save(model.state_dict(), PATH)
laod
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.eval()
End
参考:
https://pytorch.org/tutorials/beginner/saving_loading_models.html