机器配置:
10.33.101.243 master
10.33.101.244 slave01
10.33.101.247 slave02
1、创建账号
#以root用户创建hadoop用户和组创建hadoop用户和组
groupadd hadoop
useradd -g hadoop hadoop
#修改用户密码
passwd hadoop
2、配置ssh免密。
#首先切换到上面的hadoop用户,这里我是在master机器上操作
#生成非对称公钥和私钥,这个在集群中所有节点机器都必须执行,一直回车就行
ssh-keygen -t rsa
#通过ssh登录远程机器时,本机会默认将当前用户目录下的.ssh/authorized_keys带到远程机器进行验证,这里是/home/hadoop/.ssh/authorized_keys中公钥(来自其他机器上的/home/hadoop/.ssh/id_rsa.pub.pub),以下代码只在主节点执行就可以做到主从节点之间SSH免密码登录
cd /home/hadoop/.ssh/
#首先将Master节点的公钥添加到authorized_keys
cat id_rsa.pub>>authorized_keys
#其次将Slaves节点的公钥添加到authorized_keys,这里我是在Hadoop31机器上操作的
ssh hadoop@slave01 cat /home/hadoop/.ssh/id_rsa.pub>> authorized_keys
ssh hadoop@slave02 cat /home/hadoop/.ssh/id_rsa.pub>> authorized_keys
#必须设置修改/home/hadoop/.ssh/authorized_keys权限
chmod700~/.ssh
chmod600~/.ssh/authorized_keys
#这里将Master节点的authorized_keys分发到其他slaves节点
scp -r /home/hadoop/.ssh/authorized_keys hadoop@slave01:/home/hadoop/.ssh/
scp -r /home/hadoop/.ssh/authorized_keys hadoop@slave02:/home/hadoop/.ssh/
3、配置JDK环境变量。
4、zookeeper安装(版本3.4.6)
再master,slave01,slave02 上解压zk
修改conf文件夹下 zoo_sample.cfg 为zoo.cfg
配置修改:
dataDir=/opt/zkData
server.1=master:2888:3888
server.2=slave01:2888:3888
server.3=slave02:2888:3888
再每台机器上创建机器标识(echo 1 对应server.1)
master :echo "1" > /opt/zkData/myid
slave01:echo "2" > /opt/zkData/myid
slave02:echo "3" > /opt/zkData/myid
再master上将zk分发到 slave01、slave02上
scp -r /home/hadoop/zookeeper-3.4.6 hadoop@slave01:/home/hadoop/
scp -r /home/hadoop/zookeeper-3.4.6 hadoop@slave02:/home/hadoop/
再master、slave01、slave02 上分别启动zk
cd /home/hadoop/zookeeper-3.4.6/bin
./zkServer.sh start
启动三台后 可以用 ./zkServer.sh status 查看当前zk节点状态
5、现在要开始配置hadoop-ha集群。(使用解压版hadoop)
解压hadoop
修改hadoop-2.7.5/etc/hadoop下文件
core-site.xml

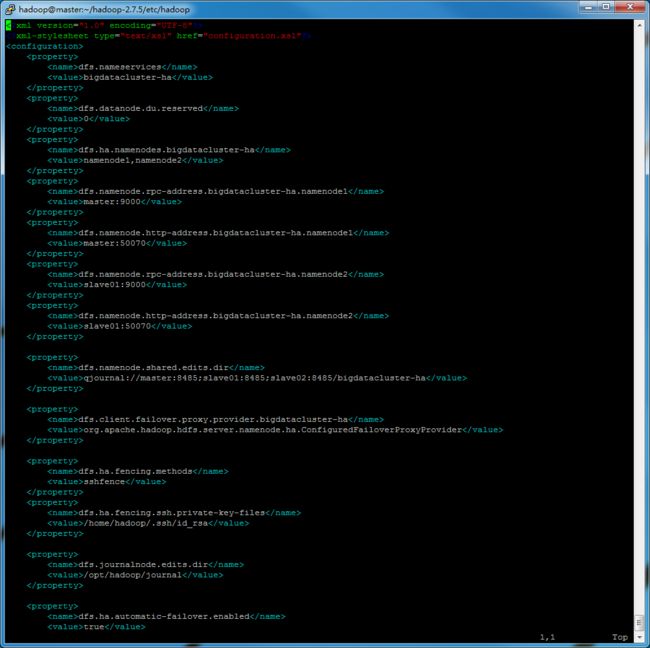
修改hdfs-site.xml

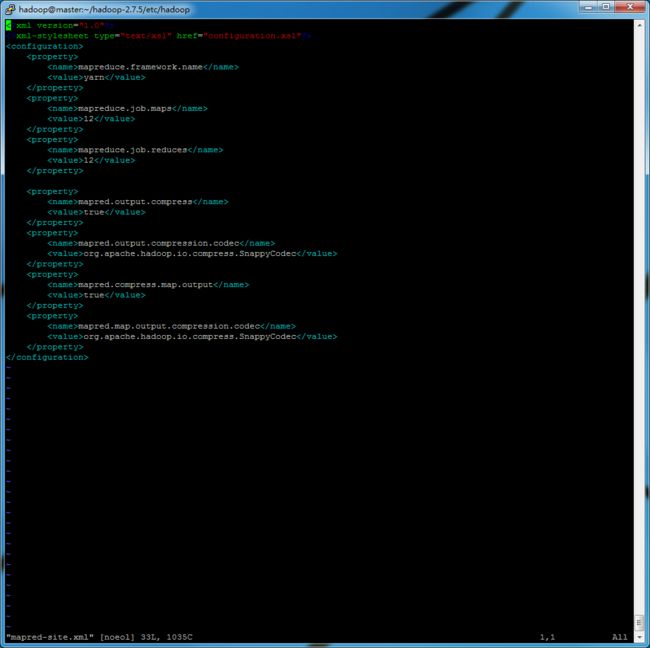
修改mapred-site.xml
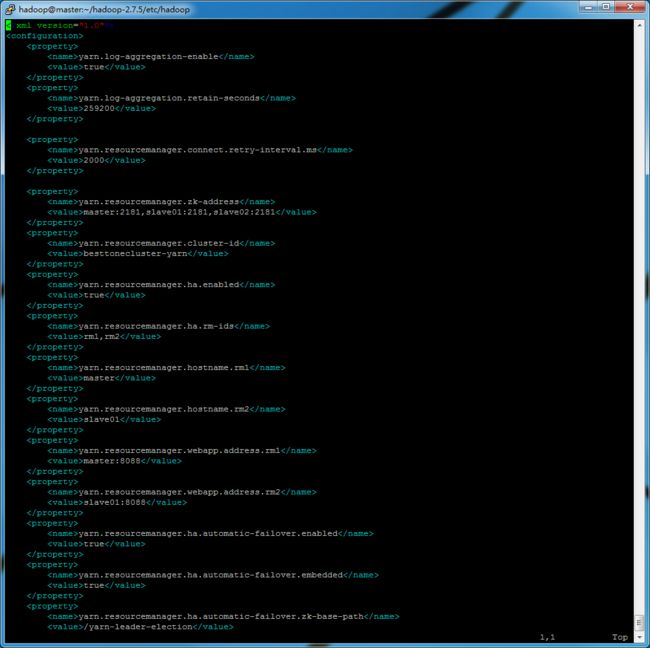
修改 yarn-site.xml
修改 slaves
master
slave01
slave02
修改hadoop-env.sh和yarn-env.sh
export JAVA_HOME=/home/hadoop/java/jdk1.7.0_65
分发hadoop文件到slave01 、slave02
scp -r /home/hadoop/hadoop-2.7.1 hadoop@slave01:/home/hadoop/
scp -r /home/hadoop/hadoop-2.7.1 hadoop@slave02:/home/hadoop/
正式启动hadoop-ha
1、格式化zookeeper上hadoop-ha目录
bin/hdfs zkfc –formatZK
2、启动namenode日志同步服务journalnode(3台全要)
sbin/hadoop-daemon.sh start journalnode
3、格式化namenode
#这步操作只能在namenode服务节点master或者slave01执行中一台上执行
bin/hdfs namenode -format
4、启动namenode、同步备用namenode、启动备用namenode
#启动namenode
ssh master
sbin/hadoop-daemon.sh start namenode
#同步备用namenode、启动备用namenode
ssh slave01
bin/hdfs namenode -bootstrapStandby
sbin/hadoop-daemon.sh start namenode
5、启动DFSZKFailoverController(namnode节点上)
sbin/hadoop-daemon.sh start zkfc
6、启动datanode(只需要再master执行,会自动ssh其他机器启动)
sbin/hadoop-daemons.sh start datanode
7、启动yarn
ssh master
sbin/start-yarn.sh
#在slave01上启动备用resouremanager
ssh slave01
sbin/yarn-daemon.sh start resourcemanager
访问页面 master:50070 查看hadoop高可用状态