一、cookie的保存与读取
1.cookie的保存-FileCookie.Jar
from urllib import request,parse from http import cookiejar #创建cookiejar实例 filename = "cookie.txt" cookie = cookiejar.MozillaCookieJar(filename) #生成cookie的管理器 cookie_handler = request.HTTPCookieProcessor(cookie) #创建http请求管理器 http_handler = request.HTTPHandler() #生成https管理器 https_handler = request.HTTPHandler() #创建请求管理器 opener = request.build_opener(http_handler,https_handler,cookie_handler) def login(): """ 负责初次登录 需要输入用户名密码 :return: """ url = "http://www.renren.com/PLogin.do" data = { "email":"[email protected]", "password":"481648541615485" } #把数据进行编码 data = parse.urlencode(data) #创建一个请求对象 req = request.Request(url,data=data.encode()) #使用opener发起请求 rep = opener.open(req) #保存cookie到文件 #ignore_discard表示及时cookie将要被丢弃也要保存下来 #ignore_expire表示如果该文件中cookie即使已经过期,保存 cookie.save(ignore_discard=True,ignore_expires=True) def getHomePage(): url = "http://www.renren.com/965187997/profile" #如果已经执行了login函数,则opener自动已经包含相应的cookie值 rsp = opener.open(url) html = rsp.read().decode() with open("rsp.html","w") as f: f.write(html) if __name__ == "__main__": """ 执行完login之后,会得到授权之后的cookie 我们尝试把cookie打印出来 """ login() getHomePage()
2.cookie的读取
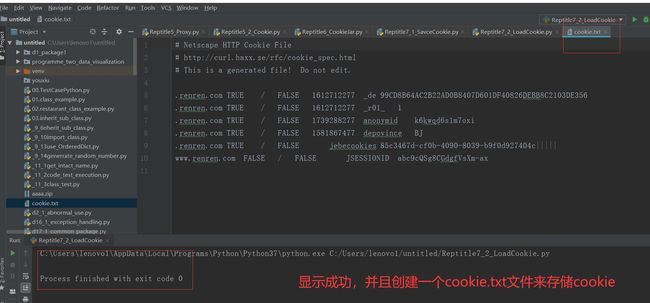
from urllib import request,parse from http import cookiejar #创建cookiejar实例 cookie = cookiejar.MozillaCookieJar() cookie.load("cookie.txt",ignore_discard=True,ignore_expires=True) #生成cookie的管理器 cookie_handler = request.HTTPCookieProcessor(cookie) #创建http请求管理器 http_handler = request.HTTPHandler() #生成https管理器 https_handler = request.HTTPHandler() #创建请求管理器 opener = request.build_opener(http_handler,https_handler,cookie_handler) def login(): """ 负责初次登录 需要输入用户名密码 :return: """ url = "http://www.renren.com/PLogin.do" data = { "email":"[email protected]", "password":"481648541615485" } #把数据进行编码 data = parse.urlencode(data) #创建一个请求对象 req = request.Request(url,data=data.encode()) #使用opener发起请求 rep = opener.open(req) #保存cookie到文件 #ignore_discard表示及时cookie将要被丢弃也要保存下来 #ignore_expire表示如果该文件中cookie即使已经过期,保存 cookie.save(ignore_discard=True,ignore_expires=True) def getHomePage(): url = "http://www.renren.com/965187997/profile" #如果已经执行了login函数,则opener自动已经包含相应的cookie值 rsp = opener.open(url) html = rsp.read().decode() with open("rsp.html","w") as f: f.write(html) if __name__ == "__main__": """ 执行完login之后,会得到授权之后的cookie 我们尝试把cookie打印出来 """ # login() getHomePage()
改代码读取了保存的cookie文件,并且访问网页成功。
二、SSL
1.什么是SSL
(1)SSL证书就是指遵守SSL安全套阶层协议的服务器数字证书(SercureSocketLayer)
(2)该证书是由美国网景公司开发
(3)CA(CertifacateAuthority)是数字证书认证中心,是发放、管理、废除数字证书的收信人的第三方机构。
(4)遇到不信任的SSL证书,可以用代码进行忽略掉
from urllib import request #导入python ssl处理模块 import ssl #利用非认证上下文环境替换认证的下文环境 ssl._create_default_https_context = ssl._create_unverified_context url = "https://www.12306.cn/mormhweb/" rsp = request.urlopen(url) html = rsp.read().decode() print(html)
三、源码
Reptitle7_1_SaveCookie.py
Reptitle7_2_LoadCookie.py
Reptitle7_3_SSLAnalysis.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptitle7_1_SaveCookie.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptitle7_2_LoadCookie.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptitle7_3_SSLAnalysis.py
2.CSDN:https://blog.csdn.net/weixin_44630050
3.博客园:https://www.cnblogs.com/ruigege0000/
4.欢迎关注微信公众号:傅里叶变换,个人公众号,仅用于学习交流,后台回复”礼包“,获取大数据学习资料
