
当您听到“以图搜图”时,是否首先想到了百度、Google 等搜索引擎的以图搜图功能呢?事实上,您完全可以搭建一个属于自己的以图搜图系统:自己建立图片库;自己选择一张图片到库中进行搜索,并得到与其相似的若干图片。
Milvus 作为一款针对海量特征向量的相似性检索引擎,旨在助力分析日益庞大的非结构化数据,挖掘其背后蕴含的巨大价值。为了让 Milvus 能够应用于相似图片检索的场景,我们基于 Milvus 和图片特征提取模型 VGG 设计了一个以图搜图系统。
正文分为数据准备、系统概览、 VGG 模型、API 介绍、镜像构建、系统部署、界面展示七个部分。数据准备章节介绍以图搜图系统的数据支持情况。系统概览章节展示系统的整体架构。VGG 模型章节介绍了 VGG 的结构、特点、块结构以及权重参数。API 介绍章节介绍系统的五个基础功能 API 的工作原理。镜像构建章节介绍如何通过源代码构建客户端和服务器端的 docker 镜像。系统部署章节展示如何三步搭建系统。界面展示章节会展示系统的搜索界面。
1. 数据准备
本文以 PASCAL VOC 图片集为例搭建了一个以图搜图的端到端解决方案,该图片集包含 17,125 张图片,涵盖 20 个目录:人类;动物(鸟、猫、牛、狗、马、羊);交通工具(飞机、自行车、船、公共汽车、小轿车、摩托车、火车);室内(瓶子、椅子、餐桌、盆栽植物、沙发、电视)。
数据集大小:~2GB
下载地址:http://host.robots.ox.ac.uk/p..._11-May-2012.tar
说明:您也可以使用其他的图片数据进行加载。目前支持的图片格式有 .jpg 格式、 .png 格式。
2. 系统概览
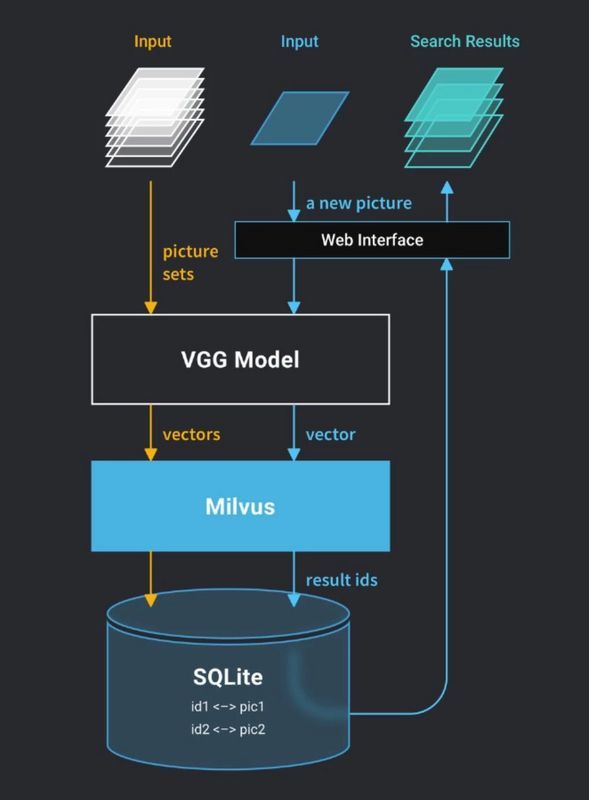
为了让用户在 web 网页上进行交互操作,我们采取了 C/S 的架构。webclient 负责接收用户的请求并将请求发送给 webserver, webserver 接到 webclient 发来的 HTTP 请求之后进行运算并将运算结果返回给 webclient 。
webserver 主要由两部分组成,图片特征提取模型 VGG 和向量搜索引擎 Milvus。VGG 模型负责将图片转换成向量, Milvus 负责存储向量并进行相似向量检索。webserver 的架构如下图所示:
3. VGG 模型
VGGNet 由牛津大学的视觉几何组( Visual Geometry Group )和 Google DeepMind 公司的研究员共同提出,是 ILSVRC-2014 中定位任务第一名和分类任务第二名。其突出贡献在于证明使用很小的卷积( 3*3 ),增加网络深度可以有效提升模型的效果,而且 VGGNet 对其他数据集具有很好的泛化能力。VGG 模型在多个迁移学习任务中的表现要优于 GoogleNet ,从图像中提取 CNN 特征, VGG 模型是首选算法。因此,在本方案中选择 VGG 作为深度学习模型。
VGGNet 探索了 CNN 的深度及其性能之间的关系,通过反复堆叠 3*3 的小型卷积核和 2*2 的最大池化层, VGGNet 成功地构筑了 16-19 层深的 CNN 。在本方案中使用了 Keras 的应用模块( keras.applications )提供的 VGG16 模型。
(1) VGG16 结构
VGG16 共包含 13个 卷积层( Convolutional Layer ), 3 个全连接层( Fully connected Layer ), 5 个池化层( Pool layer )。其中,卷积层和全连接层具有权重系数,因此也被称为权重层,总数目为 13+3=16 ,这即是 VGG16 中 16 的来源。(池化层不涉及权重,因此不属于权重层,不被计数)。
(2) VGG16 特点
- 卷积层均采用相同的卷积核参数
- 池化层均采用相同的池化核参数
- 模型是由若干卷积层和池化层堆叠( stack )的方式构成,比较容易形成较深的网络结构
(3) VGG16 块结构
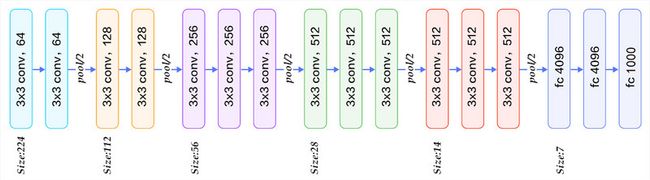
VGG16 的卷积层和池化层可以划分为不同的块( Block ),从前到后依次编号为 Block1~Block5 。每一个块内包含若干个卷积层和一个池化层。例如:Block2 包含 2 个卷积层( conv3-256 )和 1 个池化层( maxpool )。并且同一块内,卷积层的通道( channel )数是相同的。
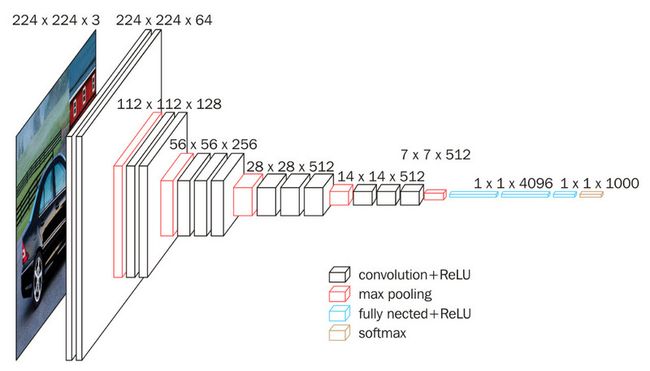
根据下图给出的 VGG16 结构图, VGG16 的输入图像是 224x224x3 ,过程中通道数翻倍,由 64 依次增加到 128 ,再到 256 ,直至 512 保持不变,不再翻倍;高和宽变减半,由 224→112→56→28→14→7 。
(4) 权重参数
VGG 的结构简单,但是所包含的权重数目却很大,达到了 139,357,544 个参数。这些参数包括卷积核权重和全连接层权重。因此它具有很高的拟合能力。
4. API 介绍
整个系统的 webserver 提供了 train 、process 、count、search 、delete 五个 API ,用户可以进行图片加载、加载进度查询、Milvus 的向量条数查询、图片检索、Milvus 表删除。这五个 API 涵盖了以图搜图系统的全部基础功能,下面会对每个基础功能进行介绍。
(1) train
train API 的参数如下表所示:
在进行相似图片检索之前,需要将图片库加载进 Milvus,此时调用 train API 将图片的路径传入系统。因为 Milvus 仅支持向量数据的检索,故而需要将图片转化为特征向量,转化过程主要利用 Python 调用 VGG 模型来实现:
from preprocessor.vggnet import VGGNetnorm_feat = model.vgg_extract_feat(img_path)
当获取到图片的特征向量之后,再将这些向量利用 Milvus 的 insert_vectors 的接口导入 Milvus 里面:
from indexer.index import milvus_client, insert_vectorsstatus, ids = insert_vectors(index_client, table_name, vectors)
将这些特征向量导入 Milvus 之后,Milvus 会给每个向量分配一个唯一的 id,为了后面检索时方便根据特征向量 id 查找其对应的图片,需要将每个特征向量的 id 和其对应图片的关系保存起来:
from diskcache import Cachefor i in range(len(names)):cache[ids[i]] = names[i]
当调用 train API ,通过以上三步就将图片转成向量存入 Milvus 了。
(2) process
process API 的 methods 为 GET,调用时不需要传入其他参数。process API 可以查看图片加载的进度,调用之后会看到已经加载转化的图片数和传入路径下的总图片数。
(3) count
count API 的 methods 为 POST,调用时也不需要传入其他参数。count API 可以查看当前 Milvus 里的向量总数,每一条向量都是由一张图片转化而来。
(4) search
search API 的参数如下表所示:

当你选择好一张图片进行相似图片检索时,就可以调用 search API。当把待搜索的图片传入系统时,首先还是调用 VGG 模型将图片转化为向量:
from preprocessor.vggnet import VGGNetnorm_feat = model.vgg_extract_feat(img_path)
得到待搜索图片的向量之后,再调用 Milvus 的 search_vectors 的接口进行相似向量检索:
from milvus import Milvus, IndexType, MetricType, Statusstatus, results = client.search_vectors(table_name=table_name, query_records=vectors, top_k=top_k, nprobe=16)
搜索出与目标向量相似的向量 id 之后,再根据先前存储的向量 id 和图片名称的对应关系检索出对应的图片名称:
from diskcache import Cachedef query_name_from_ids(vids):res = []cache = Cache(default_cache_dir)for i in vids:if i in cache:res.append(cache[i])return res
当调用 search API ,通过以上三步就可以将与目标图片相似的图片搜索出来了。
(5) delete
delete API 的 methods 为 POST,调用时不需要传入其他参数。delete API 会删除 Milvus 里面的表,清空以前导入的向量数据。
5. 镜像构建
(1) 构建 pic-search-webserver 镜像
首先拉取 Milvus bootcamp 的代码,然后利用我们提供的 Dockerfile 构建镜像:
$ git clone https://github.com/milvus-io/bootcamp.git$ cd bootcamp/solutions/pic_search/webserver# 构建镜像$ docker build -t pic-search-webserver .# 查看生成的镜像$ docker images | grep pic-search-webserver
通过上述步骤就可以构建好 webserver 的 docker 镜像。当然,你也可以直接使用我们上传到 dockerhub 的镜像:
$ docker pull milvusbootcamp/pic-search-webserver:0.1.0
(2) 构建 pic-search-webclient 镜像
首先拉取 Milvus bootcamp 的代码,然后利用我们提供的 Dockerfile 构建镜像:
$ git clone https://github.com/milvus-io/bootcamp.git$ cd bootcamp/solutions/pic_search/webclient# 构建镜像$ docker build -t pic-search-webclient .# 查看生成的镜像$ docker images | grep pic-search-webclient
通过上述步骤就可以构建好 webclient 的 docker 镜像。当然,你也可以直接使用我们上传到 dockerhub 的镜像:
$ docker pull milvusbootcamp/pic-search-webclient:0.1.0
6. 系统部署
我们提供了 GPU 部署方案和 CPU 部署方案,用户可以自行选择。详细的部署流程可以参考链接:
https://github.com/milvus-io/..._search/README.md
Step 1 启动 Milvus Docker
详细步骤可以参考链接:
https://milvus.io/cn/docs/v0...._started/install_milvus/install_milvus.md
Step 2 启动 pic-search-webserver docker
$ docker run -d --name zilliz_search_images_demo \-v IMAGE_PATH1:/tmp/pic1 \-v IMAGE_PATH2:/tmp/pic2 \-p 35000:5000 \-e "DATA_PATH=/tmp/images-data" \-e "MILVUS_HOST=192.168.1.123" \milvusbootcamp/pic-search-webserver:0.1.0
Step 3 启动 pic-search-webclient docker
$ docker run --name zilliz_search_images_demo_web \-d --rm -p 8001:80 \-e API_URL=http://192.168.1.123:35000 \milvusbootcamp/pic-search-webclient:0.1.0
整个以图搜图系统只需三步就可以部署好了。
7. 界面展示
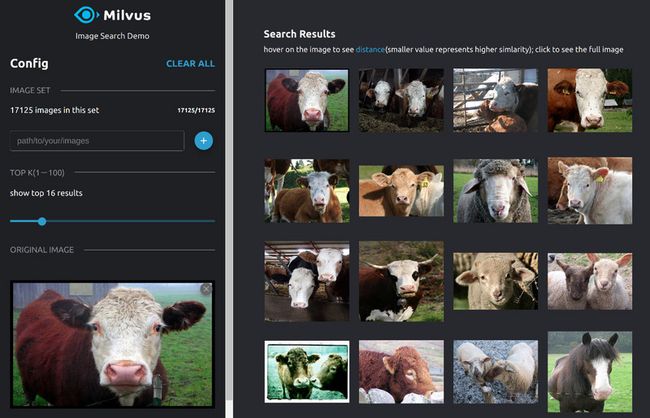
按照上述流程部署完成之后,在浏览器中输入 " localhost:8001 " 就可以访问以图搜图界面了。
在路径框中填入图片路径进行加载,等待图片全部转换成向量并加载到 Milvus之后就可以进行图片检索了:
结语
本文利用 Milvus 和 VGG 搭建起了以图搜图系统,展示了 Milvus 在非结构化数据处理中的应用。Milvus 向量相似度检索引擎可以兼容各种深度学习平台,搜索十亿向量仅毫秒响应。您可以使用 Milvus 探索更多 AI 用法!
更多关于VGG模型的信息请浏览:
VGG 官方网站:http://www.robots.ox.ac.uk/~v..._deep/
VGG Github:
欢迎加入Milvus社区
Milvus 源码
github.com/milvus-io/milvus
Milvus 官网
milvus.io
Milvus Slack 社区
milvusio.slack.com
Milvus CSDN 博客
zilliz.blog.csdn.net
Milvus 线上交流群
关注ZILLIZ公众号 => 点击菜单"线上交流" =>添加ZILLIZ 小秘书入群
© 2019 ZILLIZ™
