原文链接:https://tbgraph.wordpress.com/2017/10/28/neo4j-marvel-social-graph-analysis/
译者言:原文篇副较长,为了方便阅读,这里将原文拆成上下两篇。上篇主要介绍了桶算法,三角形计数几个分析方法,下篇主要介绍聚类系数,连通分量,加权连通分量几种分析方法,总体而言还都是比较基础的分析方法。本文是上篇
本文是漫威社交网络分析序列的第二篇,上一篇文章中,我们已经将Kaggle竞赛的帖子中漫威的数据导入到Neo4j中,同时演示了如何从二分图映射到单分图。我们也使用了一个简单的模型,将任何两位英雄一起出现在漫画的次数记录下来。
译者言:“两位英雄一起出现在漫画的次数”指在一本漫画中,有两位英雄出现了,则计为1次,如在两本漫画中都出现,则为2次。
为了便于理解,我们使用下面的函数来表示:
由
(:Hero)←(:Comic)→(:Hero)到
(:Hero)←[:KNOWS{weight=一起出现在漫画中的次数}]→(:Hero)同时,也可以映射到下面这种单分图
(:Comic)←[{weight=同时出现英雄的个数}]→(:Comic)好,先这些,导入图数据后,我们可以进行接下来的分析了。
基本要求
Neo4j(https://neo4j.com/download/)
Neo4j官方图算法库(https://github.com/neo4j-contrib/neo4j-graph-algorithms/)
Apoc插件(https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases)
图模型
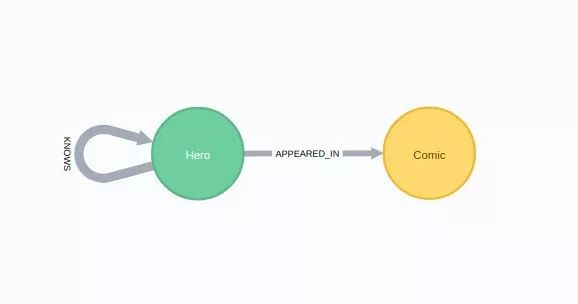
我们已经有一个简单图模型,接下来从Hero和Comics的二分图网络(两种结点类型)开始,根据两个英雄出现在同一个漫画中的次数推导出一个单分图(只有一种结点类型)。
开始分析
下面我们将在之前推导出来的单分图上进行一些分析。关于数据分析,我通常的习惯是先进行一些全局性的统计,对图有一个大概的感性的认识,然后再深入研究细节。
权重分布
我们先来看一下具有相似权重的英雄分布情况。权重值指两英雄在相同漫画中一块出现的总次数。
MATCH ()-[k:KNOWS]->()
RETURN (k.weight / 10) * 10 as weight,count(*) as count
ORDER BY count DESC LIMIT 20第一眼看到这个查询语句,发现 (k.weight / 10) * 10 这样的子句出现,一定会认为这是非常傻的语句。但是如果你了解Neo4j的计算规则(两个整数相除得到仍是整数),就会明白,我们这种写法,是为了完成一个“桶”函数的功能,即把权重都分配到10倍数的桶里。这样就很容易理解下面的结果了。
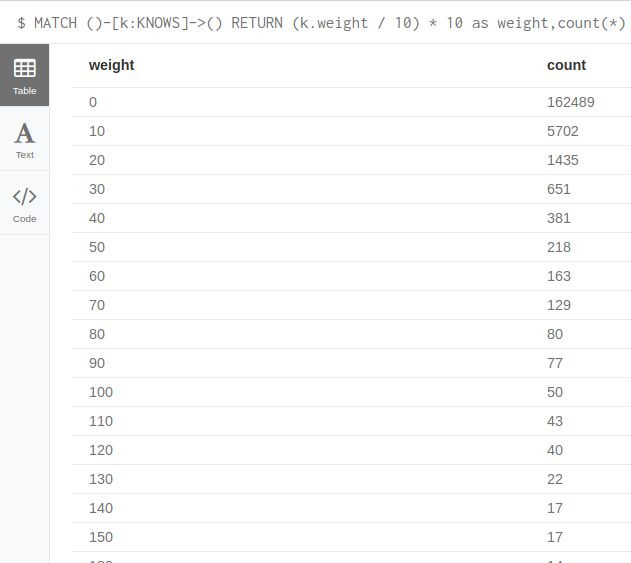
从结果中可以看出,在漫威英雄网络中,在171644个关系中,有162489个关系(点总关系数据的94%)的权重是在10以下,也就是说,大部分英雄之间只有一面之缘。
权重最大值是724,出现在“THING/BENJAMIN J. GR”(石头人)和“HUMAN TORCH/JOHNNY S”(霹雳火),这俩真是一对好基友。
译者言:石头人和霹雳火是神奇四侠中的英雄。实际上权重排名的前三都是神奇四侠的人。
尽管在漫威英雄的社交网络中,大家都是彼此认识的,但是通过权重可以看出,大部分都是很弱的联系。我大胆做两个假设:
大部分漫画都有自己的英雄团队,但团队全体成员并不会在漫画的每一集都会有出现。
偶尔会有几集漫画,不同英雄团队的英雄会一起出现,因此会出现一些弱关系。
为了验证我的假设,我先使用下面的查询语句试试。
MATCH (u:Comic)
RETURN avg(apoc.node.degree(u,'APPEARED_IN')) as average_heroes,
stdev(apoc.node.degree(u,'APPEARED_IN')) as stdev_heroes,
max(apoc.node.degree(u,'APPEARED_IN')) as max_heroes,
min(apoc.node.degree(u,'APPEARED_IN')) as min_heroes
上面显示的是一些平均指标,而我个人更喜欢看分布情况,就像我之前所使用的“桶”函数那样:
MATCH (u:Comic)
RETURN (size((u)-[:APPEARED_IN]-()) / 10) * 10 as heroCount,
count(*) as times
ORDER BY times DESC limit 20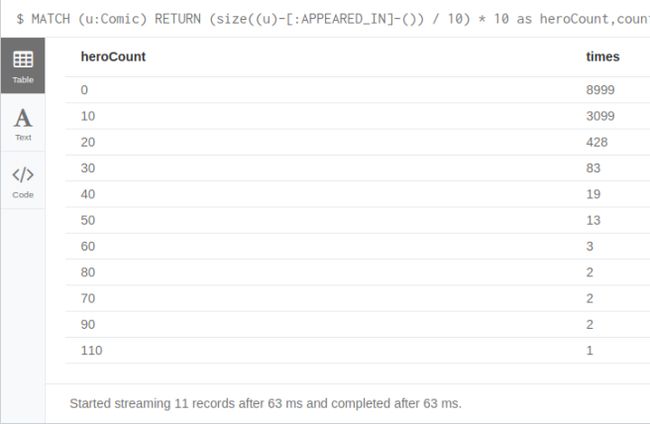
看起来我的假设好像还成,8999(71%)个英雄在漫画中出现的次数少于10次,加上前面平均每集7.5个英雄的推断,可以知道,大部漫画中可能只出现5个英雄或更少。有些漫画会有“家族聚会”的情况,这时会有超过30个英雄出现。有一集漫画叫COCI,就有110个英雄出现,应该是《超级英雄大会》那期。
权重规一化
我们可以使用max或min方法将权重值进行规一化处理。注意这次我们使用的 (toFloat(k1.weight) - min) / (max - min) ,先将将k1.weight转换成浮点型,这样浮点型除以整形,得到的仍是浮点型。也就不会分组到之前的桶里了。
MATCH (:Hero)-[k:KNOWS]->(:Hero)
//get the the max and min value
WITH max(k.weight) as max,min(k.weight) as min
MATCH (:Hero)-[k1:KNOWS]->(:Hero)
//normalize
SET k1.weight_minmax = (toFloat(k1.weight) - min) / (max - min)译者言:上面的语句为每个KNOWS关系都增加了一个规一化的权重属性weight_minmax
上面可以看出来,这些分析还是非常简单的,原文作者写的非常棒,从简入手,让我们看起来比较好理解,稍后下篇时,会慢慢的增加更多的知识点。