Tips:未进行解释的符号主要参照lec1,部分需要参照其他lec~
前面几个Lecture介绍了why can ML?并介绍了一个简单的model:PLA 。有了理论保障,如何设计algorithm?下面进入How can ML 阶段 ^ - ^
Lec 9 :Linear Regression
前面提到的基本是binary classification,如 银行根据顾客信息决定是否发放信用卡……如果换成银行想得到的是顾客的信用额度,这时就是regression问题了~
这章介绍一个新的model:Linear Regression~
1、Hypothesis & Error Measure
regression 的输出空间y = R,什么样的H可以输出实数?
已有顾客的data:x = (x0,x1,x2,……,xd),每一维的数据有不同的含义,如收入、年龄、性别、工作等等。自然地,顾客的信用额度可以用一个加权分数来衡量:
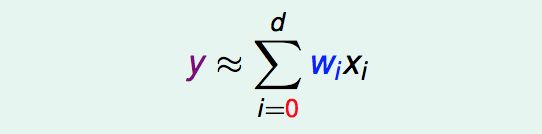
所以线性回归模型的Hypothesis可以表示为:

嗯……你会发现这个h(x)和perceptron的h(x)很像,只是少了取sigh。
那linear regression的H长什么样子呢?x是一维向量和二维向量时如图

这时的关注点不再是 正负 ,而是 距离。g(x)和f(x)的距离,即红线部分。一般把红线叫做 误差 或 residuals(余数,在技法课程中还会看到这个概念)。
这个H的衡量标准是什么?regression通常都会使用squared error ,err(y^,y)= (y^ - y)的平方,则Ein和Eout表示为:

注:经过上一节讨论,现在的setting是有noise的,x服从一个分布P(x),y也会服从一个分布P(y|x),x、y是联合分布。
所以接下来的问题就是 minimize Ein(w),求的w也就求得g。
2、minimize Ein(w)
已经有了Ein(w)的表达式,将其转化为矩阵形式,方便后续计算:

现在优化目标是:

这个式子更简洁,w是唯一变量。Ein(w)是连续函数continuous,且可微differentiable,凸函数convex 。形象点儿就是下图这样的:
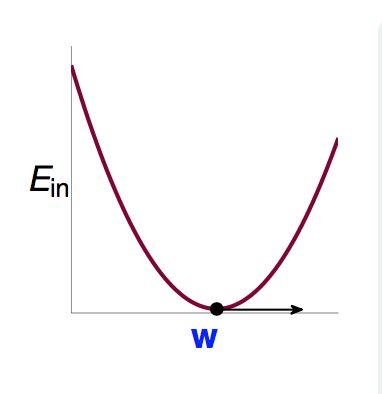
学过微积分的应该知道,这时候存在最低点,且最低点梯度为0.所以找到使梯度为0的w就是结果。(这个思路很重要)

那就算算梯度咯……
展开Ein(w):

用A、b、c替换已知项:

得到:

令梯度等于0,可以求得w。
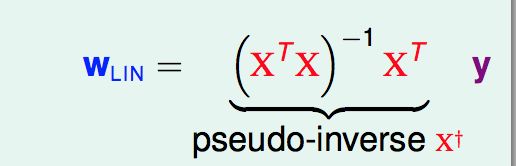
大部分情况下 (XTX)都是可逆的(因为N>>d+1,本人并没有理解)。如上图所示,将一部分定义为pseudo-inverse X+,虚假的逆矩阵。在(XTX)不可逆时,线代里面有很多求 pseudo-inverse 的方法,实际应用中,也会有很多实现好的工具可以用来求X+,建议直接计算X+求得w。
至此,我们就得到一个完整的Linear Regression 模型,完整的algorithm:
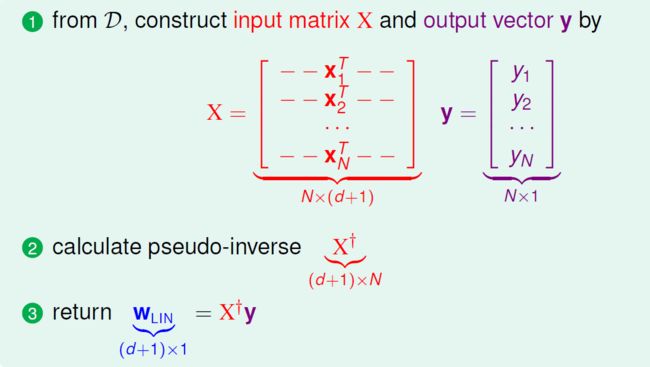
这是一个simple & efficient的算法,我们只需要计算X+。
3、LR真是一个学习算法吗???!
似乎我们只是计算了一个X+就得到了结果,既没有通过迭代优化Ein也没有优化Eout,这真的是一个学习算法吗?其实答案必然是,why?我们已经使得Ein最小,dvc有限时则Eout接近Ein。实际上,迭代优化的过程隐藏在X+的计算过程中了………只要最后Eout是good,也就可以说 learning happened!
VC理论可以保障Eout会很小,对于LR还有另外一种解释,这种解释得益于analytic solution(就是可以轻易分析出结果的意思):
先从Ein 的平均出发,Eout推导与之类似。Ein的平均与VC关注的不一样,VC关注的是个别的Ein。这里的平均是指多次抽取,计算多个Ein,再取平均。最终得到的结果是Ein的平均与“noise level”、“d + 1”、“N”有关……

计算Ein时,Ein表示形式转化为上图,称XX+为 hat matrix H,为什么?因为y乘上这个矩阵后被戴上了一个帽子 ^……哈哈哈哈哈哈哈哈,这是千真万确。
hat matrix做了什么事情?用图解释。

粉色部分可以看成是各个x组成的一个空间,span of X,X散在一个空间里面。y^ = X W,其实y^就是各个x的线性组合,所以y^会在这个X 的span里面(这里就理解为一个平面就好了,输入的x都在这个平面上,所以线性组合出的y^也会在这个平面上)。
紫色部分是Y向量,n维。绿色部分则是y-y^的值,我们希望y - y^越小越好,最小的情况就是垂直的时候,即图中绿色的线。所以其实hat matrix就是把y投影到span of X,得到y^。(I - H)y就是y - y^,算得residual。
直接给出一个结论:trace(I - H) = N - (d + 1),trace是对角线和。why?没给出。但是其哲学含义为:原本自由度为N,投影到一个 d+1维的平面,自由度减少d + 1.
下面再看一张图,理解noise做了什么事情?
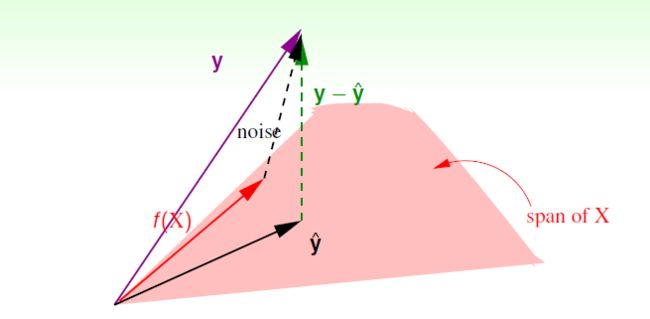
红色f(X)是理想中的那个遥不可及的梦,紫色y是加入了noise 的f(X),y = noise + f(X) 。从图上可以看出,对noise做(I - H)投影同样是得到 y - y^这条绿色的线!!!没错,residual都是noise惹得祸啊……
至此,我们就可以重写Ein这个式子:
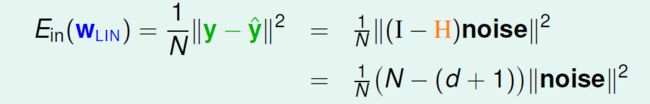
恩,这样我们就得到了这节开始给出的结论:

Eout与Ein类似,只是Eout是“加上”。如何理解呢?哲学上,Ein是我们拿在手上的data,得到的结果自然会偏心使得Ein小一些,而Eout如果也偏向于小一些,就会偏两次!所以,Eout加,再偏回来……哈哈哈哈哈哈,这节的哲学都很有趣!
Ein和Eout的平均作图,称为 Learning Curve (后续章节会再提到这里):

σ平方 就是 noise level 。
这里Ein和Eout的平均差异是 2(d+1)/N 。而之前VC是考虑的最坏情况下差多少……
到这里,应该不得不相信LinReg真的是一个学习算法……
(个人小结一下:
前面的PLA已经感受到即便很直观很直接的简单模型也都有着丰富的数学理论在里面,后面会提到更多更复杂的模型,每一个都有数学的哲思在里面,但是至于是先有蛋还是先有鸡这件事,我也搞不清楚。不得不感慨,数学万岁!
另外,这章的整体思路其实和后面介绍model的章节的思路都是类似的,大概就是 先有一个Hypothesis,然后找到一个error measure,然后你就通过各种数学手段去最优化,就得到了一个学习算法……恩,基本都是这样的。当然都是说起来容易做起来难啊……
哭)
4、LinReg VS LinClassification
线性回归和线性分类比较下吧……
直接上图,不解释:

上面说明了它们之间的区别,但这不是重点,重点是它们之间微妙的联系!
其实{-1,+1} ∈ R,而线性回归又很好解,那么是不是可以用线性回归来做分类呢?!可以!
算出regression的分数后取sign就好了……嘿嘿嘿,理论上怎么解释呢?上图!

这个图是什么意思呢?线性回归和线性分类的主要区别就是错误衡量标准,这张图显示了 err(sqr)是err(0/1)的上限,所以,如果err(sqr)在我们接受的范围内,那err(0/1)必然也可以接受。(这个思路很重要)。嗯哼~我们又找到了一个err(0/1)的上限,比VC bound更loose的上限。做回归效率更高,把err(0/1)换成err(sqr),相当于用上限的loose换取了efficiency!
通常用回归进行分类表现不会太差,但是一般情况下,是用线性回归算得的w作为线性分类(PLA or Pocket)的w0 ,这样可以加速分类的速度。( 这个思路很重要)