为何要做限制
系统使用下游资源时,需要考虑下游资源所能提供资源能力。对于资源受限、处理能力不是很强的资源应当给予保护(在下游资源无法或者短时间内无法提升处理性能的情况下)。可以使用限流器或者类似保护机制,避免下游服务崩溃造成整体服务的不可用。
常见算法
常见限流算法有两种:漏桶算法及令牌桶算法。
漏桶算法
leaky_bucket
漏桶算法 Leaky Bucket (令牌桶算法 Token Bucket)学习笔记
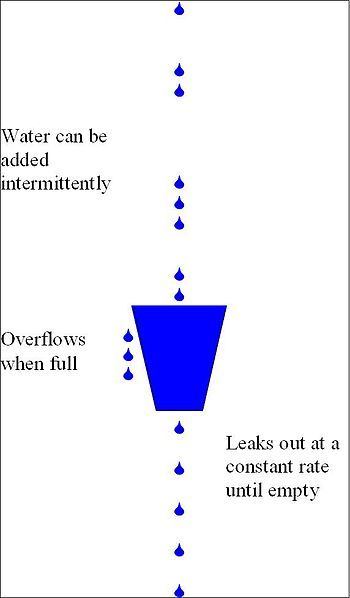
容量有限的桶,桶底有一个漏洞,可以保证桶内若有水时会以速度t(L/s)流出。上方有水注入,当注入的水容量达到桶的容量,且流速超过水流出的速度,表示桶已满。桶满且继续以超过t的速度注入水此时有两种处理方案:
- 此时需停止注水
- 超过的水将溢出丢弃
算法所牵涉的参数:
- 桶的容量
- 流出速度
算法核心:
- 如何判断容量已满
- 如何表达漏水
令牌桶算法
令牌桶算法基于这样的场景的模拟:
有一个装有token且token数量固定的桶,token添加的速率时固定的,当有请求来(或者数据包到达),会检查下桶中是否包含足够多的token(一个请求可能需要多个token)。对于数据包而言,数据包的长度等同于需要获取的token数量。即从桶中消费token,若token数量足够,则消费掉,不够则根据不同的策略处理(阻塞当前或提前消费等)。
Guava Rate limiter实现
Guava实现更接近于令牌桶算法:将一秒钟切割为令牌数的时间片段,每个时间片段等同于一个token。
关键变量:
-
nextFreeTicketMicros:表示下一次允许补充许可的时间(时刻)。这个变量的解释比较拗口,看下面流程会比较清晰 -
maxPermits:最大许可数 -
storedPermits:存储的许可数,数量不能超过最大许可数
实现
这里有一个关键方法(重)同步方法,在初始化以及获取操作时都会用到:
void resync(long nowMicros) {
// if nextFreeTicket is in the past, resync to now
if (nowMicros > nextFreeTicketMicros) {
double newPermits = (nowMicros - nextFreeTicketMicros) / coolDownIntervalMicros();
storedPermits = min(maxPermits, storedPermits + newPermits);
nextFreeTicketMicros = nowMicros;
}
}
如果当前时间(不是时刻,而是自创建起所流经的时间,下同)超过了上一次所设定的nextFreeTicketMicros时间,则会重新进行同步:
- 通过计算上一次设定
nextFreeTicketMicros到当前时刻的时间差获取新增的可用许可数; - 计算可用的许可数:如果新增的许可数+原有的许可数小于最大许可数,则存储的许可数增加新增的数量,否则同步为最大许可数;
- 同步下一次允许补充许可时间为当前时间
初始化
static RateLimiter create(SleepingStopwatch stopwatch, double permitsPerSecond) {
RateLimiter rateLimiter = new SmoothBursty(stopwatch, 1.0 /* maxBurstSeconds */);
rateLimiter.setRate(permitsPerSecond);
return rateLimiter;
}
这里使用一个StopWatch来计时,主要是获取自限速器创建所流经的时间。
初始化关键变量(其实就是通过resync方法来实现主要逻辑的):
nextFreeTicketMicros为当前时间;maxPermits为传入的每秒允许的许可数;storedPermits则为0

获取许可(acquire)
获取一定数量的许可,如果获取不到,则阻塞相应时间,然后获取相应许可。并返回当前操作所等待的时间。
- 尝试
resync操作 - 返回值所需等待时间设置为min(
nextFreeTicketMicros-nowMicros,0) - 实际消耗的许可数:min(请求许可数,存储许可数中的小值);
- 需要刷新获取的许可数(
freshPermits):请求许可数-实际消耗许可数 - 等待时间(
waitMicros):需要刷新获取的许可数(freshPermits)*每个许可数所需时间 - 下一次允许补充许可时间(
nextFreeTicketMicros)同步为:nextFreeTicketMicros+=waitMicros - 更新剩余存储的许可数:存储许可数-本次实际消耗许可数
根据resync方法条件:if (nowMicros > nextFreeTicketMicros)不难发现,如果申请获取的许可数多于剩余可分配的许可数,更新后的nextFreeTicketMicros时间会超过nowMicros,但是当前请求所需等待时间为0。即对于超量许可申请(大于当前可提供的许可数),等待操作是在下一次请求时才会发生。通俗点说就是:前人挖坑后人跳。
当nextFreeTicketMicros早于当前时间,且许可数足够的情况:
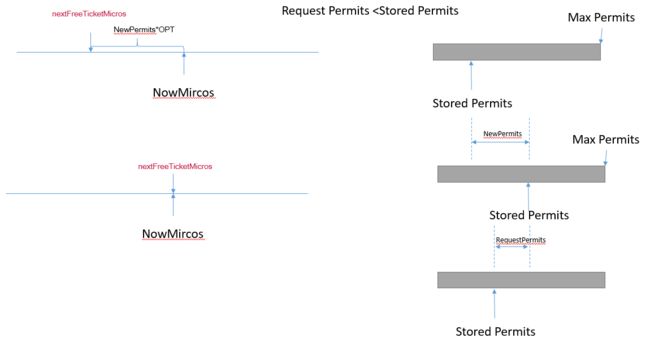
当nextFreeTicketMicros早于当前,但是许可数不够的情况:
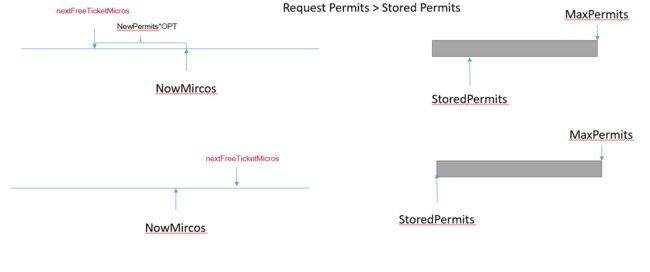
当nextFreeTicketMicros晚于当前时间,主要是阻塞时间计算,许可数分发以及时间计算等同上两场景。
尝试获取许可(tryAcquire)
如果nextFreeTicketMicros-timeout<=nowMicros,说明经过超时时间内也不会有一个许可可以分配(按上描述,只要有许可,就可用分配,无论申请的数量有多少),则tryAcquire操作直接返回false。否则按照acquire操作流程获取许可信息。
预热(warmingup)
首先申请一个容量为100(每秒)的限流器,然后多线程并发获取许可,并发数量为20,且每个线程只获取一次。
附上测试代码:
public void testCurrent(){
RateLimiter rateLimiter = RateLimiter.create(100);
ExecutorService executorService = Executors.newFixedThreadPool(100);
Runnable runnable = ()->{
if(!rateLimiter.tryAcquire(1,100,TimeUnit.MILLISECONDS)){
System.out.println("F"+Thread.currentThread().getName());
}else {
System.out.println("A"+Thread.currentThread().getName());
}
};
for (int i = 0; i < 20; i++) {
executorService.execute(runnable);
}
try {
executorService.awaitTermination(1,TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
按上算法描述应当不会出现F开头的输出,但是实际却发现20次输出基本有小半数的尝试获取失败:
1489453467102 pool-1-thread-1
1489453467102 pool-1-thread-2
1489453467104 pool-1-thread-3
1489453467104 pool-1-thread-4
1489453467105 pool-1-thread-5
1489453467105 pool-1-thread-6
1489453467105 pool-1-thread-7
1489453467107 pool-1-thread-8
1489453467107 pool-1-thread-9
F 1489453467108 pool-1-thread-15
F 1489453467108 pool-1-thread-16
F 1489453467109 pool-1-thread-17
F 1489453467109 pool-1-thread-18
F 1489453467109 pool-1-thread-19
F 1489453467109 pool-1-thread-20
1489453467219 pool-1-thread-10
1489453467239 pool-1-thread-11
1489453467259 pool-1-thread-12
1489453467274 pool-1-thread-13
1489453467297 pool-1-thread-14
问题来自于初始化时,storedPermits存储的许可数为0,而第一个线程进行获取时,离初始时时间非常近,导致第一个线程获取许可后,存储的可用许可数并非为声明的最大许可数,从而导致后续线程尝试获取几次后会耗尽存储的许可数,继而导致tryAcquire操作失败。
RateLimiter的设计哲学
援引自com/google/common/util/concurrent/SmoothRateLimiter.javaDoc说明,非常值得读一下:
How is the RateLimiter designed, and why?
The primary feature of a RateLimiter is its "stable rate", the maximum rate thatis should allow at normal conditions. This is enforced by "throttling" incomingrequests as needed, i.e. compute, for an incoming request, the appropriate throttle time,and make the calling thread wait as much.
The simplest way to maintain a rate of QPS is to keep the timestamp of the lastgranted request, and ensure that (1/QPS) seconds have elapsed since then. For example,for a rate of QPS=5 (5 tokens per second), if we ensure that a request isn't grantedearlier than 200ms after the last one, then we achieve the intended rate.If a request comes and the last request was granted only 100ms ago, then we wait foranother 100ms. At this rate, serving 15 fresh permits (i.e. for an acquire(15) request)naturally takes 3 seconds.
It is important to realize that such a RateLimiter has a very superficial memoryof the past: it only remembers the last request. What if the RateLimiter was unused fora long period of time, then a request arrived and was immediately granted?This RateLimiter would immediately forget about that past underutilization. This mayresult in either underutilization or overflow, depending on the real world consequencesof not using the expected rate.
Past underutilization could mean that excess resources are available. Then, the RateLimitershould speed up for a while, to take advantage of these resources. This is importantwhen the rate is applied to networking (limiting bandwidth), where past underutilizationtypically translates to "almost empty buffers", which can be filled immediately.
On the other hand, past underutilization could mean that "the server responsible forhandling the request has become less ready for future requests", i.e. its caches becomestale, and requests become more likely to trigger expensive operations (a more extremecase of this example is when a server has just booted, and it is mostly busy with gettingitself up to speed).
To deal with such scenarios, we add an extra dimension, that of "past underutilization",modeled by "storedPermits" variable. This variable is zero when there is nounderutilization, and it can grow up to maxStoredPermits, for sufficiently largeunderutilization. So, the requested permits, by an invocation acquire(permits),are served from:- stored permits (if available)- fresh permits (for any remaining permits)
How this works is best explained with an example:
For a RateLimiter that produces 1 token per second, every secondthat goes by with the RateLimiter being unused, we increase storedPermits by 1.Say we leave the RateLimiter unused for 10 seconds (i.e., we expected a request at timeX, but we are at time X + 10 seconds before a request actually arrives; this isalso related to the point made in the last paragraph), thus storedPermitsbecomes 10.0 (assuming maxStoredPermits >= 10.0). At that point, a request of acquire(3)arrives. We serve this request out of storedPermits, and reduce that to 7.0 (how this istranslated to throttling time is discussed later). Immediately after, assume that anacquire(10) request arriving. We serve the request partly from storedPermits,using all the remaining 7.0 permits, and the remaining 3.0, we serve them by fresh permitsproduced by the rate limiter.
We already know how much time it takes to serve 3 fresh permits: if the rate is"1 token per second", then this will take 3 seconds. But what does it mean to serve 7stored permits? As explained above, there is no unique answer. If we are primarilyinterested to deal with underutilization, then we want stored permits to be given out/faster/ than fresh ones, because underutilization = free resources for the taking.If we are primarily interested to deal with overflow, then stored permits couldbe given out /slower/ than fresh ones. Thus, we require a (different in each case)function that translates storedPermits to throtting time.
This role is played by storedPermitsToWaitTime(double storedPermits, double permitsToTake).The underlying model is a continuous function mapping storedPermits(from 0.0 to maxStoredPermits) onto the 1/rate (i.e. intervals) that is effective at the givenstoredPermits. "storedPermits" essentially measure unused time; we spend unused timebuying/storing permits. Rate is "permits / time", thus "1 / rate = time / permits".Thus, "1/rate" (time / permits) times "permits" gives time, i.e., integrals on thisfunction (which is what storedPermitsToWaitTime() computes) correspond to minimum intervalsbetween subsequent requests, for the specified number of requested permits.
Here is an example of storedPermitsToWaitTime:If storedPermits == 10.0, and we want 3 permits, we take them from storedPermits,reducing them to 7.0, and compute the throttling for these as a call tostoredPermitsToWaitTime(storedPermits = 10.0, permitsToTake = 3.0), which willevaluate the integral of the function from 7.0 to 10.0.
Using integrals guarantees that the effect of a single acquire(3) is equivalentto { acquire(1); acquire(1); acquire(1); }, or { acquire(2); acquire(1); }, etc,since the integral of the function in [7.0, 10.0] is equivalent to the sum of theintegrals of [7.0, 8.0], [8.0, 9.0], [9.0, 10.0] (and so on), no matterwhat the function is. This guarantees that we handle correctly requests of varying weight(permits), /no matter/ what the actual function is - so we can tweak the latter freely.(The only requirement, obviously, is that we can compute its integrals).
Note well that if, for this function, we chose a horizontal line, at height of exactly(1/QPS), then the effect of the function is non-existent: we serve storedPermits atexactly the same cost as fresh ones (1/QPS is the cost for each). We use this trick later.
If we pick a function that goes /below/ that horizontal line, it means that we reducethe area of the function, thus time. Thus, the RateLimiter becomes /faster/ after aperiod of underutilization. If, on the other hand, we pick a function thatgoes /above/ that horizontal line, then it means that the area (time) is increased,thus storedPermits are more costly than fresh permits, thus the RateLimiter becomes/slower/ after a period of underutilization.
Last, but not least: consider a RateLimiter with rate of 1 permit per second, currentlycompletely unused, and an expensive acquire(100) request comes. It would be nonsensicalto just wait for 100 seconds, and /then/ start the actual task. Why wait without doinganything? A much better approach is to /allow/ the request right away (as if it was anacquire(1) request instead), and postpone /subsequent/ requests as needed. In this version,we allow starting the task immediately, and postpone by 100 seconds future requests,thus we allow for work to get done in the meantime instead of waiting idly.
This has important consequences: it means that the RateLimiter doesn't remember the timeof the _last_ request, but it remembers the (expected) time of the next request. Thisalso enables us to tell immediately (see tryAcquire(timeout)) whether a particulartimeout is enough to get us to the point of the next scheduling time, since we alwaysmaintain that. And what we mean by "an unused RateLimiter" is also defined by thatnotion: when we observe that the "expected arrival time of the next request" is actuallyin the past, then the difference (now - past) is the amount of time that the RateLimiterwas formally unused, and it is that amount of time which we translate to storedPermits.(We increase storedPermits with the amount of permits that would have been producedin that idle time). So, if rate == 1 permit per second, and arrivals come exactlyone second after the previous, then storedPermits is _never_ increased -- we would onlyincrease it for arrivals _later_ than the expected one second.