scala,spark的学习门槛还是较高的,scala应该算是我学过的语言中觉得最难的一种了吧(除了英语..)..心蛮类的,总结下经验,希望能够帮助更多小伙伴少走一些弯路吧!
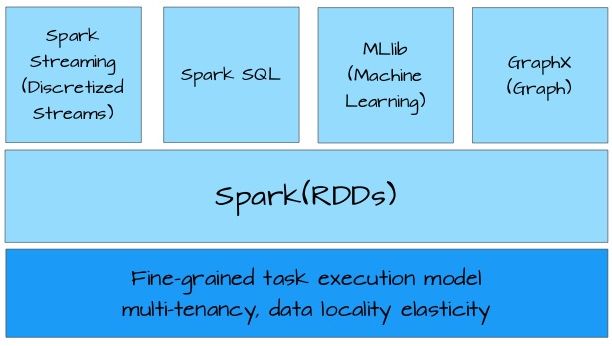
Spark生态圈的五大组件:Spark Core、Spark Streaming、Spark SQL、Spark MLlib和Spark GraphX。
Spark Streaming: 伪实时的流计算,缓冲时间默认为1S,用于实时处理数据。
Saprk Streaming是spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafka、Flume、Twitter等,我用的是Kafka,偶尔看下Flume,从数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,数据库和现场仪表盘。
Spark SQL:应用于数据查询,数据存储.Spark SQL可以对接Hive,实现Spark查询Hive仓库数据的功能,底层走的是Spark core.
Spark SQL可以替换公司90%Hive的工作,平均性能提升3倍+
Spark MLlib: Spark MLlib是Spark的机器学习库,具体算法可以参考我的这边十大数据挖掘的算法..www.jianshu.com/p/9c9abd92b8b8
Spark GraphX:是Spark中的图计算框架组件,有算法PageRank、Louvain、LPA、连通子图等。
其中Spark Core是Spark生态圈的核心组件,其他的四大组件都是基于Spark Core上运行的。
Spark工作机制图解

Cluster Manager:在集群上获取资源的外部服务,分别有Standalone, Spark原生的资源管理,Apache Mesos, 和Hadoop Mapreduce兼容性良好的资源调度框架。
Application: 用户编写的应用应用程序。
Driver: Application中运行main函数并创建的SparkContext, 创建SparkContext的目的是和集群的ClusterManager通讯,进行资源的申请、任务的分配和监控等。所以,可以用SparkContext代表Driver。
Worker:集群中可以运行Application代码的节点。
Executor: 某个Application在Worker上面的一个进程,该进程负责执行某些Task,并负责把数据存在内存或者磁盘上。每个Application都各自有一批属于自己的Executor。
Task:被送到Executor执行的工作单元,和Hadoop MapReduce中的MapTask和ReduceTask一样,是运行Application的基本单位。多个Task组成一个Stage,而Task的调度和管理由TaskScheduler负责。
Job:包含多个Task组成的并行计算,往往由Spark Action触发产生。一个Application可以产生多个Job。
Stage:每个Job的Task被拆分成很多组Task, 作为一个TaskSet,命名为Stage。Stage的调度和划分由DAGScheduler负责。Stage又分为Shuffle Map Stage和Result Stage两种。Stage的边界就在发生Shuffle的地方。
RDD:Spark的基本数据操作抽象,可以通过一系列算子进行操作。RDD是Spark最核心的东西,可以被分区、被序列化、不可变、有容错机制,并且能并行操作的数据集合。存储级别可以是内存,也可以是磁盘。
DAGScheduler:根据Job构建基于Stage的DAG(有向无环任务图),并提交Stage给TaskScheduler。
TaskScheduler:将Stage提交给Worker(集群)运行,每个Executor运行什么在此分配。
共享变量:Spark Application在整个运行过程中,可能需要一些变量在每个Task中都使用,共享变量用于实现该目的。Spark有两种共享变量:一种缓存到各个节点的广播变量;一种只支持加法操作,实现求和的累加变量。
宽依赖:或称为ShuffleDependency, 宽依赖需要计算好所有父RDD对应分区的数据,然后在节点之间进行Shuffle。
窄依赖:或称为NarrowDependency,指某个RDD,其分区partition x最多被其子RDD的一个分区partion y依赖。窄依赖都是Map任务,不需要发生shuffle。因此,窄依赖的Task一般都会被合成在一起,构成一个Stage。
1. 使用spark-submit提交一个Spark作业之后,这个作业就会启动一个对应的Driver进程。
2. Driver根据我们设置的参数(比如说设定任务队列,设定最大内存等)Cluster Manager 申请运行Spark作业需要使用的资源,这里的资源指的就是Executor进程,YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数量的Executor进程,每个Executor进程都占有一定数量的内存和CPU core。
3. 申请到了作业执行所需的资源之后,river进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批task,然后将这些task分配到各个Executor进程中执行,一个stage的所有task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完。
RDD :RDD是Spark Core的唯一组件,它的本质是函数,RDD的转换不过是函数的嵌套!所以RDD是对一个函数的封装,当一个函数对数据处理完成后,我们就得到一个RDD的数据集。
毫无疑问,RDD在Spark里面非常重要的一部分,Spark处理数据的场景都是建立在统一抽象的RDD上面,因此我们可以说RDD是Spark的基石、核心。可以参考下面一张图:
RDD的定义:RDD在抽象上来说是一种元素集合,包含了数据。它是被分区的,分为多个分区,多个分区也就构成了RDD,每个分区分布在集群中的不同节点上,从而让RDD中的数据可以被并行操作。 综上可见,RDD是一个分布式数据集。
RDD在任何时候都能进行重算,因为保存RDD数据的一台机器失败时,Spark可以重算出丢弃的部分分区,转化RDD的时候,是返回新的RDD而不是对现有的RDD进行操作,只有在执行动作的时候返回的是其他数据类型。也就是说RDD是弹性的!结合第一个,RDD就是弹性分布式数据集!
RDD的两种状态:transformation(转换)和action(动作)。
transformation:即从现有的数据集创建一个新的数据集,比如map,它将数据集每一个元素都传递给函数,并返回一个新的分布式数据集表示结果。
action:reduce是一种action,通过一些函数将所有元素叠加起来,并将最终结果返回Driver。
以下是RDD的创建、转换和动作的逻辑计算图
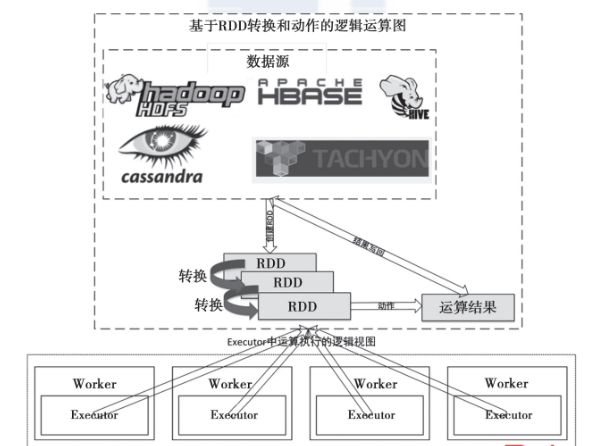
RDD的容错机制:RDD最重要的特性就是,提供了容错性,可以自动从节点失败中恢复过来。即如果某个节点上的RDD partition,因为节点故障,导致数据丢了,那么RDD会自动通过自己的数据来源重新计算该partition。这一切对使用者是透明的。
Spark的代码实现思路:
1. 初始定义的RDD,即你要定义的RDD来自于哪里,比如是HDFS,还是Linux系统中的本地文件或者是集合。
2. 定义对RDD 的计算操作,在spark 中通常称为算子。比如:map 、groupByKey 、reduce 等。
3. 对步骤2中产生的新RDD 进行循环往复定义其它的算子操作。
4. 将最终获得的数据集保存起来。比如存储在数据库或者HDFS上。