本文我们将介绍 Redis 的高级功能,比如:慢查询、PipeLine、BitMap、HyperLogLog、发布订阅 和 GEO 等功能的介绍。
慢查询
生命周期
慢查询的生命周期,可参见下图。首先客户端发送命令给 Redis,Redis 需要对慢查询排队处理,这里需要说明的是慢查询发生在第三阶段,也就是下图的“(3)执行命令”这一阶段。同时客户端超时不一定是慢查询,但却是客户端超时的一个原因。最后,执行完后返回。
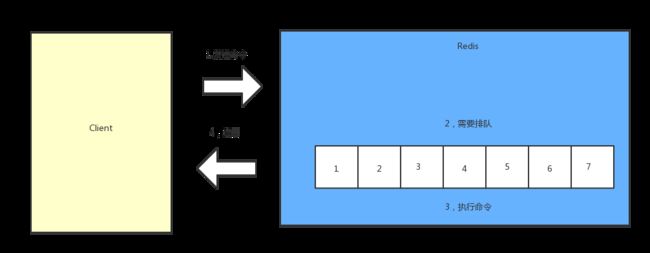
在实际开发中,我们需要对异常进行判断,这个时候,这个流程就显得非常重要。
如何配置慢查询
所谓慢查询指的是内部执行时间超过某个指定时限的查询,而控制该指定时限的就是 Redis 配置文件中的配置项 slowlog-log-slower-than。除 slowlog-log-slower-than 外,在配置文件中还有另外一个参数与慢查询日志有关,那就是 slowlog-max-len,该配置项控制了 Redis 系统最多能够维护多少条慢查询。让我们一个一个讲解。
- slowlog-max-len
服务器使用先进先出的方式保存多条慢查询日志。当服务器储存的慢查询日志数量等于 slowlog-max-len 选项的值时, 服务器在添加一条新的慢查询日志之前,会先将最旧的一条慢查询日志删除。
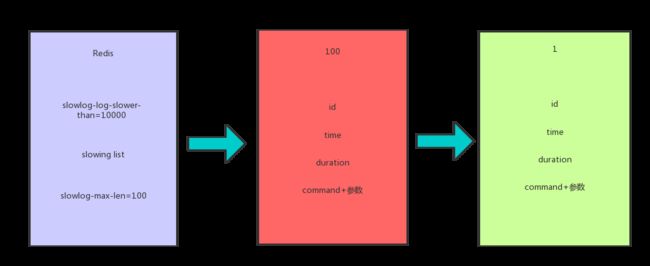
什么意思呢?首先 Redis 会配置一个 slowlog-log-slower-than = 10000,slowlog-max-len = 100,就是说 10000 微秒(1 秒等于 1,000,000 微秒)后是慢查询,然后就把它放到队列(内存)中,并且从 100 开始一直到 1。如下图所示:
- slowlog-log-slower-than
该选项指定执行时间超过多少微秒。
例如,如果这个选项的值为 1000,那么执行时间超过 1000 微秒的命令就会被记录到慢查询日志。如果这个选项的值为 5000,那么执行时间超过 5000 微秒的命令就会被记录到慢查询日志。以此类推。
redis> CONFIG SET slowlog-log-slower-than 0
OK
redis> CONFIG SET slowlog-max-len 10
OK
上面的代码表示,CONFIG_SET 命令将 slowlog-log-slower-than 选项的值设为 0 微秒,这样 Redis 执行的全部命令都会被记录进去,然后将 slowlog-max-len 选项的值设为 10,让服务器最多只保存 10 条慢查询日志。
然后我们发送几个请求:
redis> SET msg "welcome my city"
OK
redis> SET number 12345
OK
redis> SET database "redis"
OK
SLOWLOG GET 命令就可以查看慢日志,如下:
redis> SLOWLOG GET
1) 1) (integer) 4 # 日志的唯一标识符(uid)
2) (integer) 1338784447 # 命令执行时的 UNIX 时间戳
3) (integer) 12 # 命令执行的时长,以微秒计算
4) 1) "SET" # 命令以及命令参数
2) "database"
3) "redis"
2) 1) (integer) 3
2) (integer) 1372181139
3) (integer) 10
4) 1) "SET"
2) "number"
3) "12345"
...
慢查询的默认值
我们在使用 Redis 时,可以设置慢查询的默认值。有以下两种方式。
方式一,请见下面代码。
// 不推荐
config get slowlog-max-len = 128 // 设置slowlog-max-len为128,保存数据最多128条
config get slowlog-log-slower-than = 10000// 表示超时到10000微秒会被记录到日志上
上面的配置是修改配置文件后需要重启,这里不推荐使用此方式。。
方式二,动态配置。配置方式,请见下面两条命令。推荐使用该方式。
// 推荐使用动态配置
config set slowlog-max-len 1000 // 设置slowlog-max-len为1000,保存数据最多1000条,不能太小,也不能太大。
config set slowlog-log-slower-than 10000 // 表示超时到10000微秒会被记录到日志上
慢查询的命令
- slowlog get[n] // 获取慢查询队列
- slowlog len // 获取慢查询队列的长度
- slowlog reset // 清空慢查询队列
对于慢查询,我们在实际使用的时候需要注意以下几点。
1.slowlog-log-slower-than 不要太大,默认是 10ms,实际使用中也只是 1ms 或者 2ms,必须根据 QPS 的大小来设定;
2.slowlog-max-len 不要太小,通常是 1000。默认是 128。因为存在内存中,如果设置过小,会导致之前的慢查询丢失,故建议改成 1000。
3.定期对慢查询进行持久化。
PipeLine 流水线
概念
如果想同时使用 HSET 或者 MSET,那有没有 HMSET 呢?实际上是没有的,但是我们可以使用 PipeLine 流水线功能。
如果使用 n 次网络请求加 n 次命令就很麻烦,但是如果使用 PipeLine 的 1 次网络请求加 n 次命令,就可以节约网络带宽和访问时间。但是 PipeLine 每次条数要控制。
如何使用 PipeLine
这里我们介绍在 Jedis 中使用 PipeLine,我们通过使用 PipeLine 和不使用 PipeLine 作对比,你就能清晰的感受 PipeLine 的方便了。
第一种方式用 HSET,就是我们不用 PipeLine 的时候,代码如下
Jedis jedis = new Jedis("127.0.0.1",6379); // new一个redis,它提供IP和端口号的参数;
for(int i=0;i<10000;i++){
jedis.hset("keyvalue:"+i,"keyfield"+i);
} // 测试后发现,1w的hset需要50s
第二种使用 PipeLine 方式,代码如下
Jedis jedis = new Jedis("127.0.0.1",6379);// new一个redis,它提供IP和端口号的参数;
for(int i=0;i<100;i++){
Pipeline pipeline = jedis.pipelined();// 此句就是使用pipelined方法,激活pipeline
for(int j=i*100;j<(i+1)*100;j++){
pipeline.hset("key"+j,"keyfield"+j,"keyvalue"+j);
}
pipeline.syncAndReturnAll();//结束的时候必须要加的。
} // 测试发现,1w的hset只需要0.7s
从上面的代码你就能看到,如果你不使用 PipeLine,这个速度是非常慢的,需要 50 秒;但是如果使用 PipeLine,那么只需要 0.7 秒就能循环出来了。
这里需要注意以下两点。
1.每次 PipeLine 携带的数据量;
2.PipeLine 一次只能在一个 Redis 节点上。在后面的集群部分,我也会进行说明。
BitMap 位图
接下来我们来讲位图功能。我们知道,如果你要 set 一个值,比如 one,那么 one 这个值存放在内存中其实是以二进制的方式,那么我们通过 getbit one 0,就能查询到这个 one 在内存中的第一个二进制是多少。
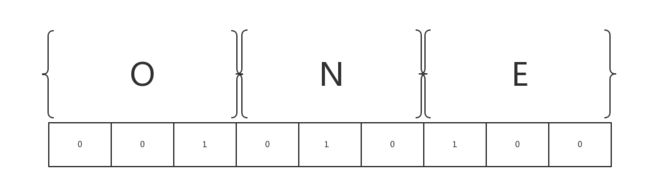
如上图所示,上面的英文字母在内存里都是 0 和 1,那么当我们 getbit one 0 的时候,我们取的就是这个内存中二进制的第一个值,得到的就是 0。
如何使用 BitMap
使用 BitMap,有如下五个命令。
1.SETBIT
setbit key offset value //给位图指定索引设置值
例如,setbit book1:books:2017-01-10 1 1,即将 book1 的 2017 年 1 月 10 日的第一个位图值改为 1,返回结果是之前的值。
2.GETBIT
getbit key offset //获取位图对应的值
例如,getbit book1:books:2017-01-10 1 8,和 SET 类似。
3.BITCOUNT
bitcount key [start end] // 获取位图指定范围值为1的个数
例如,bitcount book1:books:2017-01-10 1 3,返回 3。
4.BITOP
bitop op destkey key [key...]
上面代码表示,进行多个Bitmap的 and,or,not,xor 操作并保存到 destkey中。
5.BITOPS
bitops key targetBit [start] [end] // 计算指定位图范围第一个偏移量对应的值等于targetBit的位置
例如,bitops book1:books:2017-01-10 1 2 5,后面三个数表示 2 到 5 的位置里为 1 的位置。
比较 SET 和 BitMap,很多是使用在统计上的,可见下面两个示例。
示例一,如果你有 1 个亿的用户,每天 5 千万的独立访问。
| 数据类型 | 空间占用 | 存储用户量 | 全部内存占用 |
|---|---|---|---|
| set | 32位 | 50,000,000 | 50,000,000*32 =200M |
| bitmap | 1位 | 100,000,000 | 100,000,000*1=12.5M |
如果你用 SET,一天是 200 M,那么一年就是 72G,但如果你用 BitMap,一年只有 4.5G,你觉得哪个好呢?
示例二,但是如果你只有 10万 独立用户呢?
| 数据类型 | 空间占用 | 存储用户量 | 全部内存占用 |
|---|---|---|---|
| set | 32位 | 1,000,000 | 1,000,000*32 =4M |
| bitmap | 1位 | 100,000,000 | 100,000,000*1=12.5M |
通过上述表格可知,这个时候就要用 SET 了。
所以,BitMap 不一定好,BitMap 是针对大数据量设计的。我们需要根据需求来区分使用,如果数据量非常大,可以考虑,只有在用户量非常大的时候,才会使用。
HyperLogLog
这种算法又叫:极小空间完成独立数量统计。我们日常是不会使用 HyperLogLog 算法的,只有当统计数据量非常大的时候,才会使用它。很多朋友在研究 HyperLogLog 的时候,就会发现 HyperLogLog 本质上还是字符串 String。你不信可以使用 type 命令,就知道 HyperLogLog 返回的是字符串。
如何使用 HyperLogLog
常用的 HyperLogLog 命令有以下三个。
- pfadd key element ...,向HyperLogLog添加元素;
- pfcount key ...,计算HyperLogLog的独立总数;
- pfmerge key1 key2 ...,合并多个HyperLogLog。
发布订阅
有的朋友会问什么是发布订阅,工业生产设计之前是根据非定时的监听设计,定时器会定时在内存中进行监听,如果有改变,再发送,其实不算是实时的。
同时,这种工业设计其实是非常复杂的。发布订阅大大简化了设计流程。很多实时的发布依赖于 Redis 做事件消息推送。简化了设计,而且性能也比较客观。
Redis 在 2.0 之后实现了事件推送的 Pub/Sub 命令。Pub 就是发布者 Publisher,Sub 就是订阅者 Subcriber。
订阅者只要订阅这个频道,就可以实时获得信息,见下图。
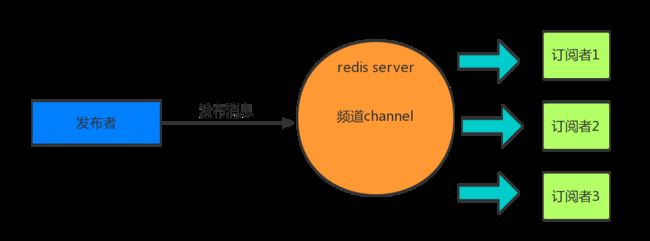
说明:当发布者发送一条消息到 Redis Server 后,只要订阅者订阅了该频道就可以接收到这样的信息。同时,订阅者可以订阅不同的频道。
如何操作 API
使用发布订阅,有如下四个命令。
1.PUBLISH,发布。
publish channel message //发布命令
publish youku:tv "welcome back!" // 返回有几个订阅者。
2.SUBSCRIBE,订阅。
subcribe [channel] // 订阅一个或者多个
subcribe youku:tv // 订阅优酷并返回信息。
3.UNSUBSCRIBE,取消订阅。
unsubcribe [channel] // 取消订阅一个或者多个
unsubcribe youku:tv // 取消订阅优酷并返回信息。
4.其他命令还有 PSUBSCRIBE(订阅模式)、PUNSUBSCRIBE(退订指定模式)、PUBSUB CHANNELS(列出至少一个订阅者频道)
补充:消息队列
Redis 消息队列是抢的模式,就是只有一个用户能收到,谁网速快,谁人品好,谁就能获得那条消息,作为开发者我们需要了解需求,如果只需要一个消息订阅者收到,那么就可以使用消息队列,如下图所示。

这种场景比如抢红包、谁中奖这种模式,就可以使用消息队列了。
GEO 地理位置存储
Redis 3.2 以后才出现 GEO 的功能。GEO 是使用 ZSET 来实现的。最常用的功能就是微信里的附近的人和摇一摇的功能,还有美团通过本地的坐标自动识别周围的餐馆等功能。
如何操作 API
使用GEO,有如下四个命令。
1.GEOADD,增加。
geo add 经度 维度 标识 ...
例如,geo add cities:location 117.20 40.11 beijing。
2.GEOPOS,获取地理信息。
geopos key 标识 ...
例如,geopos cities:locations beijing,返回经度和纬度。
3.GEODIST,计算距离
geodist key 标识1 标识2 ... [unit] // unit表示单位
例如,geodist cities:locations beijing tianjing km //计算北京到天津的距离
4.GEORADIUS,它是非常复杂的,如果你有兴趣可以访问该网页找到详细内容。
后面的内容,将对 Redis 的持久化、高可用、分布式进行详细讲解。