1、HDFS HA 配置主要涉及几点
1)多NameNode配置,唯一为active,其他为standby
2)多个NameNode对EditLogs文件的共享:JournalNode
3)fence:任意时刻只能仅有一台NameNode向外提供服务
4)NameNode在client的proxy
2、按照官方文档步骤一步一步来操作
1)配置hdfs-site.xml文件
dfs.nameservices
luozhengcluster
dfs.ha.namenodes.luozhengcluster
nn1,nn2,nn3
dfs.namenode.rpc-address.luozhengcluster.nn1
luozheng.bigdata:8020
dfs.namenode.rpc-address.luozhengcluster.nn2
luozheng.bigdata1:8020
dfs.namenode.rpc-address.luozhengcluster.nn3
luozheng.bigdata2:8020
dfs.namenode.http-address.luozhengcluster.nn1
luozheng.bigdata:9870
dfs.namenode.http-address.luozhengcluster.nn2
luozheng.bigdata1:9870
dfs.namenode.http-address.luozhengcluster.nn3
luozheng.bigdata2:9870
dfs.namenode.shared.edits.dir
qjournal://luozheng.bigdata:8485;luozheng.bigdata1:8485;luozheng.bigdata2:8485/luozhengcluster
dfs.client.failover.proxy.provider.luozhengcluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/home/luozheng/.ssh/id_rsa
2)配置core-site.xml
fs.defaultFS
hdfs://luozhengcluster
dfs.journalnode.edits.dir
/home/luozheng/tools/hadoop-3.0.1/data/journal
hadoop.tmp.dir
/home/luozheng/tools/hadoop-3.0.1/data/tmp
fs.trash.interval
10080
io.file.buffer.size
4096
3)启动步骤
3.0)通过以下命令把相关文件同步到其他节点上
scp -r etc/ data/ [email protected]:/home/luozheng/tools/hadoop-3.0.1/
scp -r etc/ data/ [email protected]:/home/luozheng/tools/hadoop-3.0.1/
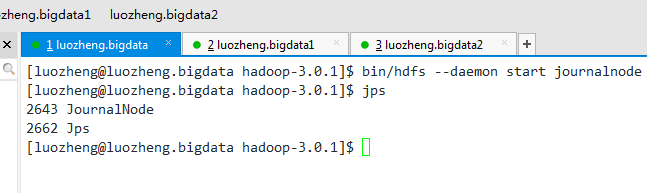
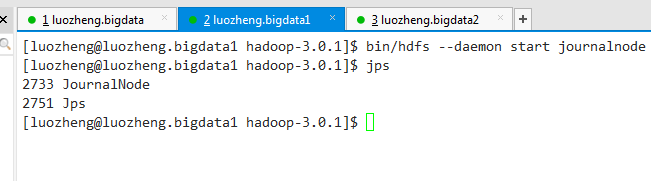
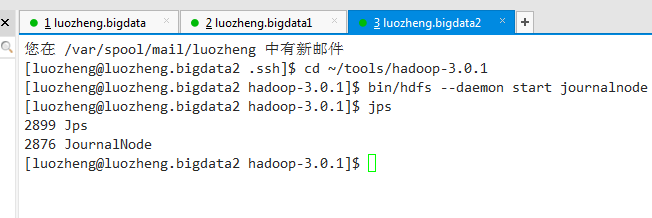
3.1)通过以下命令依次启动所有journalnode守护进程
bin/hdfs --daemon start journalnode
3.2) 通过以下命令在luozheng.bigdata节点格式化namenode并启动namenode
bin/hdfs namenode -format
bin/hdfs --daemon start namenode
3.3)在luozheng.bigdata1和luozheng.bigdata2节点通过以下命令同步the contents of NameNode metadata directories,这里luozheng.bigdata1和luozheng.bigdata2都要同步是因为搭建的HA是有三个NameNode的。
bin/hdfs namenode -bootstrapStandby
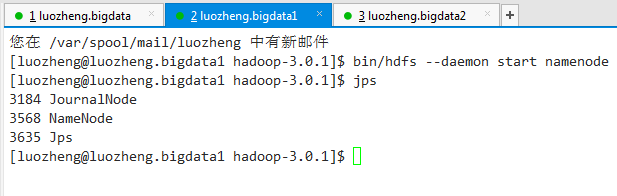
3.4)通过以下命令依次启动其他NameNode
bin/hdfs --daemon start namenode

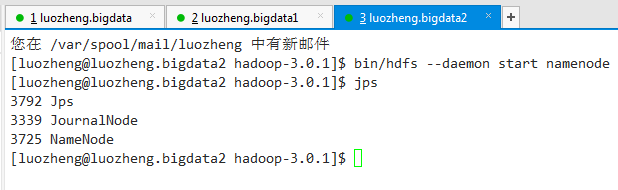
3.5)依次启动datanode
bin/hdfs --daemon start datanode
启动结束后,在浏览器中敲入http://luozheng.bigdata:9870,http://luozheng.bigdata1:9870,http://luozheng.bigdata2:9870,可以看到3个节点都启动起来了。

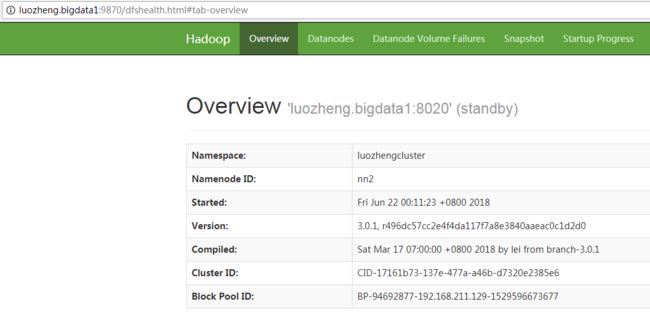
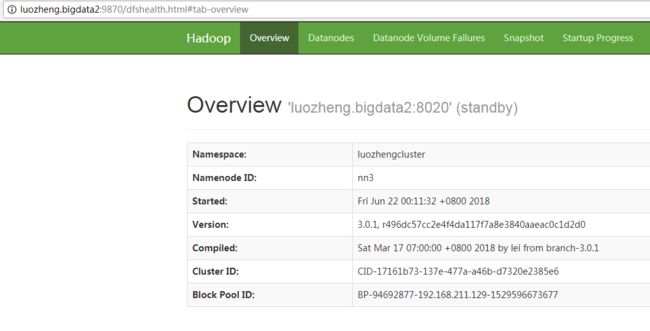
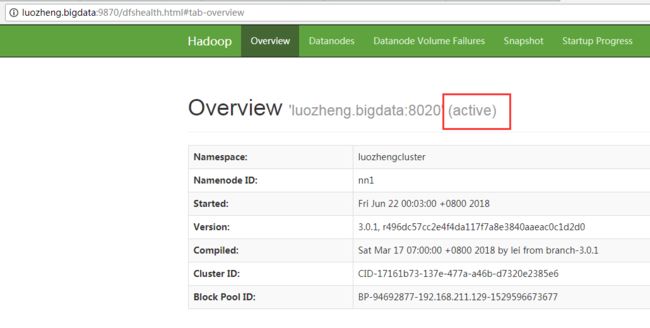
3.6) 让指定的namenode状态为active
bin/hdfs haadmin -transitionToActive nn1
4、Automatic Failover
namenode active和standby状态的切换,除了通过手动敲命令来实现,还可以通过zookeeper来实现自动故障转移,zookeeper通过ZKFailoverController来实时的监控namenode的运行状态,从而实现故障转移。
4、1)相关配置,先在hdfs-site.xml文件中加入如下内容:
dfs.ha.automatic-failover.enabled
true
4、2)在core-site.xml配置文件中加入如下配置信息:
ha.zookeeper.quorum
luozheng.bigdata:2181,luozheng.bigdata1:2181,luozheng.bigdata2:2181
4、3)同步配置文件到其他节点
scp -r core-site.xml hdfs-site.xml [email protected]:/home/luozheng/tools/hadoop-3.0.1/etc/hadoop/
scp -r core-site.xml hdfs-site.xml [email protected]:/home/luozheng/tools/hadoop-3.0.1/etc/hadoop/
4、4)如果HDFS文件系统是处于运行状态,先通过如下命令stop
sbin/stop-dfs.sh
4、5)到zookeeper安装目录,依次启动zookeeper服务
bin/zkServer.sh start
4、6)初始化HA在zookeeper状态
bin/hdfs zkfc -formatZK
4、7)启动HDFS集群
sbin/start-dfs.sh
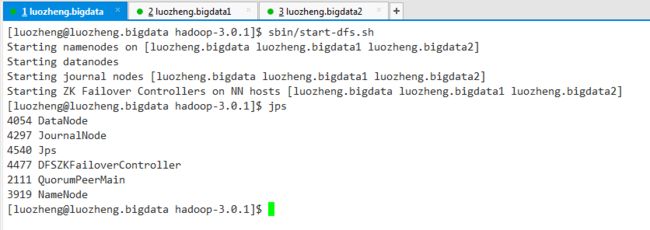
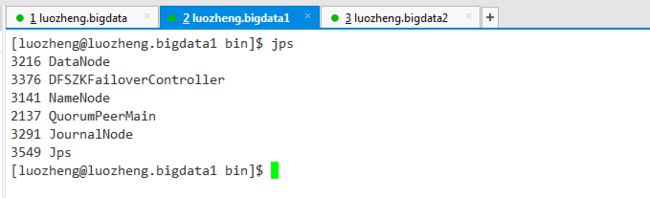
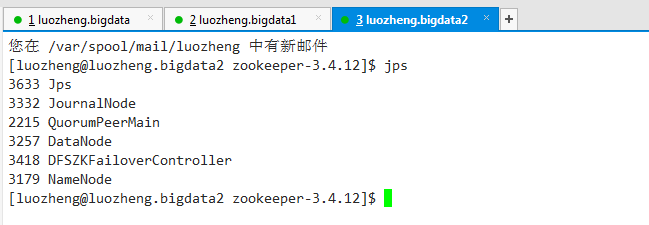
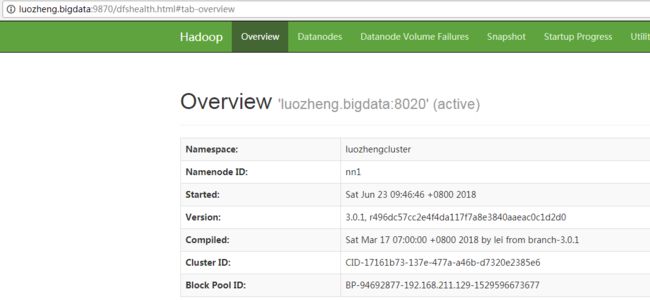
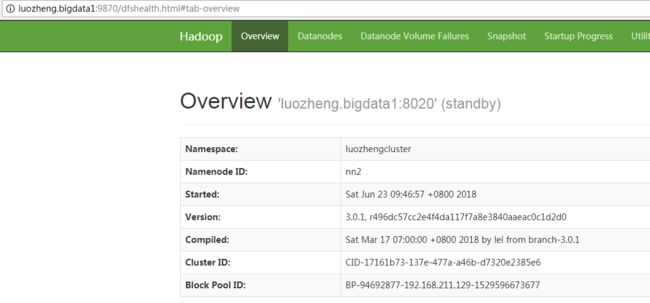
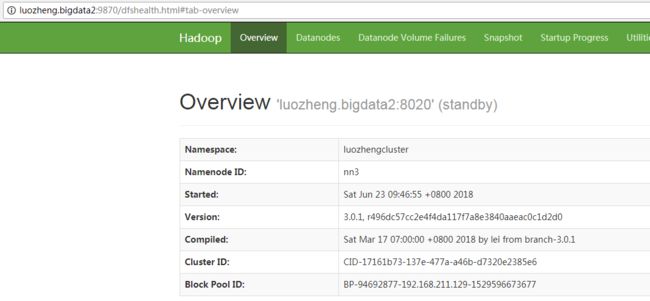
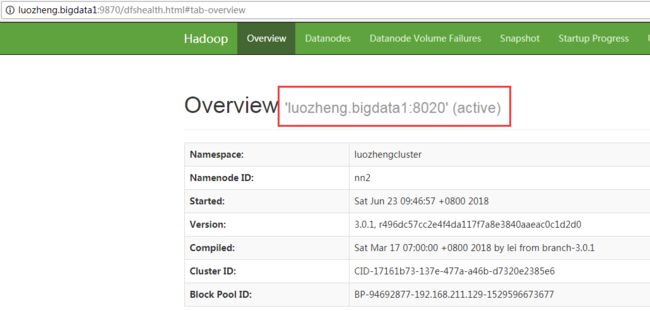
zookeeper自动选举了luozheng.bigdata节点中的namenode作为active namenode
现在强制kill掉该节点的namenode进程,测试下Automatic Failover
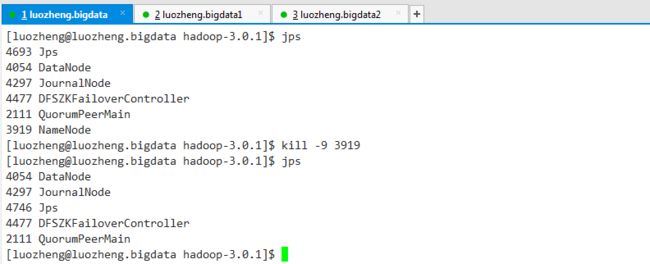
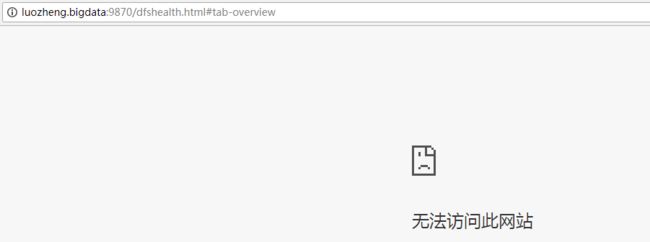

5、最后补充一点hadoop的高级特性
1)Federation:目前HDFS系统中,任意时刻都只有一台namenode向外提供服务,Federation可以让多个namenode同时向外提供服务,具体看官方文档
2)HDFS快照
3)缓存管理
4)DistCp:分布式数据拷贝工具,官方文档
总结,到此,hadoop基本先告一段落,在学习的过程中,基本是以熟悉框架为主,先有个大概的概念,对于里面很多的原理基本没有涉及,这个考虑的是在熟悉整个hadoop生态圈后,再慢慢通过官方文档或是其他书籍来补充,先要快速熟悉它们!