系列文章
python爬虫实战(1) -- 抓取boss直聘招聘信息
python爬虫实战(2) -- MongoDB和数据清洗
python爬虫实战(3) -- 数据可视化
实验内容:讲爬取的boss直聘岗位信息放入MongoDB中,清洗数据
参考:https://segmentfault.com/a/1190000012414154
环境
MAC book air
MongoDB 3.4.7 数据库
MongoBooster 4.6.1 数据库可视化工具
0 安装MongoDB
参考 https://www.jb51.net/article/64996.htm
pip install pymongo
今天用pip和canda安装了pymongo,但是不会用 /哭
命令行敲mongo还是pymongo都不行
又找不到bin文件安装目录(/usr/local/mongodb/bin下面没有!),折腾了两个小时,气死了
最后用curl去官网down安装包,采用安装包方式安装,这样我才能知道装在哪个文件夹下面
墙外慢悠悠下载中。。。
今天先睡了,这个坑留到明天吧
————
用curl的方式安装成功,真不容易,方式如下
(官网下载MongoDB很慢,我提供一个下载链接
mongodb-osx-x86_64-3.4.7
链接: https://pan.baidu.com/s/1VPZap-u_3LWoVVtwC9CEFg 密码: 6h4y)
接下来我们使用 curl 命令来下载安装:
# 进入 /usr/local
cd /usr/local
# 下载
sudo curl -O https://fastdl.mongodb.org/osx/mongodb-osx-x86_64-3.4.2.tgz
# 解压
sudo tar -zxvf mongodb-osx-x86_64-3.4.2.tgz
# 重命名为 mongodb 目录
sudo mv mongodb-osx-x86_64-3.4.2 mongodb
安装完成后,我们可以把 MongoDB 的二进制命令文件目录(安装目录/bin)添加到 PATH 路径中:
export PATH=/usr/local/mongodb/bin:$PATH
运行 MongoDB
1、首先我们创建一个数据库存储目录 /data/db:
sudo mkdir -p /data/db
启动 mongodb,默认数据库目录即为 /data/db:
sudo mongod
# 如果没有创建全局路径 PATH,需要进入以下目录
cd /usr/local/mongodb/bin
sudo ./mongod
再打开一个终端进入执行以下命令:
$ cd /usr/local/mongodb/bin
$ ./mongo
MongoDB shell version v3.4.2
connecting to: mongodb://127.0.0.1:27017
MongoDB server version: 3.4.2
Welcome to the MongoDB shell.
……
> 1 + 1
2
>
注意:如果你的数据库目录不是/data/db,可以通过 --dbpath 来指定。
1 导入职位数据到MongoDB中
1.1 通过./mongoimport命令导入数据(pwd是你的mongo安装路径)
#开启数据库后台服务,指定数据库位置,以及打印日志位置
#注意是在超级用户权限下
sh-3.2# ./mongod --dbpath /Users/limingxuan/Documents/GitHub/py03_web_crewler_advanced/www_zhipin_com/data/db/ --logpath /Users/limingxuan/Documents/GitHub/py03_web_crewler_advanced/www_zhipin_com/data/db/log --fork
about to fork child process, waiting until server is ready for connections.
forked process: 15370
child process started successfully, parent exiting
#将职位数据item.json导入数据库中
sh-3.2# ./mongoimport --db zhipin_jobs --collection Python_jobs --file /Users/limingxuan/Documents/GitHub/py03_web_crewler_advanced/www_zhipin_com/item.json --jsonArray
2018-07-20T07:48:36.889+0800 connected to: localhost
2018-07-20T07:48:36.955+0800 imported 30 documents
1.2数据库可视化
打开MongoBooster,连接数据库mongodb://127.0.0.1:27017
nosqlbooster4mongo-4.6.1下载链接:
https://pan.baidu.com/s/1BSsQNCiR8i_ZZm-uJiyh3g 密码: k4ma
可以看到已经导入进去的数据
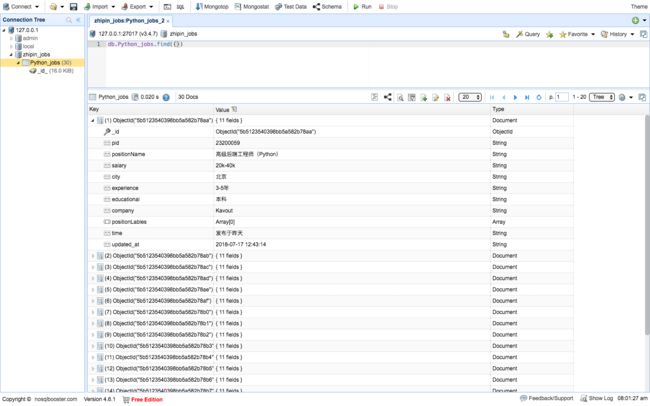
MongoDB常用命令
show dbs 显示所有数据库
show collections 显示数据库中的集合(类似关系数据库中的表)
db.dropDatabase() 删除当前使用的数据库
use切换当前数据库
02 爬取岗位介绍和要求
2.1 获取岗位详情页面链接
“data-jobid = 16651234”是岗位序列字段,插入下列链接即可进入岗位页面
https://www.zhipin.com/job_detail/16651234.html
上面方法在改版后的网页中不好用了,经过我的测试,改用data-jid作为岗位序列可用。
因此这一步先根据数据库中每条数据的pid取出data-jid,插入链接中
获得岗位详情页面链接
以下是我抓取的结果,都可以打开连接
https://www.zhipin.com/job_detail/1b05e1c6159a5c641Xd53Nu7FFQ~.html
https://www.zhipin.com/job_detail/31651720be45f7991Xd53dy5EFM~.html
https://www.zhipin.com/job_detail/31d68c1af825968e1Xd52NW5ElE~.html
https://www.zhipin.com/job_detail/38322dc76e03f8051Xd42Nq-GFs~.html
https://www.zhipin.com/job_detail/44d97f823d37026c1Xd-2d-0FlE~.html
第一阶段顺利打印出岗位页面的url
关于requests的用法
http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
import requests
cs_url = 'http://httpbin.org'
r = requests.get("%s/%s" % (cs_url, 'get'))
r = requests.post("%s/%s" % (cs_url, 'post'))
r = requests.put("%s/%s" % (cs_url, 'put'))
r = requests.delete("%s/%s" % (cs_url, 'delete'))
r = requests.patch("%s/%s" % (cs_url, 'patch'))
r = requests.options("%s/%s" % (cs_url, 'get'))
https://liam0205.me/2016/02/27/The-requests-library-in-Python/
当我们使用 requests.* 发送请求时,Requests 做了两件事:
构建一个 Request 对象,该对象会根据请求方法或相关参数发起 HTTP 请求
一旦服务器返回响应,就会产生一个 Response 对象,该响应对象包含服务器返回的所有信息,也包含你原来创建的 Request 对象
对于响应状态码,我们可以访问响应对象的 status_code 属性:
import requests
r = requests.get("http://httpbin.org/get")
print r.status_code
# 输出
200
对于响应正文,我们可以通过多种方式读取,比如:
普通响应,使用 r.text 获取
JSON 响应,使用 r.json() 获取
二进制响应,使用 r.content 获取
原始响应,使用 r.raw 获取
参考:http://funhacks.net/explore-python/HTTP/Requests.html
小知识:
对于python代码中的if __name__ == '__main__'
我们简单的理解就是: 如果模块是被直接运行的,则代码块被运行,如果模块是被导入的,则代码块不被运行。
2.2 爬取详情页中的岗位介绍和要求
大致流程如下:
- 从代码中取出pid
- 根据pid拼接网址 => 得到 detail_url
使用requests.get
防止爬虫挂掉,一旦发现爬取的detail重复,就重新启动爬虫 - 根据detail_url获取网页html信息 => requests - > html
使用BeautifulSoup
若爬取太快,就等着解封
if html.status_code!=200
print('status_code if {}'.format(html.status_code)) - 根据html得到soup => soup
- 从soup中获取特定元素内容 => 岗位信息
- 保存数据到MongoDB中
# @author: limingxuan
# @contect: [email protected]
# @blog: https://www.jianshu.com/p/a5907362ba72
# @time: 2018-07-21
import requests
from bs4 import BeautifulSoup
import time
from pymongo import MongoClient
headers = {
'accept': "application/json, text/javascript, */*; q=0.01",
'accept-encoding': "gzip, deflate, br",
'accept-language': "zh-CN,zh;q=0.9,en;q=0.8",
'content-type': "application/x-www-form-urlencoded; charset=UTF-8",
'cookie': "JSESSIONID=""; __c=1530137184; sid=sem_pz_bdpc_dasou_title; __g=sem_pz_bdpc_dasou_title; __l=r=https%3A%2F%2Fwww.zhipin.com%2Fgongsi%2F5189f3fadb73e42f1HN40t8~.html&l=%2Fwww.zhipin.com%2Fgongsir%2F5189f3fadb73e42f1HN40t8~.html%3Fka%3Dcompany-jobs&g=%2Fwww.zhipin.com%2F%3Fsid%3Dsem_pz_bdpc_dasou_title; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1531150234,1531231870,1531573701,1531741316; lastCity=101010100; toUrl=https%3A%2F%2Fwww.zhipin.com%2Fjob_detail%2F%3Fquery%3Dpython%26scity%3D101010100; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1531743361; __a=26651524.1530136298.1530136298.1530137184.286.2.285.199",
'origin': "https://www.zhipin.com",
'referer': "https://www.zhipin.com/job_detail/?query=python&scity=101010100",
'user-agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36"
}
conn = MongoClient('127.0.0.1',27017)
db = conn.zhipin_jobs
def init():
items = db.Python_jobs.find().sort('pid')
for item in items:
if 'detial' in item.keys(): #当爬虫挂掉时,跳过已爬取的页
continue
detail_url = 'https://www.zhipin.com/job_detail/{}.html'.format(item['pid']) #单引号和双引号相同,str.format()新格式化方式
#第一阶段顺利打印出岗位页面的url
print(detail_url)
#返回的html是 Response 类的结果
html = requests.get(detail_url,headers = headers)
if html.status_code != 200:
print('status_code is {}'.format(html.status_code))
break
#返回值soup表示一个文档的全部内容(html.praser是html解析器)
soup = BeautifulSoup(html.text,'html.parser')
job = soup.select('.job-sec .text')
print(job)
#???
if len(job)<1:
continue
item['detail'] = job[0].text.strip() #职位描述
location = soup.select(".job-sec .job-location .location-address")
item['location'] = location[0].text.strip() #工作地点
item['updated_at'] = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime()) #实时爬取时间
#print(item['detail'])
#print(item['location'])
#print(item['updated_at'])
res = save(item) #调用保存数据结构
print(res)
time.sleep(40)#爬太快IP被封了24小时==
#保存数据到MongoDB中
def save(item):
return db.Python_jobs.update_one({'_id':item['_id']},{'$set':item}) #why item ???
# 保存数据到MongoDB
if __name__ == '__main__':
init()
2018-07-23最新补充
由于之前设置睡眠4秒,爬取详情页才爬了30多个,就被封了IP 24小时。
暂时调整成了40秒,明天继续爬
后续再次实践的时候可以考虑参考使用代理IP池爬虫的方法
https://github.com/hjlarry/bosszhipin
最终结果就是在MongoBooster中看到新增了detail和location的数据内容

03 清洗数据
将salary拆分成low,high,avg
将发布时间统一成2018-07-xx格式
将工作经验统一成直聘格式,并且设置对应的level等级
以上完全按照原链接中的方法完成的,代码如下:
# @author: limingxuan
# @contect: [email protected]
# @blog: https://www.jianshu.com/p/a5907362ba72
# @time: 2018-07-23
# coding: utf-8
# In[83]:
import datetime
from pymongo import MongoClient
# In[84]:
conn = MongoClient('127.0.0.1',27017)
db = conn.zhipin_jobs
print(conn)
# In[85]:
def update(item):
return db.Python_jobs.update_one({"_id": item['_id']}, {"$set": item})
#时间统一格式
def clear_time():
items = db.Python_jobs.find({})
for item in items:
if not item['time'].find("布于"):
continue
item['time'] = item['time'].replace("发布于","2017-")
item['time'] = item['time'].replace("月","-")
item['time'] = item['time'].replace("日","")
if item['time'].find("昨天") > 0:
item['time'] = str(datetime.date.today() - datetime.timedelta(days = 1))
elif item['time'].find(":") > 0:
item['time'] = str(datetime.date.today())
update(item)
print(ok)
#print(item['time'])
#薪资统一格式,计算平均值
def clear_salary():
items = db.Python_jobs.find({})
for item in items:
if type(item['salary']) == type({}):
continue
salary_list = item['salary'].lower().replace('k','000').split("-")
if len(salary_list) != 2:
print(salary_list)
continue
try:
salary_list = [int(x) for x in salary_list]
except:
print(salary_list)
continue
item['salary'] = {
'low':salary_list[0],
'high':salary_list[1],
'avg':(salary_list[0] + salary_list[1])/2
}
update(item)
print('ok')
# 设置招聘的水平,分两次执行
def set_level():
items = db.Python_jobs.find({})
for item in items:
if item['experience'] == '应届生':
item['level'] = 1
elif item['experience'] == '1年以内':
item['level'] = 2
elif item['experience'] == '1-3年':
item['level'] = 3
elif item['experience'] == '3-5年':
item['level'] = 4
elif item['experience'] == '5-10年':
item['level'] = 5
elif item['experience'] == '10年以上':
item['level'] = 6
elif item['experience'] == '不限':
item['level'] = 10
update(item)
print('ok')
if __name__ == '__main__':
clear_time()
clear_salary()
set_level()
暂时还没办法将岗位detail拆分成岗位职责和任职要求(原作者没做,我就先略过)
预告
下一篇:python爬虫实战(3) -- 数据可视化