MySQL
主要介绍了数据表记录查询和多表记录查询基本方法。谢阅!
一.MySQL概述
1.数据库概述
数据库就是一个文件系统,通过标准的SQL语句获取数据
2.SQL语言
结构化查询语言
DDL:数据定义语言
create,drop,alter..
DCL:数据控制语言
grant,if…
DML:数据操纵语言
insert,update,delete…
DQL:数据查询语言
Select
3.MySQL
关系型数据库。
一个项目创建一个数据库,一个数据库类有许多表,一个表内有多条记录。
在这里我们引入一种ER模型,E指的是Entity Relation(实体关系)。实体类似于Java中的类,一个类创建一个表,表中的字段的类似于类中的属性。类与类之间存在某种关系(关系有一对多,多对多)。当创建一个实体的实例的时候就在数据库中加入了一条表记录。
二.MySQL入门操作
1.连接与断开服务器
为了连接服务器,当调用mysql时,通常需要提供一个MySQL用户名并且很可能需要一个密码。如果服务器运行在登录服务器之外的其它机器上,还需要指定主机名。联系管理员以找出进行连接所使用的参数 (即,连接的主机、用户名和使用的密码)。知道正确的参数后,可以按照以下方式进行连接:
shell> mysql -h host -u user -p
Enter password: ********
2.输入查询
命令之间用逗号隔开,以分号结束指令。
mysql> SELECT VERSION(), CURRENT_DATE;
3.创建并使用数据库
使用SHOW语句找出服务器上当前存在什么数据库:
mysql> SHOW DATABASES;
利用USE访问已存在的数据库:
mysql> USE test;
①创建数据库
mysql> create database menagerie;
数据库名称是区分大小写的(不像SQL关键字),创建数据库并不表示选定并使用它,你必须明确地操作。为了使menagerie成为当前的数据库,使用这个命令:
mysql> USE menagerie;
Database changed;
数据库只需要创建一次,但是必须在每次启动mysql会话时在使用前先选择它。你可以根据上面的例子执行一个USE语句来实现。
②创建数据库表
创建数据库是很容易的部分,但是在这时它是空的,正如SHOW TABLES将告诉你的:
mysql> SHOW TABLES;
Empty set (0.00 sec)
较难的部分是决定你的数据库结构应该是什么:你需要什么数据库表,各数据库表中有什么样的列。
创建一个表,申明表明,并给表中列元素申明类型
mysql> CREATE TABLE pet (name VARCHAR(20), owner VARCHAR(20),
-> species VARCHAR(20), sex CHAR(1), birth DATE, death DATE);
VARCHAR适合于name、owner和species列,因为列值是变长的。这些列的长度不必都相同,而且不必是20。
③装载数据到数据库表
如果想要一次增加一个新记录,可以使用INSERT语句。最简单的形式是,提供每一列的值,其顺序与CREATE TABLE语句中列的顺序相同。假定Diane把一只新仓鼠命名为Puffball,你可以使用下面的INSERT语句添加一条新记录:
mysql> INSERT INTO pet
-> VALUES ('Puffball','Diane','hamster','f','1999-03-30',NULL);
注意,这里字符串和日期值均为引号扩起来的字符串。另外,可以直接用INSERT语句插入NULL代表不存在的值。
三.以各种方法从表中检索数据
> mysql -h host -u user -p
Enter password: ********
mysql> show databases;
mysql> create database db01;
mysql> use db01;
database changed;
mysql> show tables;
Empty set (0.00 sec)
mysql> create table student (name varchar(20), math int,english int,chinese int);
mysql> insert into student values(‘jack’,80,98,99);
mysql> insert into student values(‘back’,81,98,91);
mysql> insert into student values('cack',,82,98,92);
mysql> insert into student values('dack',,80,93,92);
mysql> insert into student values('fack',,80,94,93);
insert into student values('jack',80,90,98);
SELECT语句用来从数据表中检索信息。语句的一般格式是:
SELECT what_to_select
FROM which_table
WHERE conditions_to_satisfy;
what_to_select指出你想要看到的内容,可以是列的一个表,或*表示“所有的列”。which_table指出你想要从其检索数据的表。WHERE子句是可选项,如果选择该项,conditions_to_satisfy指定行必须满足的检索条件。
1.基本查询(查询字段)
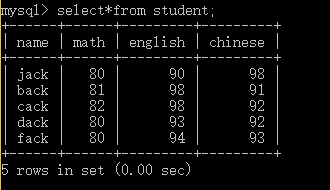
查询所有学生考试成绩信息
select * from student;
查询英语成绩信息(不显示重复的值)
select distinct english from exam;
查看学生姓名和学生的总成绩
select name,english+chinese+math from exam;
2.条件查询
使用where关键字表示条件查询
Select*from student where english >90;
模糊查询使用like关键字
Select*from student where name like ‘%ac%’;
使用in表示查询范围
Select*from student where math in(93,94,95);
利用and和or表示逻辑关系进行条件选择
3.排序查询(order by)
使用order by对数据按照需求进行排序(asc表示升序,desc表示降序)
Select*from student order by math asc;
4.聚合函数
sum(字段名); 查询某一列数据总和
max(字段名),计算最大值
min(字段名),计算最小值
count(字段名),统计记录条数
avg(字段名),计算平均值
聚合函数都是对列进行操作的(因为表中只用列严格规定数据类型相同,所以对列进行操作可以避免很多问题,如数据为null的情况)
5. 分组查询
Use db01;
CREATE TABLE goods(
brand VARCHAR(20),
product VARCHAR(20),
price DOUBLE
)
INSERT INTO goods VALUES('小米','手机',2999);
INSERT INTO goods VALUES('小米','手机',3999);
INSERT INTO goods VALUES('小米','手机',4999);
INSERT INTO goods VALUES('小米','电视',2999);
INSERT INTO goods VALUES('小米','电视',2999);
INSERT INTO goods VALUES('小米','电视',4999);
INSERT INTO goods VALUES('华为','手机',2999);
INSERT INTO goods VALUES('华为','手机',5999);
INSERT INTO goods VALUES('OPPO','手机',2999);
INSERT INTO goods VALUES('海尔','电视',2999);
按品牌分组排序,显示每个品牌的产品数量
Select brand,count(brand) from goods group by brand;
按品牌分组,显示每个品牌每个产品的数目
select brand,count(*) from goods group by brand,product;
四.外键
实际操作的过程中一个数据库内有许多表,表与表之间存在一对多,多对多,一对一之间的关系。
1、单表之间的约束是:用来规范数据的完整性的,有“主键约束(primary key)”,“唯一约束(unique)”,“非空约束(not null)”
2、多表之间的约束是:用来表示多表之间的关系,保持数据的一致性和完整性。外键:如果一个表中的某个字段与另一个表中的主键字段有关系,那么就需要给这个字段添加外键并指向有关系的主键。
例如一个表为班(班级名,班人数),一个表为学生(班级名,成绩,姓名)。
在学生表里面建立一个外键: foreign key (班级名) reference 班(班级名);
1.一对多情况:
一个班有多个学生,一个学生只能有一个班,所以外键创建在学生表中
2.多对多情况:
一个学生可以选多门课,一门课也可以被多个学生选择。所以需要创建一个中间表,中间表记录了每个学生选每门课的情况。中间表的学生创建外键绑定学生表,中间表的课程创建外键绑定课程表。
五.多表查询
有的时候我们在数据库中查询信息往往需要从多个表中一起查询,因此需要多表联合查询。多表查询分为连接查询(join)和子查询。
1.连接查询
连接查询分为交叉连接(cross join)、内连接(inner join)、外连接(outer join)。交叉查询是把两个表的所有表记录进行拼接,内连接是把两个表中都包含的表记录进行拼接,外连接是把两个表中相同的表记录进行拼接,同时可以保留某些表特有的表记录(left outer join 保留的是左表特有记录)
a)交叉连接: 查询到的是两个表的笛卡尔积,使用cross join关键字。
语法:
①select * from 表1 cross join 表2;
②select * from 表1,表2;
b)内连接:使用inner join…on关键字(inner可以省略)
i.显式内连接:在sql中使用了inner join…on关键字
语法:select * from表1 inner join 表2 on 关联条件;
ii.隐式内连接:在sql中没有使用了inner join关键字
语法:select * from表1,表2 where 关联条件;
c)外连接:使用left/right outer join…on关键字(outer可以省略)
i.左外连接:使用left outer join…on关键字
语法:select * from表1 left outer join 表2 on 连接条件;
ii.右外连接:使用right outer join…on关键字
语法:select * from表1 right outer join 表2 on 连接条件;
2.子查询
一个查询语句的条件需要依赖另一个查询语句的结果就叫子查询,也就是说sql语句可以嵌套使用。
现在有三个表,学生表student,学生成绩表stu_cour,课程表course。

现在查询参加考试学生的成绩(内联)
SELECT *FROM student s JOIN stu_cour sc ON s.sid = sc.sid JOIN course c ON sc.cid=c.cid ORDER BY s.sid;
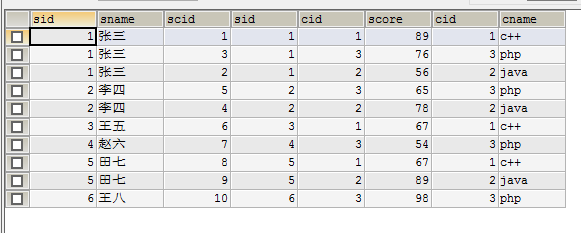
现在查询每个学生的成绩情况(外联)
SELECT*FROM student s LEFT JOIN (stu_cour sc JOIN course c ON sc.cid= c.cid ) ON s.sid = sc.sid ORDER BY s.sid;

当需要对一个表本身联合查询的时候会用到自连接。
其实在这些查询中,我们创建了很多中间表,对中间表进行了操作。表和表之间是按照指定的条件进行拼接的,所有的连接查询都是在Cross连接的基础上过滤了一些不满足条件的表数据。多表查询的内在机制是按照条件将多个表合并成一个表,在一个表里查询需需要的表记录。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
事务的四大特性:
A:原子性:组成事务的最小单元是不可分割的,要么同时成功要么同时失败。
C:一致性:执行事务前后,数据的完整性是一致的;(也就是案例中总钱数是一样的)
I:隔离性:在数据库中,各个事务之间是独立的,不受其他事务的影响。
D:持久性:事务一旦结束,数据就会持久保存到数据库中。
事务的隔离级别:
脏读:一个事务读到了另一个事务未提交的数据。
不可重复读:一个事务读到了另一个事务已经提交的update数据
虚读/幻读:一个事务读到了另一个事务已经提交的insert数据
事务的隔离级别:
read uncommitted(未提交读):脏读,不可重复读,虚读都有可能发生
read committed(已提交读):避免脏读。但是不可重复读和虚读是有可能发生
repeatable-read(可重复读):避免脏读和不可重复读,但是虚读有可能发生。(mysql默认隔离级别)
serializable(串行化):避免脏读,不可重复读,虚读。
从上到下级别越来越高,但是效率越来越低。
设置事务隔离级别:SET SESSION TRANSACTION ISOLATION LEVEL
这句话非常非常重要,许多人在后面用hibernate或者mybatis时候,sessionFactory为什么存在,就是因为这里事务的基本单位都是session。
事务的隔离级别都是以session,懂了没。