目的
由于经常会阅读关于C++的博客,譬如Meeting C++!的blogroll、 reddit的r/cpp等,面对很多信息来源,每天去对应站点读新博客是比较麻烦的事情,试过一些RSS阅读器,不太会用......那就自己动手制作一个吧。
思路
- 获取博客主页内容
- 取出文章标题及URL
- 移除旧文章
- 生成新文章列表
- 提示用户阅读
开发环境准备
- Node.js
- Visual Studio Code
起步
我们将建立一个命令行程序,在对应路径建立myreader目录,进入目录输入:
npm init
根据提示信息输入对应内容,生成package.json结果如下:
{
"name": "myreader",
"version": "0.0.1",
"description": "simple RSS-like reader",
"main": "./bin/AppEntry.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [
"blog",
"rss",
"reader"
],
"author": "[email protected]",
"license": "ISC"
}
在这里我将应用程序入口指定为./bin/AppEntry.js,测试内容如下:
#!/usr/bin/env node
console.log("我的RSS阅读器");
注意在Node.js的命令行程序,可执行程序第一行要这样写才能正确执行。
然后在myreader目录执行:
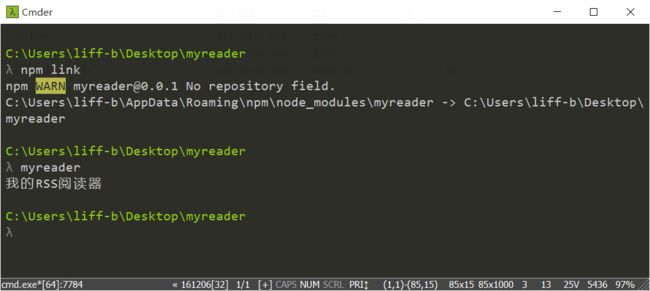
npm link命令相当于注册了myreader,之后就可以使用myreader来执行AppEntry.js了。
获取博客主页内容
使用request来获取博客主页内容,测试的博客为Fluent{C++}:
安装request库
npm install --save request
修改AppEntry.js
#!/usr/bin/env node
var request = require('request');
var domain = "http://www.fluentcpp.com/";
request(domain,function(error,response,body){
if(error){
console.log(error);
}
if(response.statusCode != 200){
console.log(response);
}
console.log(body);
});
运行myreader:
myreader > index.html
即可得到博客主页的内容。
取出文章的标题和URL
规律分析
打开Fluent{C++},使用Chrome的检查打开分析界面:

可以看到所有的文章都是用标题中,上一级为...
那么,我们可以取出所有的article,然后查找内容的class为entry-title的元素,然后再取出其中的a拿到标题和href属性。
如何实现
使用cheerio来对网页进行处理,cheerio可以采用jQuery的方式对HTML进行操作:
npm install --save cheerio
#!/usr/bin/env node
var request = require('request');
var cheerio = require('cheerio');
var domain = "http://www.fluentcpp.com/";
request(domain,function(error,response,body){
if(error){
console.log(error);
}
if(response.statusCode != 200){
console.log(response);
}
var $ = cheerio.load(body);
$('article').each(function(i,e){
var entry = $(e).find('.entry-title').find('a');
var article = {
title:entry.text(),
url:entry.attr('href')
};
console.log(article);
});
});
运行myreader结果如下:

封装成为Fetch.js
通过之前的方式,就可以获取博客主页上的文章信息了,将其封装成为Fetch.js。
博客的内容大致如此,都是获取文章列表,然后定位到标题,即可取出想要的信息,那么对于特定的博客主页,输入的信息为:
{
domain: 博客主页
articleFilter: 文章过滤
urlFilter: 标题过滤
}
Fetch.js实现如下:
var request = require('request');
var cheerio = require('cheerio');
function fetchArticles(input,callback){
request(input.domain,function(error,response,body){
if(error){
console.log(error);
}
if(response.statusCode != 200){
console.log(response);
}
var articles = [];
var $ = cheerio.load(body);
var urlFilters = input.urlFilter.split(" ");
$(input.articleFilter).each(function(i,e){
var entry = $(e);
urlFilters.forEach(function(item,index,array){
if(item)
entry = entry.find(item);
});
entry = entry.find('a');
var article = {
title:entry.text(),
url:entry.attr('href')
};
articles.push(article);
});
callback(articles);
});
};
exports.fetchArticles = fetchArticles;
此时的AppEntry.js为:
#!/usr/bin/env node
var fetch = require("./Fetch.js");
var input = {
domain:"http://www.fluentcpp.com/",
articleFilter:"article",
urlFilter:".entry-title"
};
fetch.fetchArticles(input,function(articles){
console.log(articles);
});
移除旧文章
最简单的实现就是记录每次获取到的博客站点最新的文章URL,当获取到文章列表数组时进行遍历,一旦碰到上一次的URL,则后续的文章都是旧文章。
简单起见,采用直接保存JSON对象的方式处理:
var jsonfile = require('jsonfile');
//读取JSON文件
function loadJSONFile(file){
if(!fs.existsSync(file))
return {};
return jsonfile.readFileSync(file);
};
//保存JSON文件
function saveJSONFile(file,json){
jsonfile.writeFileSync(file,json,{spaces:4});
};
对于结果的操作实现如下:
const fs = require('fs');
const path = require('path');
function result(location){
return {
lastFile:path.join(location,"./last.json"),//最新的文章文件位置
lastArticles:function(){
return loadJSONFile(this.lastFile);
},
lastArticle:function(domain){//查询某博客最新的文章
var vals = this.lastArticles();
if(!vals.hasOwnProperty(domain))
return "";
return vals[domain];
},
updateLastArticle:function(domain,url){//更新某博客最新的文章
var vals = this.lastArticles();
vals[domain] = url;
saveJSONFile(this.lastFile,vals);
return vals;
},
updateLastArticles:function(articles){//更新最新的文章
var vals = this.lastArticles();
articles.forEach(function(article,index,array){
vals[article.domain] = article.url;
});
saveJSONFile(this.lastFile,vals);
return vals;
}
}
};
移除旧文章操作实现如下:
//过滤掉旧文章
function removeOldArticles(last,articles){
var results = [];
articles.every(function(article,idx){
if(article.url === last)
return false;
results.push(article);
return true;
});
return results;
};
多博客站点设置
对于每个博客站点,只需要保存相应信息到配置,然后即可使用Fetch.js访问并得到文章列表,设置操作实现如下:
//配置文件的操作
function setting(location){
return {
file:path.join(location,'./setting.json'),
inputs:function(){ //获取博客源列表
var set = loadJSONFile(this.file);
if(set.hasOwnProperty('inputs'))
return set.inputs;
return {};
},
append:function(input){//追加新博客源
var result = loadJSONFile(this.file);
if(!result.hasOwnProperty('inputs'))
result.inputs = new Map();
result.inputs[input.domain] = input;
saveJSONFile(this.file,result);
return result.inputs;
}
}
};
整合操作
将设置、获取、移除旧文章操作进行整合后的AppEntry.js:
#!/usr/bin/env node
const path = require('path');
var result = require('../src/Result.js').result(__dirname);
var setting = require('../src/Setting.js').setting(__dirname);
var fetch = require('../src/Fetch.js');
var action = require('../src/action.js');//removeOldArticles在此实现
console.log('配置文件位于:'+setting.file);
var inputs = setting.inputs();
var results = [];
Object.keys(inputs).forEach(function(domain){
fetch.fetchArticles(inputs[domain],function(articles){
//得到文章列表并移除旧文章
var vals = action.removeOldArticles(result.lastArticle(domain),articles);
results.push({domain,results:vals});
if(results.length === Object.keys(inputs).length){//当所有博客源都遍历完成
console.log(results);//输出结果
}
});
});
通知用户
当获取到所有的新文章之后,需要告知用户有新文章可读及其入口,简单起见将新文章列表生成为HTML,然后弹出系统通知,当用户点击时打开该HTML页面。
生成HTML
function writeAsHTMLFile(file,articles){
var content = '\n';
articles.forEach(function(item,index,array){
item.results.forEach(function(article,idx,obj){
content+='\n';
content+=''+article.title+'\n';
content+=' \n';
});
});
content+='\n';
fs.writeFileSync(file,content);
};
弹出通知
这里使用node-notifier来弹出系统通知:
const notifier = require('node-notifier');
const path = require('path');
function fireNotify(NotifyInput){
notifier.notify({
title:NotifyInput.title,
message:NotifyInput.message,
icon:path.join(__dirname,NotifyInput.icon),
sound:true,
wait:true
});
notifier.on('click',NotifyInput.onClick? NotifyInput.onClick:function(object,options){});
notifier.on('timeout',NotifyInput.onTimeout? NotifyInput.onTimeout:function(object,options){});
};
打开HTML页面
使用open:
var open = require('open');
function notifyNewArticles(number,location){
fireNotify({
title:"新文章可读",
message:'有'+(number+1)+"篇新文章可读,点击查看.",
icon:'invalid.png',
onClick:function(object,option){
open("file:///"+location);
}
});
};
处理结果
当获取了每个博客站点的新文章列表后,还需要处理一下结果,然后用来刷新"最新的文章URL",实现如下:
function mergeArticles(articles){
var last = [];
var number = 0;
articles.forEach(function(item,index,array){
if(item.results.length >0){
last.push({
domain:item.domain,
url:item.results[0].url
});
number+=item.results.length;
}
});
return {
number:number, //新文章个数
last:last //每个站点最新的文章URL
};
};
流程整合
将原先的单纯输出结果到命令行替换成写入到HTML页面,并通知用户,点击打开页面:
if(results.length === Object.keys(inputs).length){
var val = action.mergeArticles(results);//处理结果
if(val.number > 0){
result.updateLastArticles(val.last);//刷新最新的文章URL
var location = path.join(__dirname,'./result.html');
writer.writeAsHTMLFile(location,results);//写入到HTML文件
notifier.notifyNewArticles(val.number,location);//通知新文章可读
}
}
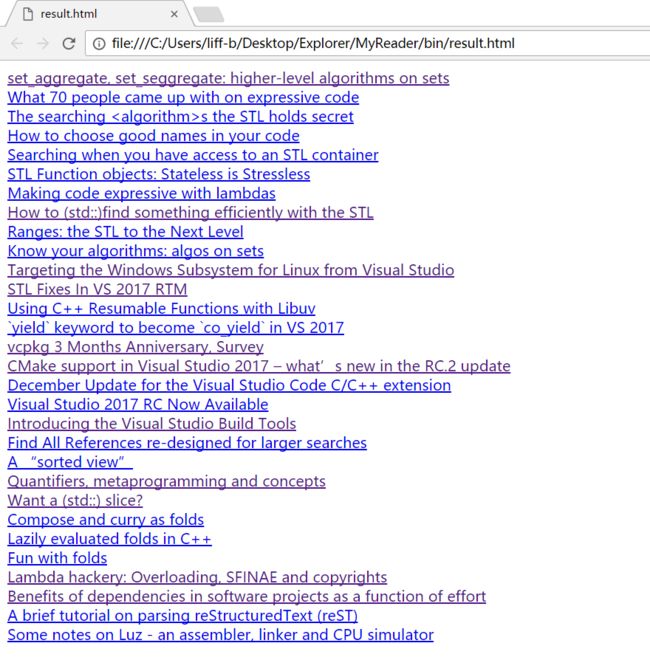
运行效果