泰坦尼克号生还率分析
数据来源 kaggle 数据集 → 共有 1309 名乘客数据,其中 891 是已知存活情况(train.csv)
剩下 418 则是需要进行分析预测的(test.csv)
字段意义:
- PassengerID:乘客编号
- Survived:存活情况(存活:1;死亡:0)
- Pclass:客舱等级
- Name:乘客姓名
- Sex:性别
- Age:年龄
- SibSp:同乘的兄弟姐妹/配偶数
- Parch:同乘的父母/小孩数
- Ticket:船票编号
- Fare:船票价格
- Cabin:客舱号

目的:
通过已知获救数据,预测乘客生存情况
1、整体来看,存活比例如何?
分析思路:
- 读取已知生存数据 train.csv
- 查看已知存活数据中,存活比例如何?
提示:
- 注意过程中筛选掉缺失值之后再分析
- 这里用 seaborn 制图辅助研究
存活比例为 38.38%

2、结合性别和年龄数据,分析幸存下来的人是那些人?
分析思路:
- 年龄数据的分布情况
- 男性和女性存活情况
- 老人和小孩存活情况
我们用柱形图和箱线图查看具体年龄数据分布情况。
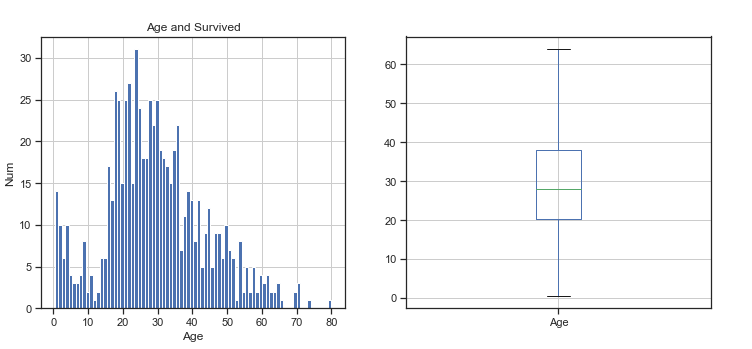
由柱形图和箱线图可得知,样本年龄数据分布在 18 - 30岁之间的人数比较多,同时小孩特别多,老人比较少。
总体年龄分布:去掉缺失值后样本有 714,平均年龄为 30岁,标准差 14岁,最小年龄 0.42,最大年龄 80
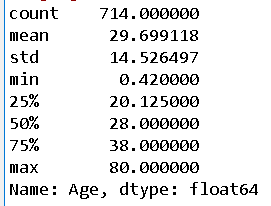
通过描述统计可得出,总体年龄分布:去掉缺失值后样本有 714,平均年龄为 30岁,标准差 14岁,最小年龄 0.42,最大年龄 80。
接下来我们对整个数据按性别进行分组,查看性别对生存率的影响。

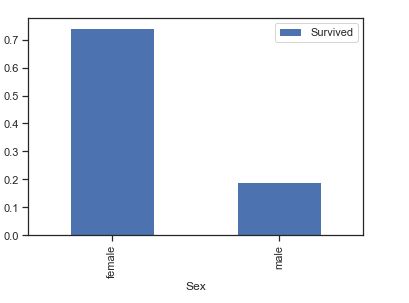
通过计算可得知,女性存活率74.20%,男性存活率18.89%,女性存活率明显高于男性。
接下来,我们再按照船舱等级分组,进行分析,看看船舱等级对生还率的影响。

按船舱等级和年龄划分(看蓝色部分存活者),一等船舱集中分布在 20 - 40岁,二等和三等不仅仅年龄分布在 20 - 40岁,还有许多低龄存活者;
按船舱等级和性别划分(看蓝色部分存活者),两者均有较低年龄的存活者,总体来说这次对女性和低龄人士,都有一定的照顾,存活率都比较高。
接下来按年龄划分绘制柱状图,看看每个年龄段的存活情况。

由图可知,灾难中,老人和小孩存活率较高,中间人数最多(年龄分布可以看出),存活率却比较低。
综上所诉,按年龄划分,老人和小孩的存活率较高;按性别划分,女性的存活率较高。
3、结合 SibSp、Parch 字段,研究亲人多少与存活的关系
分析思路:
- 有无兄弟姐妹/父母子女和存活与否的关系
- 亲戚多少与存活与否的关系

由上图所知,有兄弟姐妹、父母子女的生存率更大
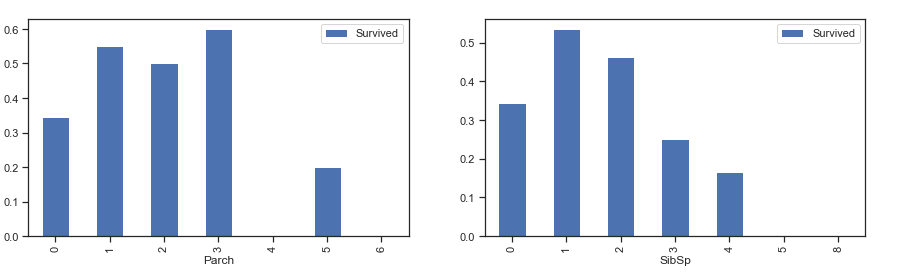
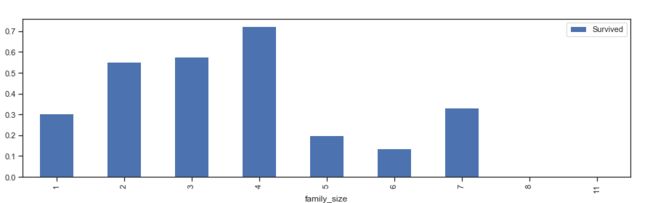
综上所示,独自一人的生存率较低,随着亲戚数量增加,生存率逐渐增加,超过 4 名后,生存率下降。
4、结合船票的费用情况,研究票价和存活与否的关系
分析思路:
- 票价分布和存活与否的关系
- 比较研究生还者和未生还者的票价情况

由上图所示,总体来说,票务价格比较平均,20英镑 一张,一等舱票价较高,平均 60 英镑,二等舱和三等舱票价都是在 25 英镑以下;人数集中在二三等舱,一等舱人数较少。
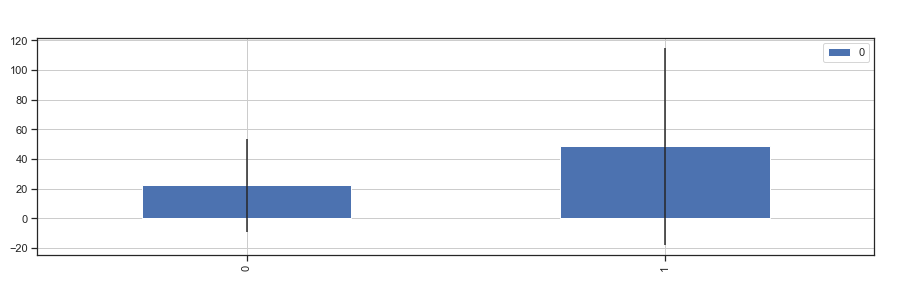
总体来看,生还者票价高于未生还者票价,一等舱存活率较高一点,二等舱和三等舱基数大,存活率不高。
接下来我们基于上述的特征,利用 KNN 分类模型,对结果进行预测。
5、利用 KNN 分类模型,对结果进行预测
分析思路:
- 模型训练字段:'Surivied','Pclass','Sex','Age','Fare','family_Size'
- 模型预测 test.csv 样本数据的生还率
提示:
- 训练数据集中,性别改为数字表示 → 1 代表男,0 代表女性
#去掉缺失值
knn_train = train_data[['Survived','Pclass','Sex','Age','Fare','family_size']].dropna()
knn_train['Sex'][knn_train['Sex'] == 'male'] = 1
knn_train['Sex'][knn_train['Sex'] == 'female'] = 0
test_data['family_size'] = test_data['Parch'] + test_data['SibSp'] + 1
knn_test = test_data[['Pclass','Sex','Age','Fare','family_size']].dropna()
knn_test['Sex'][knn_test['Sex'] == 'male'] = 1
knn_test['Sex'][knn_test['Sex'] == 'female'] = 0
from sklearn import neighbors
knn = neighbors.KNeighborsClassifier()
knn.fit(knn_train[['Pclass','Sex','Age','Fare','family_size']],knn_train['Survived'])
knn_test['predict'] = knn.predict(knn_test)
pre_survived = knn_test[knn_test['predict'] == 1].reset_index()
del pre_survived['index']