初始pandas
pandas 是一个能使数据分析变得更快更简单的高级数据结构和操作工具。
pandas是在numpy的基础上构建的,让以numpy为中心的应用变得更简单。
安装
我们可以通过pip来安装pandas
sudo pip install pandas
引入包
from pandas import Series,DataFrame
import pandas as pd
pandas的数据结构
pandas 有两个主要的数据结构:Series,DataFrame
Series 是一种类似于数组的对象,由一组数据以及一组与之相关的数据标签(索引)组成:
obj = Series([3,4,5,-4])
Series
Series的字符串表现形式:索引在左侧,值在右侧。如果我们没有手动指定索引,Series会默认创建从0到N-1的整数类型的索引。
可以通过.values和.index来获取数组表现形式和索引对象
obj.values
obj.index
指定索引:
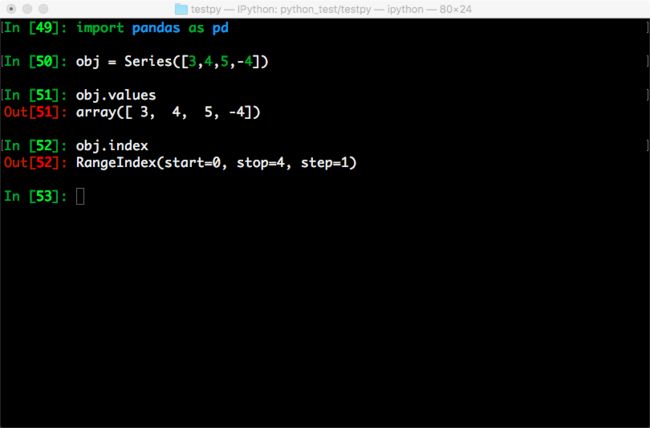
obj2 = Series([3,4,5,-4],index = ['a','b','c','d'])
obj2
obj2.index
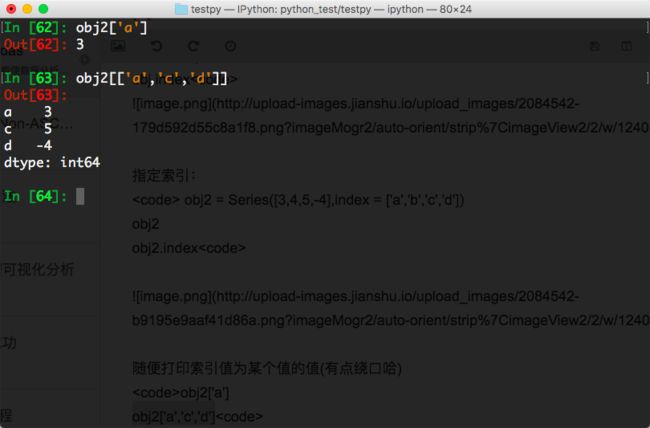
随便打印索引值为某个值的值(有点绕口哈)
obj2['a']
obj2[['a','c','d']]
注意这里是双中括号
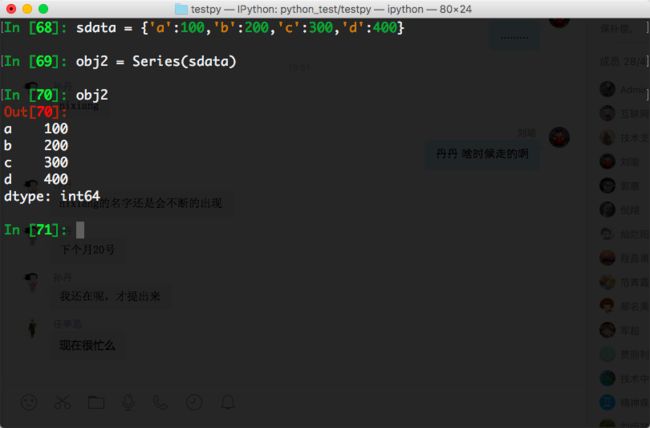
如果数据存在某python字典中,也可以通过字典创建Series:
In [68]: sdata = {'a':100,'b':200,'c':300,'d':400}
In [69]: obj2 = Series(sdata)
In [70]: obj2
Out[70]:
a 100
b 200
c 300
d 400
dtype: int64
如果只传入一个字典,且不指定索引:
In [71]: states = ['a','b','c','d']
In [72]: obj4 = Series(states)
In [73]: obj4
Out[73]:
0 a
1 b
2 c
3 d
dtype: object
如果只传入一个字典,且指定索引:
In [74]: obj5 = Series(index = states)
In [75]: obj5
Out[75]:
a NaN
b NaN
c NaN
d NaN
dtype: float64
如果只传入一个字典,指定值,指定索引:
In [76]: obj5 = Series(sdata,index = states)
In [77]: obj5
Out[77]:
a 100
b 200
c 300
d 400
dtype: int64
上面我们可以看到一个缺失字段的表示:NA,pandas的isnull和notnull函数可以用于检测缺失的数据:
In [79]: pd.isnull(obj5)
Out[79]:
a False
b False
c False
d False
dtype: bool
In [80]: pd.notnull(obj5)
Out[80]:
a True
b True
c True
d True
dtype: bool
Series也有此类的用法:
In [81]: obj4.isnull()
Out[81]:
0 False
1 False
2 False
3 False
dtype: bool
Series还有一个name的属性,是整个Series的name,不是某个值。如果不指定的话Series这个name属性就是缺省的,如果指定的话,这个name属性值就被填充:
In [87]: obj5
Out[87]:
a 100
b 200
c 300
d 400
dtype: int64
In [88]: obj5.name = 'Name'
In [89]: obj5
Out[89]:
a 100
b 200
c 300
d 400
Name: Name, dtype: int64
Series的索引还可以通过赋值的方式进行修改:
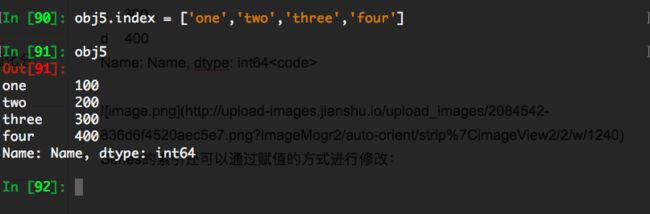
In [90]: obj5.index = ['one','two','three','four']
In [91]: obj5
Out[91]:
one 100
two 200
three 300
four 400
Name: Name, dtype: int64
DateFrame
DataFrame是一个表格型的数据结构,你可以理解为“二维表”,它含有一组有序的列,每列可以是不同的数据类型(数值、字符串、布尔类型)DataFrame既有行索引,也有列索引,它也可以被看为是Series组成的字典(Series共用一个索引)。
构建DataFrame
最常见的方法是传入一个等长列表或者Numpy数组组成的字典
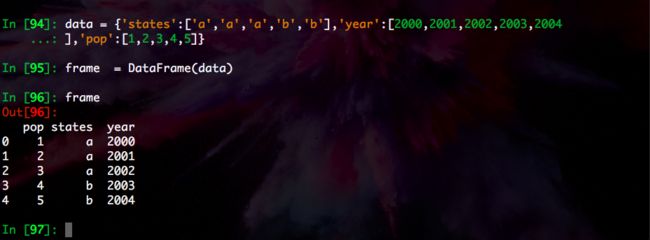
In [94]: data = {'states':['a','a','a','b','b'],'year':[2000,2001,2002,2003,2004
...: ],'pop':[1,2,3,4,5]}
In [95]: frame = DataFrame(data)
In [96]: frame
Out[96]:
pop states year
0 1 a 2000
1 2 a 2001
2 3 a 2002
3 4 b 2003
4 5 b 2004
如果我们制定列的顺序,那么DataFrame的列的顺序就会按照我们指定的顺序:
In [97]: frame = DataFrame(data,columns=['states','year','pop'])
In [98]: frame
Out[98]:
states year pop
0 a 2000 1
1 a 2001 2
2 a 2002 3
3 b 2003 4
4 b 2004 5

和Series一样,如果传入的列在数据中找到不到,就会产生NA:
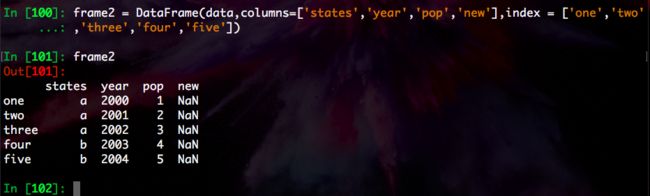
In [100]: frame2 = DataFrame(data,columns=['states','year','pop','new'],index = ['one','two'
...: ,'three','four','five'])
In [101]: frame2
Out[101]:
states year pop new
one a 2000 1 NaN
two a 2001 2 NaN
three a 2002 3 NaN
four b 2003 4 NaN
five b 2004 5 NaN
通过类似字典标记或者属性的方式,可以把DataFrame的一个列获取成Series
In [102]: frame2['states']
Out[102]:
one a
two a
three a
four b
five b
Name: states, dtype: object
In [103]: frame2.year
Out[103]:
one 2000
two 2001
three 2002
four 2003
five 2004
Name: year, dtype: int64

这里需要注意,获取到的Series的索引还是原来DataFrame的索引,并且连Name也已经设置好了。
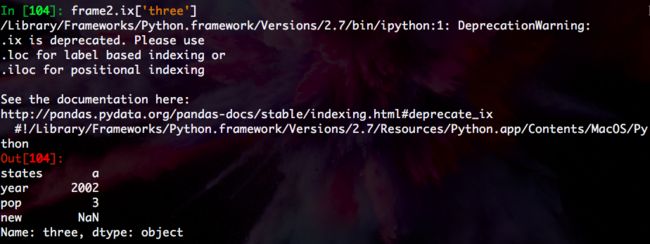
我们试一下获取DataFrame中的一行:
In [104]: frame2.ix['three']
Out[104]:
states a
year 2002
pop 3
new NaN
Name: three, dtype: object
这里Name被设置成DataFrame这一行的索引。
我们看到frame2的debt的列是值都是NA,我们可以通过赋值的方式给这一列进行赋值。
In [105]: frame2['debt'] = 13
In [106]: frame2
Out[106]:
states year pop new debt
one a 2000 1 NaN 13
two a 2001 2 NaN 13
three a 2002 3 NaN 13
four b 2003 4 NaN 13
five b 2004 5 NaN 13

再赋值一次:
In [107]: frame2['debt'] = np.arange(5.)
In [108]: frame2
Out[108]:
states year pop new debt
one a 2000 1 NaN 0.0
two a 2001 2 NaN 1.0
three a 2002 3 NaN 2.0
four b 2003 4 NaN 3.0
five b 2004 5 NaN 4.0

如果给列赋值,必须保持和DataFrame的长度是一致的,如果想要赋的值是一个Series,那么会精确的匹配索引,没有值的位置会被填充上NA
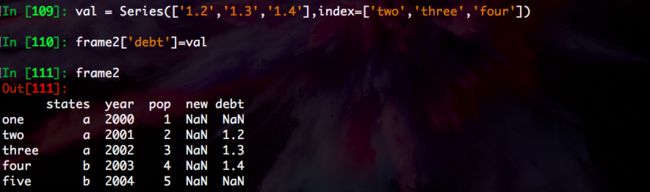
In [109]: val = Series(['1.2','1.3','1.4'],index=['two','three','four'])
In [110]: frame2['debt']=val
In [111]: frame2
Out[111]:
states year pop new debt
one a 2000 1 NaN NaN
two a 2001 2 NaN 1.2
three a 2002 3 NaN 1.3
four b 2003 4 NaN 1.4
five b 2004 5 NaN NaN
如何删除DateFrame中的一列:
In [112]: del frame2['new']
In [113]: frame2
Out[113]:
states year pop debt
one a 2000 1 NaN
two a 2001 2 1.2
three a 2002 3 1.3
four b 2003 4 1.4
five b 2004 5 NaN

需要注意的是:通过索引的方式返回的列只是相应数据的视图而已,因此,对返回的Series所做的任何操作都会反映到DataFrame上。通过Series的copy方法既可以显式的复制列。
另一种常见的形式 叫做"字典的字典",字典嵌套:
In [10]: pop ={'a':{1:1000,2:2000},'b':{3:3000,4:4000},'c':{5:5000,6:6000}}
In [11]: pop
Out[11]: {'a': {1: 1000, 2: 2000}, 'b': {3: 3000, 4: 4000}, 'c': {5: 5000, 6: 6000}}
把嵌套了字典的字典还给DataFrame的时候,会被解释成:外层的键作为列,内层的键作为行索引,
frame3 = pd.DataFrame(pop)
In [12]: frame3 = pd.DataFrame(pop)
In [12]: frame3
Out[13]:
a b c
1 1000.0 NaN NaN
2 2000.0 NaN NaN
3 NaN 3000.0 NaN
4 NaN 4000.0 NaN
5 NaN NaN 5000.0
6 NaN NaN 6000.0

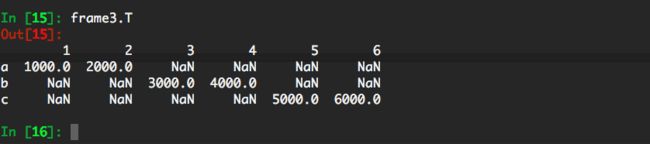
我们可以对结果进行转置:
In [15]: frame3.T
Out[15]:
1 2 3 4 5 6
a 1000.0 2000.0 NaN NaN NaN NaN
b NaN NaN 3000.0 4000.0 NaN NaN
c NaN NaN NaN NaN 5000.0 6000.0
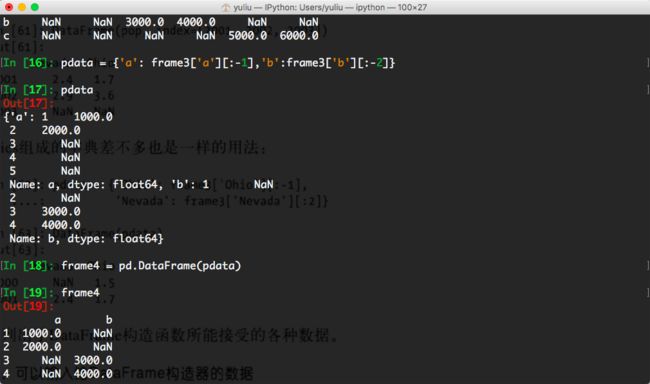
Series的字典也以相同的方式来处理:
In [16]: pdata = {'a': frame3['a'][:-1],'b':frame3['b'][:-2]}
In [17]: pdata
Out[17]:
{'a': 1 1000.0
2 2000.0
3 NaN
4 NaN
5 NaN
Name: a, dtype: float64, 'b': 1 NaN
2 NaN
3 3000.0
4 4000.0
Name: b, dtype: float64}
In [18]: frame4 = pd.DataFrame(pdata)
In [19]: frame4
Out[19]:
a b
1 1000.0 NaN
2 2000.0 NaN
3 NaN 3000.0
4 NaN 4000.0
可以输入给DataFrame构造器的数据如下:
- 二维ndarray
- 由数组、列表或者元祖组成的字典
- Numpy的结构化/记录数组
- 由Series组成的字典
- 由字典组成的字典
- 字典或者Serie的列表
- 由列表或者元祖组成的列表
- 另一个DataFrame
- Numpy的MaskedArray