Tesseract-OCR的简单使用与训练
最近看到某个网站提交数据要提交验证码,用tesseract自带的识别,

识别出来是什么鬼,0-9识别成了什么玩意!
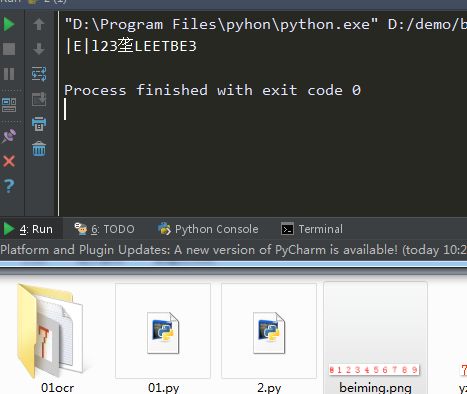
so决定自己训练下tesseract...
1.准备工作(安装工具环境)
1.下载安装tesseract-ocr-setup-3.02.02.exe安装包 http://www.pc0359.cn/downinfo/55218.html
2.安装jTessBoxEditor
下载jTessBoxEditor,地址https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/;解压后得到jTessBoxEditor,由于这是由Java开发的,所以我们应该确保在运行jTessBoxEditor前先安装JRE(Java Runtime Environment,Java运行环境)。
3.安装Java环境:http://mydown.yesky.com/pcsoft/33490441.html
2.准备训练图片,可以多张图片,我们可以用画图工具绘制样本文件,数量越多越好
准备图片如下

3.Merge样本文件
打开jTessBoxEditor,ctrl+m 选择所有样本图片,并将合并文件保存为 bm.font.exp0.tif

4.生成BOX文件
打开命令行并切换至bm.font.exp0.tif所在目录,

输入如下命令,生成文件名为bm.font.exp0.box
tesseract bm.font.exp0.tif bm.font.exp0 batch.nochop makebox
此时文件夹下会多出一个bm.font.exp0.box文件
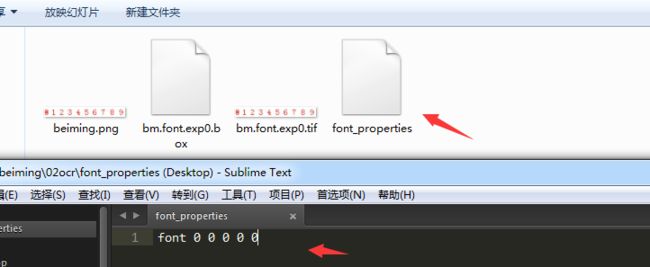
5.定义字符配置文件
在目标文件夹内生成一个名为font_properties的文本文件,内容为
font 0 0 0 0 0
【语法】:
fontname为字体名称,italic为斜体,bold为黑体字,fixed为默认字体,serif为衬线字体,fraktur德文黑字体,1和0代表有和无,精细区分时可使用,如果是txt文件记得把.txt后缀去掉。
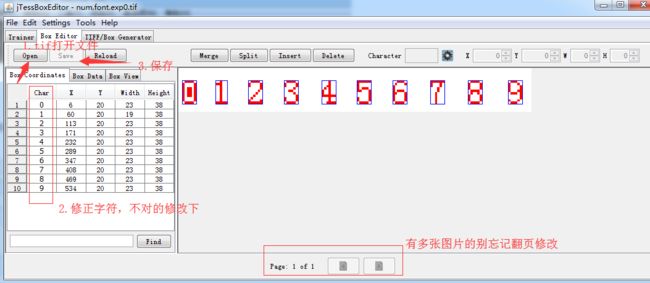
6.字符矫正
打开jTessBoxEditor,BOX Editor -> Open,打开bm.font.exp0.tif;
7.生成字符特征文件
tesseract.exe bm.font.exp0.tif bm.font.exp0 nobatch box.train
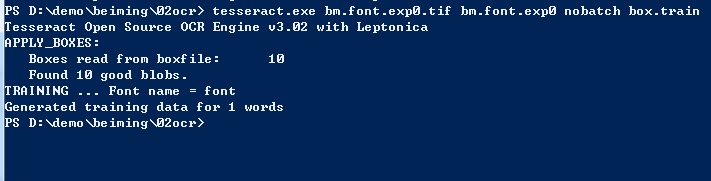
这一步将生成两个文件,bm.font.exp0.tr(特征文件)和bm.font.exp0.txt文件
8.计算字符集(unicharset)
unicharset_extractor.exe bm.font.exp0.box

这一步产生字符集文件unicharset
9.聚集字符特征(inttemp、pffmtable、normproto)
mftraining -F font_properties -U unicharset -O bm.unicharset bm.font.exp0.tr
根据上一步产生的字符集文件unicharset,来生成当前新语言的字符集文件mfunicharset。同时还会产生图形原型文件inttemp和每个字符所对应的字符特征数文件pffmtable。附带还会产生Microfeat文件,但是这个文件没啥用。
10.接下来产生字符形状正常化特征文件normproto
cntraining.exe bm.font.exp0.tr
11.重命名打包文件
将如下四个文件加上bm.前缀
normproto bm.normproto inttemp bm.inttemp pffmtable bm.pffmtable shapetable bm.shapetable

12.合并训练文件(*.traineddata)
combine_tessdata.exe bm.

生成bm.traineddata文件,

将这个文件复制到Tesseract-OCR\tessdata文件夹下然后用训练过的字库在识别下
tesseract beiming.png output_2 -l bm

识别完全正确,细心的人会发现,最后一句指令,我们使用了指令[-l bm]而不是[-l eng]。这说明,最后一次转换我们使用的是新生成的bm语言的匹配库而不是默认的eng语言匹配库
python pytesseract使用
import pytesseract
from PIL import Image
# pytesseract.pytesseract.tesseract_cmd='D:\Program Files\python\Tesseract-OCR\\tesseract.exe'
def getyzm():
image1 = Image.open('yzm.jpg')
w,h = image1.size
#创建新图片
image2 = Image.new("RGB",(w+10,h+6),(255,255,255))
#两张图片相加: 我这里的图片不是标准的图片格式所以需要盖在新图片上
image2.paste(image1,(5,3))
# image2.save("yzm.png")
result = pytesseract.image_to_string(image2,lang="num")
return result
print(getyzm())