下载缓存:假设我们对同一个网站进行了多次下载,在百万个网页的情况下是不明智的,所以我们需要缓存,下过一次的不再重复下载,这样我们能够节省很多时间
为链接爬虫添加缓存支持:
在下载之前进行判断,该链接是否含有缓存,只在没有缓存发生下载是触发限速功能,

完整代码地址
为 了支持缓存功能, 链接爬虫的代码也需要进行一些微调 , 包括添
加 cache 参数、 移除限速以及将 download 函数替换为新的类等, 如下面的
代码所示。
def link_crawler(seed_url, link_regex=None, delay=5, max_depth=-1, max_urls=-1, user_agent='wswp', proxies=None, num_retries=1,scrape_callback=None, cache=None):
'''crawl from the given seed URL following link matched by link_regex'''
crawl_quene = [seed_url]
seen = {seed_url: 0}
num_urls = 0
rp = get_robots(seed_url)
D = Downloader(delay=delay, user_agent=user_agent, proxies=proxies, num_retries=num_retries, cache=cache)
while crawl_quene:
url = crawl_quene.pop()
depth = seen[url]
if rp.can_fetch(user_agent, url):
html = D(url)
links = []
磁盘缓存
将下载到的网页存储到文件系统中,实现该功能,需要将URL安全的映射为跨平台的文件名
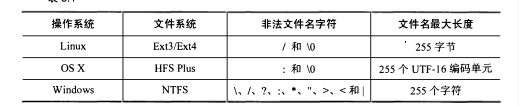
为了保证在不同的文件系统中文件路径都是安全,我们需要限制其只能包含数字字母和基本符号,并将其他字符转换为下划线,
代码实现:
import re
url = 'http://example.webscraping.com/default/view/Australia-1'
re.sub('[^/0-9a-zA-Z\-.,;_]', '_', url)
需要文件名及其父目录的长度不超过255个字符
filename = '/'.join(segment[:255] for segment in filename.split('/'))
还有一种边界情况,就是URL以斜杠结尾。这样分割URL后就会造成一个非法的文件名。例如:
- http://example.webscraping.com/index/
- http://example.webscraping.com/index/1
对于第一个URL可以在后面添加index.html作为文件名,所以可以把index作为目录名,1为子目录名,index.html为文件名
import urlparse
components=urlparse.urlsplit ('http://example.webscraping.com/index/')
print componts
print components.path
comonents = urlparse.urlsplit(url)
path = comonents.path
if not path:
path = '/index.html'
elif path.endswith('/'):
path += 'index.html'
filename = comonents.netloc+path+comonents.query
实现将URL到文件名的这些映射逻辑结合起来,
def url_to_path(self, url):
comonents = urlparse.urlsplit(url)
path = comonents.path
if not path:
path = '/index.html'
elif path.endswith('/'):
path += 'index.html'
filename = comonents.netloc+path+comonents.query
filename = re.sub('[^/0-9a-zA-z\-.]', '_', filename)
filename = '/'.join(segment[:255] for segment in filename.split('/'))
return os.path.join(self.cache_dir, filename)
然后在
url to path 方法中应用 了前面讨论的文件名 限制。 现在, 我们还缺少根
据文件名存取数据的方法, 下面的代码实现了这两个缺失的方法。
def __getitem__(self, url):
path = self.url_to_path(url)
if os.path.exists(path):
with open(path, 'rb') as fp:
data = fp.read()
if self.compress:
data = zlib.decompress(data)
result, timestamp = pickle.loads(data)
if self.has_expired(timestamp):
raise KeyError(url + 'has expired')
return result
else:
raise KeyError(url + 'doesnot exist')
def __setitem__(self, url, result):
path = self.url_to_path(url)
folder = os.path.dirname(path)
if not os.path.exists(folder):
os.makedirs(folder)
data = pickle.dumps((result, datetime.utcnow()))
if self.compress:
data = zlib.compress(data)
with open(path, 'wb') as fp:
fp.write(data)
通过测试发现有缓存(第二次)所需要的时间远远少于没有使用缓存(第一次)的时间
节省磁盘空间:
为了节省磁盘空间我们对下载得到的html进行压缩处理,使用zlib模块进行压缩
fp.write(zlib.compress(pickle.dumps(result)))
解压
return pickle.loads(zlib.decompress(fp.read()))
清理过期数据:
我们将为缓存数据添加过期时间 , 以便爬虫知道何时需要重新下载网页,。在构造方法中,我们使用timedelta对象将默认过期时间设置为30天,在set方法中把当前时间戳保存在序列化数据中,在get方法中对比当前时间和缓存时间,检查是否过期。完整代码
class DiskCache:
def __init__(self, cache_dir='cache', expires=timedelta(days=30), compress=True):
self.cache_dir = cache_dir
self.expires = expires
self.compress = compress
def __getitem__(self, url):
path = self.url_to_path(url)
if os.path.exists(path):
with open(path, 'rb') as fp:
data = fp.read()
if self.compress:
data = zlib.decompress(data)
result, timestamp = pickle.loads(data)
if self.has_expired(timestamp):
raise KeyError(url + 'has expired')
return result
else:
raise KeyError(url + 'doesnot exist')
def __setitem__(self, url, result):
path = self.url_to_path(url)
folder = os.path.dirname(path)
if not os.path.exists(folder):
os.makedirs(folder)
data = pickle.dumps((result, datetime.utcnow()))
if self.compress:
data = zlib.compress(data)
with open(path, 'wb') as fp:
fp.write(data)
def __delitem__(self, url):
path = self._key_path(url)
try:
os.remove(path)
os.removedirs(os.path.dirname(path))
except OSError:
pass
def url_to_path(self, url):
comonents = urlparse.urlsplit(url)
path = comonents.path
if not path:
path = '/index.html'
elif path.endswith('/'):
path += 'index.html'
filename = comonents.netloc+path+comonents.query
filename = re.sub('[^/0-9a-zA-z\-.]', '_', filename)
filename = '/'.join(segment[:255] for segment in filename.split('/'))
return os.path.join(self.cache_dir, filename)
def has_expired(self, timestamp):
return datetime.utcnow() > timestamp+self.expires
def clear(self):
if os.path.exists(self.cache_dir):
shutil.rmtree(self.cache_dir)
if __name__ == '__main__': link_crawler('http://example.webscraping.com/', '/(index|view)', cache=DiskCache())
用磁盘缓存的缺点
由于受制于文件系统的限制,之前我们将URL映射为安全文件名,然而这样又会引发一些问题:- 有些URL会被映射为相同的文件名。比如URL:.../count.asp?a+b
,.../count.asp?a*b
。- URL截断255个字符的文件名也可能相同。因为URL可以超过2000下字符。
使用URL哈希值为文件名可以带来一定的改善。这样也有一些问题:- 每个卷和每个目录下的文件数量是有限制的。FAT32文件系统每个目录的最大文件数65535,但可以分割到不同目录下。- 文件系统可存储的文件总数也是有限的。ext4分区目前支持略多于1500万个文件,而一个大型网站往往拥有超过1亿个网页。
要想避免这些问题,我们需要把多个缓存网页合并到一个文件中,并使用类似B+树的算法进行索引。但我们不会自己实现这种算法,而是在下一节中介绍已实现这类算法的数据库。