谷歌开源LaserTagger,直击seq2seq效率低、推理慢、控制差3大缺陷
雷锋网 AI 开发者按:目前,在序列到序列( seq2seq )的自然语言生成任务中,主流预训练模型仍然面临一些重大缺陷,例如:生成输出与输入文本之间长度匹配问题、需要大量训练数据才能实现较高性能、推断速度慢等。
因此,Google 提出了一种新型的文本生成模型 LaserTagger,该模型旨在解决 seq2seq 模型运行过程中的上述缺陷,可以预测将将源文本转换为目标文本的一系列生成操作。Google 发布了相关文章介绍了这一开源文本生成模型,雷锋网 AI 开发者内容整理编译如下。

开发背景
序列到序列(seq2seq,https://en.wikipedia.org/wiki/Seq2seq)模型最初由软件⼯程师 Eric Malmi 和 Sebastian Krause 开发,这一模型一经推出后,为机器翻译领域带来了巨大的技术革新,并成为了各种⽂本⽣成任务(如摘要生成、句⼦融合和语法错误纠正)的主流模型。
同时,结合模型架构(例如,Transformer,https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html)的改进,以及通过⽆监督的预训练方法使用⼤量无标注⽂本的能⼒,使得近年来神经⽹络⽅法获得了质的提升。
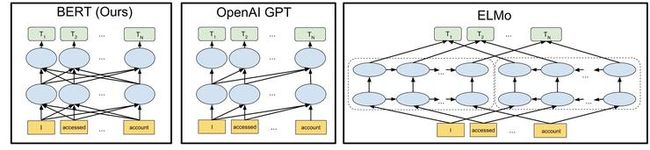
文本生成神经网络架构发展;其中,BERT 是深双向的,OpenAI GPT 是单向的,ELMo 是浅双向的
但根据实际使用情况,将 seq2seq 模型⽤于⽂本⽣成也有一些实质性的缺陷,例如:⽣成输⼊⽂本不⽀持的输出(称为幻觉,hallucination)、需要⼤量的训练数据才能到达很好的效果;此外,seq2seq 模型通常需要逐字⽣成输出,因此其推断时间较长。
近日,Google 的《Encode, Tag, Realize: High-Precision Text Editing》(https://ai.google/research/pubs/pub48542/)一文介绍了⼀种新颖的、开源的⽂本⽣成模型,旨在专⻔解决上述三个缺陷。由于该模型的速度快、精度高,因此该模型名为 LaserTagger。
该模型的核心思想在于:不从头开始⽣成输出⽂本,⽽是通过使⽤预测的编辑操作标注单词来⽣成输出;然后在单独的实现步骤中将这些单词应⽤于输⼊单词。这是处理⽂本⽣成的⼀种不太容易出错的⽅法,而且它可以通过更易于训练和更快执⾏的模型架构来处理文本。

《Encode, Tag, Realize: High-Precision Text Editing》论文
LaserTagger 的设计和功能
许多⽂本⽣成任务的显着特征是输⼊和输出之间经常存在⾼度重叠。例如:在检测和纠正语法错误、或者是在融合句⼦时,⼤多数输⼊⽂本可以保持不变,并且仅⼀⼩部分单词需要修改。
因此,LaserTagger 会产⽣⼀系列的编辑操作,⽽不是实际的单词。我们使⽤的四种编辑操作类型是: Keep(将单词复制到输出中),Delete(删除单词)和 Keep-AddX / Delete-AddX(添加短语 X)标注的单词之前,并可以选择删除标注的单词)。
下图说明了此过程,该图显示了 LaserTagger 在句⼦融合中的应⽤:

LaserTagger 适⽤于句⼦融合。预测的编辑操作对应于删除「.Turing」,然后替换为「and he」,注意输⼊和输出⽂本之间的⾼度重叠
所有添加的短语均来⾃受限制的词汇表。该词汇表是⼀个优化过程的结果,该优化过程具有两个⽬标:
(1)最⼩化词汇表的⼤⼩;
(2)最⼤化训练示例的数量;
其中添加到⽬标⽂本的唯⼀必要单词仅来⾃词汇表,短语词汇量受限制会使输出决策的空间变⼩,并防⽌模型添加任意词,从⽽减轻了「幻觉」问题。
输⼊和输出⽂本的⾼重叠特性也可以得到⼀个推论,即:所需的修改往往是局部的并且彼此独⽴。这意味着编辑操作可以⾼精度地并⾏进⾏预测,与顺序执⾏预测的⾃回归 seq2seq 模型相⽐,可以显着提⾼端到端的速度。
实验结果与结论
研究人员在实验中对 LaserTagger 实现的四个文本生成任务进行了评估,四个任务分别为:句⼦融合、拆分和改述、抽象总结和语法纠正。
在所有任务中,LaserTagger 的性能与使⽤⼤量训练示例的基于 BERT 的强⼤seq2seq 基线相当;并且在训练示例数量有限时,其结果明显优于该基线。
下图显示了 WikiSplit 数据集上的结果,其具体任务是将⼀个⻓句⼦改写为两个连贯的短句⼦:
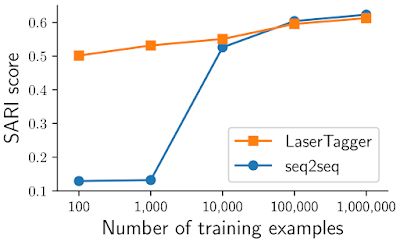
当在 100 万个示例的完整数据集上训练模型时,LaserTagger 和基于 BERT 的 seq2seq 基线模型均具有可⽐的性能,但是在 10,000 个或更少示例的⼦样本上进⾏训练时,LaserTagger 明显优于基线模型(SARI 得分越⾼越好)
LaserTagger 的主要优点
根据实验结果,研究人员将 LaserTagger 与传统的 seq2seq⽅法相⽐,总结出该新型模型具有以下优点:
-
可控性强 通过控制输出短语词汇(也可以⼿动编辑或整理),LaserTagger ⽐ seq2seq 基线模型不易产⽣幻觉。
-
推理速度快 LaserTagger 计算预测的速度⽐seq2seq 基线模型快 100 倍,使其适⽤于实时应⽤。
-
数据效率高 即使仅使⽤⼏百或⼏千个训练示例进⾏训练,LaserTagger 也可以产⽣合理的输出。在实验中,seq2seq 基线模型需要成千上万个示例才能获得可比拟的性能。
由此可见,LaserTagger 的优势在⼤规模应⽤时变得更加明显。研究人员表示:通过减少响应的⻓度并减少重复性可以用于改进某些服务中语⾳应答格式。
而较⾼的推理速度使该模型可以插⼊现有技术堆栈中,并且不会在⽤户端增加任何明显的延迟;除此之外,改进的数据效率可以收集多种语⾔的训练数据,从⽽使来⾃不同语⾔背景的⽤户受益。

图片来源:网络
原文链接:
https://ai.googleblog.com/2020/01/encode-tag-and-realize-controllable-and.html
Github 地址:
https://github.com/google-research/lasertagger
雷锋网(公众号:雷锋网) AI 开发者