1、快排空间
由于快排是递归的,需要借助一个递归工作栈来保存每一层递归调用的必要信息,其容量与最大深度一致。最好的情况为O(ceil( log2(n+1) )),最坏的情况为O(n),平均为O(log2(n))
2、两个单向链表,判断它们是否相关,若相关,找出其公共节点
1)没有环,是Y型,可通过O(m+n),来求出其公共交点。
2)双环,只要两链表存在交点,则其链尾一定是相同的,而环只出现在链尾,所以可以断定:有交点且有环,则一定是双环。可以用求环路口的算法求出任意一链表环的入口,即为交点。
3、二叉树与度为2的树间的区别
1)度为2的树至少有3个节点,二叉树可谓空;
2)度为2的树只有一个孩子时,不分左右,而二叉树是必须分左右孩子的。
注意:
1)树的节点数等于所有节点的度数总和加1;
2)深度为k的完全二叉树至少有2(k-1)个节点,至多有(2k)-1个节点。
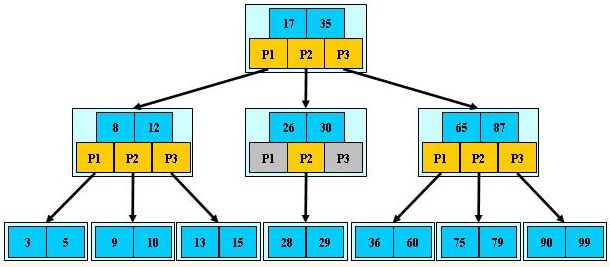
4、B-树
B-树是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子,且M>2;
2.根结点的儿子数为[2, M],或者根节点为一片树叶;
3.除根结点以外的非叶子结点的儿子数为[ceil(M/2), M];
4.每个结点存放至少ceil(M/2)-1和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M]指定子节点范围。
8.所有叶子结点位于同一层;
5、并查集
并查集是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。常常在使用中以森林来表示,进行快速归整。并查集保持一组不想交的动态集合,每个集合通过一个代表来识别,代表即集合中的某个成员。在某些应用中,代表迭代取任意,或最小值。
Make_Set(x):
建立一个新的集合,其唯一成员就是x,因此这个集合的代表也是x,并查集要求各集合是不相交的,因此要求x没有在其他集合中出现过。
Find_Set(x):
返回能代表x所在集合的节点,通常返回x所在集合的根节点。有递归和非递归两种方法。
Union(x, y):
将包含x,y的动态集合合并为一个新的集合。合并两个集合的关键是找到两个集合的根节点,如果两个根节点相同则不用合并;如果不同,则需要合并。
6、表查询
对于查找表的一般操作包括四种:查询特定元素,检索满足条件的元素,插入元素,删除元素。只涉及前两项操作的表称为静态查找表,需要动态修改的表称为动态查找表。
适合静态查找表的查找方法有:顺序查找,折半查找,散列查找;
适合动态查找表的查找方法有:二叉排序树的查找,散列查找。
7、哈希表
哈希表又称为散列表,它基于快速存取的角度设计,典型的“空间换时间”做法。可直接寻址,可在O(1)的时间内访问数组的任意元素。
哈希函数应尽量减少冲突关键字的出现(同义词),处理好冲突。
哈希函数是一种压缩映射,使得散列值的空间,通常远小于输入空间,不同的输入可能散列成相同的输出,而不可能从散列值唯一确定输入值,是一种消息摘要算法,不是加密算法,不具有可逆性,是加密算法的重要构成部分。MD4,MD5,SHA-1。
8、处理哈希冲突的方法:
1)链地址法
2)开放地址法(线性,二次,伪随机探测法)
3)再散列法
4)建立公共溢出区
其中开放定址法需要定期维护,只能进行逻辑删除。计算查找成功平均查找长度ASL,是对非空元素而言的,计算失败查找的平均长度ASL则针对表长。
9、一致性哈希
一致性哈希算法是一种哈希算法,在添加或移出一个节点时,它尽可能小地改变已存在key的映射关系。基本思路是使用相同的哈希算法,将数据和节点都映射到环形哈希空间。
10、BloomFilter
可视为Bitmap的扩展,与hash函数结合使用:
插入时,将元素按照K个hash函数计算出的位全部置1;
查询时,如果k个hash函数的结果都是1则认为存在该元素。
BloomFilter存在一定的误判风险,但是通过极少错误换取了存储空间的极大节省。
11、海量排序
我们一般提到的排序都是指内部排序,比如快排,归并排序。所谓内部排序就是可以在内存中完成的排序,但对大数据集来说,内存时远不够的,这时就涉及到外部排序了。
外部排序指的是大文件的排序,即待排序的记录存储在外部存储器上,待排序的文件无法一次性装入内存,需要在内存和外存之间进行多次数据交换,以达到整体排序的目的。
最常用的是多路归并算法,为降低每个记录的比较次数,引入“败者树”,可以视为一颗完全二叉树。每个结点存放各段在归并过程中的记录,内部结点用来记忆左右子树的“失败者”,而让胜利者继续比较,一直到根结点,如果比较的两个数大为失败,小为胜利,则根指向最小树。
12、算法的五个特性
1)有穷性: 一个算法必须保证执行有限步之后结束;
2)确切性: 算法的每一步骤必须有确切的定义;
3)输入:一个算法有0个或多个输入,以刻画运算对象的初始情况,所谓0个输入是指算法本身定除了初始条件;
4)输出:一个算法有一个或多个输出,以反映对输入数据加工后的结果。没有输出的算法是毫无意义的;
5)可行性: 算法原则上能够精确地运行,而且人们用笔和纸做有限次运算后即可完成